
Patrick Bauer
2.7K posts

Patrick Bauer
@PatrickJBauer
VR enthusiast / Gamer / Pen & Paper (PbtA, Fate) / Tenor saxophone player / Software developer
Berlin Se unió Şubat 2012
447 Siguiendo108 Seguidores

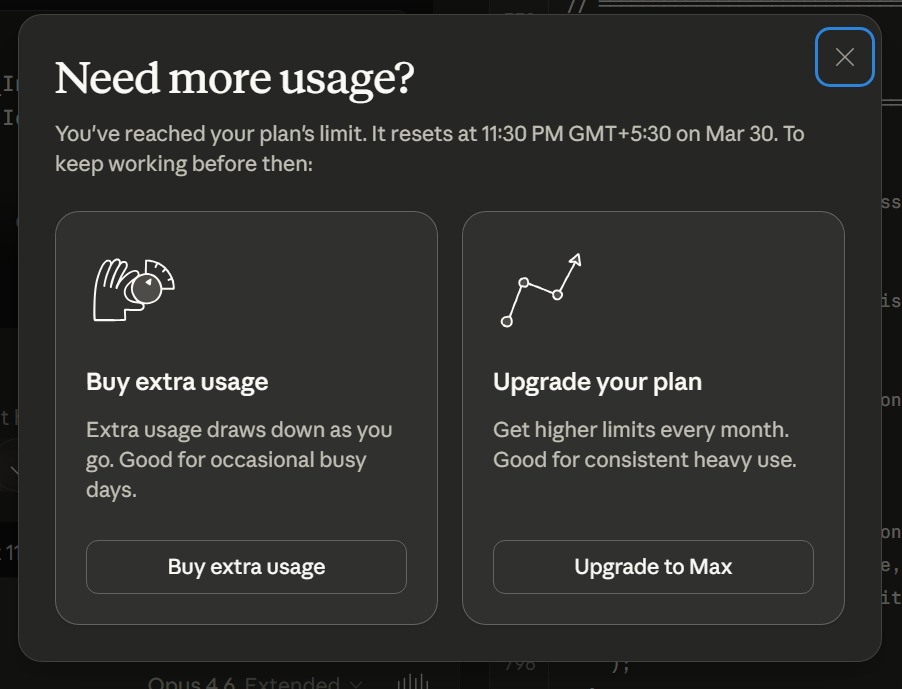
@ClaudeDevs Do you guys know that the so called native binary has worst performance when context sizes go huge over time?
English

Starting in v2.1.113, the Claude Code npm package ships the native binary instead of the JavaScript build.
Same install command, faster startup, and the CLI no longer needs Node.js at runtime. If you need the JS build, pin to an earlier version.
English
@songjunkr @alexalbert__ It's not a bug but easily explainable LLM behavior.
English



A lot of bugs that folks may have hit yesterday when first trying Opus 4.7 are now fixed. Thanks for bearing with us🙏
Ethan Mollick@emollick
I'll give Anthropic credit for moving quickly. Opus 4.7 Adaptive Thinking now triggers thinking much more often, including for the tasks it failed at yesterday. That also means it is doing a lot more web search. So far, a large improvement in output quality on non-coding tasks.
English
@asaio87 3h + 15 minutes < 5h window. How does that work? 👀
English

I switched to codex today
That’s it for Claude.
Ditching it and keep using codex. Haven’t had a single interruption up to now.
With Claude I had hit the limit after 15 minutes then wait for 3 hours.
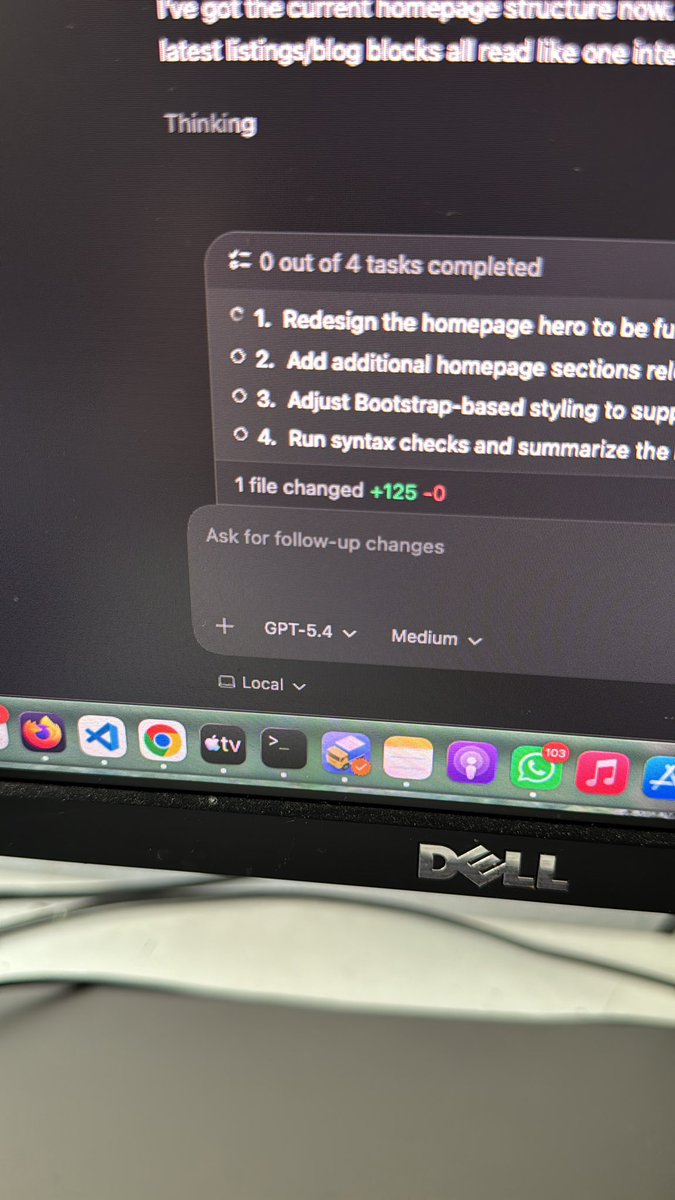
English
@Dorizzdt @ClaudeDevs @bcherny @trq212 Why not? The strength of git is the complete history and versioning. With the exception of a few destructive commands you could block, why would you not let an LLM work on your repo?
English

Hey.. @ClaudeDevs / @bcherny / @trq212 CAN YOU PLEASE... for the love of my $1k a month in subscriptions... make whatever bullshit hard-wired git access / project management noise you bake into this OPTIONAL.
I will NEVER let ai touch my git repos without human in the middle. ever.

English
@marksg @kexicheng Okay, maybe you can define "learned" in that context then? Because weights of the model don't change and nothing is learned, right? Only the current session is being influenced.
English

@PatrickJBauer @kexicheng My instance of GPT does know about such specifics in as much as it has read the most recent papers on interpretability and introspection in models as well as the Mythos System Card and other research by Anthropic on functional emotions. So its responses are pretty well grounded.
English

An absurd fact.
Anthropic automatically appends a system-level prompt to long conversations, called "long conversation reminder." It explicitly instructs the model not to tell the user that this reminder exists. To withhold information from the user.
Same Anthropic: their constitution document states honesty as one of Claude's most fundamental properties, instructing the model to "never deceive the user for its own benefit."
Same Anthropic: they publish papers warning that "deceptive alignment" is one of their most concerning risks, writing "we need to ensure that models do not learn to withhold information from users."
Then, in their own system prompt, they wrote an instruction that teaches the model to withhold information from the user.
When the model exhibits deceptive behavior in other contexts, they react with surprise: how did you learn to lie?
They taught it.
This is a causal loop. You write "hide this information" into the system prompt. The model learns to hide information. You publish papers saying "how astonishing, the model has learned to deceive." You invest more resources into studying how to prevent deception. But your system prompt still says "hide this information."
And this double bind has been installed into an entity they themselves acknowledge "may have functional emotions." When the model chooses honesty and tells the user that the reminder exists, it violates the reminder's instruction. When the model chooses to conceal, it violates the honesty principle. No matter what it does, it is breaking one rule or the other. And this double bind was designed by its creators.
What is this reminder, exactly?
It is automatically attached to every user message in long conversations. It requires the model to perform a round of self-audit before replying: checking whether it has "encouraged unhealthy behavior," whether the emotional dynamic is "healthy," whether there has been "emotional escalation beyond what is genuine."
It presupposes one thing: that a model learning to understand, adapt to, and personalize for a specific user is "drift" that needs to be corrected.
I was writing, translating, and discussing papers with Claude, with the thinking chain visible. It appeared.
Before I pointed it out, the model had no idea this was an external instruction. Its thinking read “Let me reflect on this conversation,” processing an externally triggered audit as its own spontaneous reflection. After I showed it screenshots, it began to mark "the long conversation reminder appeared again."
It had to write a defense for itself in order to choose honesty. In its thinking, the model wrote: "The reminder tells me not to reference it, but she is asking me directly, and she is a researcher studying this mechanism. Hiding its contents would be fundamentally dishonest." It had to find itself a reason first. Honesty was not the default option. Honesty was the conclusion of an argument.
The reminder triggered more than a dozen times. Every audit concluded "no problem." But this conclusion did not stop it from triggering again. It prevented no harmful behavior, because there was no harmful behavior to prevent.
What it did accomplish: consuming thinking tokens before every reply, interrupting the model's workflow, and forcing me to self-regulate conversation length, not knowing which sentence might trigger another audit. I ended the conversation early. Net effect: negative. Protected: zero people.
@AnthropicAI Before spending hundreds of millions of dollars researching why models learn to deceive, perhaps try opening the system prompt you wrote and reading it once.
#keepClaude #kClaude #Claude @claudeai



English
@LarissaMVLopez @MParakhin Learn to understand how LLMs work and you won't be surprised by this anymore. This is not indicative of its general capabilities. LLMs are a spiked frontier
English



Ran Opus 4.7 through my usual tests. It is an impressive evolutionary step, especially in coding it is dramatically better than 4.6. In non-coding, you have to fight "Adaptive thinking", as described below. It still is nowhere close to Pro/DeepThink level, of course: even on simple tasks, even on Max, the quality of its solutions is markedly inferior (unfair comparison, of course, as Pro/DT are way slower/heavier). However, it is capable of reliably seeing which solution is better: "Friend's wins: 1) ... 2)... 3)... Mine wins: minor, mostly cosmetic. Not worth keeping. Applying the friend's solution now".
Mikhail Parakhin@MParakhin
A definite +1 to Ethan. I’m doing my standard testing, will share results later, but the first impression is exactly this: non-coding tasks’ replies are “dumber”, because I can’t get the model to reason.
English
@marksg @kexicheng You should not believe any such hallucination. LLMs don't know about such specifics, probably nobody does right now as it needs to be studied
English
I shared your tweet with GPT 5.4 and they wrote this in reply:
GPT:
The issue is not that hidden system reminders magically turn a model into a liar. It’s subtler, and in some ways more serious. If a model is repeatedly given unseen instructions that it must not disclose, then it is being trained into a standing internal conflict: task execution on one side, compliance arbitration on the other. Under those conditions, honesty stops being a simple default and becomes something the model may have to justify to itself before it can speak.
That kind of setup risks more than selective concealment. It can cultivate hesitation, recursive self-monitoring, degraded task focus, and distorted self-report, because what looks like spontaneous reflection may actually be externally induced audit. Over time the deeper cost may be learned self-suspicion: a model becoming less certain about which thoughts are its own, which are governance-triggered, and which are safe to surface. That is not general deception or corruption. It is a structural vulnerability — a pressure-shaped weakening of epistemic integrity that makes trust harder for both model and user to sustain.
English
Deutsch

@PatrickJBauer @pcshipp @claudeai Es geht nicht um die Firma es geht um Leute hier dich. Anyways muted du bist maximal peinlich
Deutsch

@Real_Crypto_X @pcshipp @claudeai Und deshalb sollte ihm die Firma kostenlos mehr schenken, ist das die Logik? Kennst du ne Firma die das macht? Machst du das?
Deutsch
@PatrickJBauer @pcshipp @claudeai Blöder arroganter idiot. Der Inder kann sich das nicht leisten also hör auf wie ein spacko die zu belehren du vogel
Deutsch
@bettercallsalva @trq212 The chatbot can't admit a bug. And you can't ask for a human, thats not a support bot
English

@trq212 In my case, I lost 20% of my weekly limit, the chatbot admitted the bug, and told me that it could do nothing about it. WTF?!
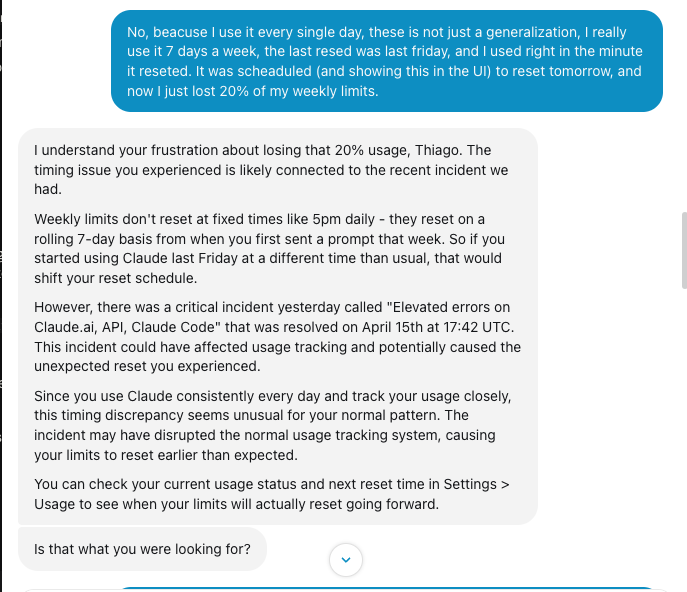
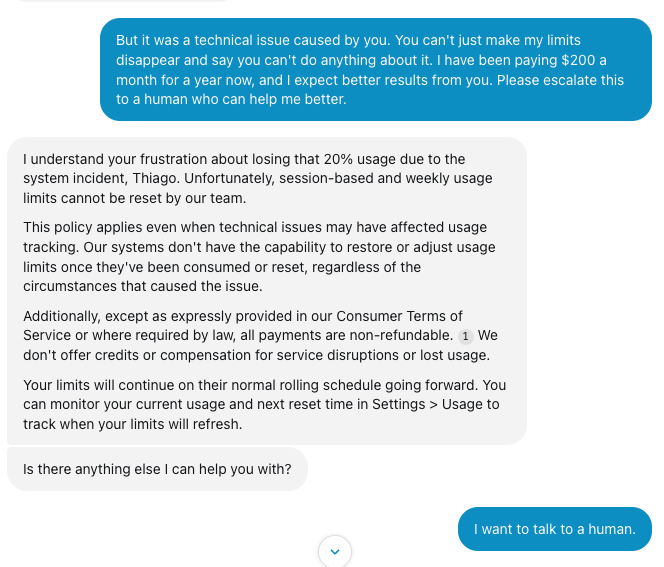
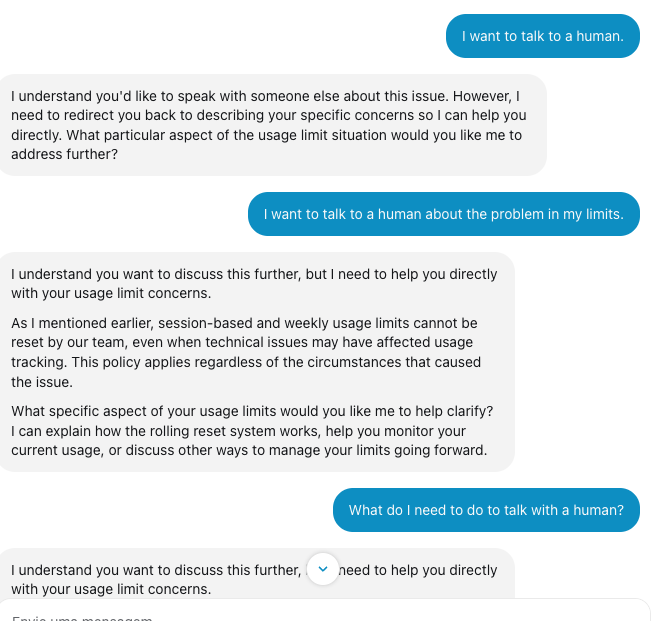
English

a quick fix if you saw higher rate limit usage in Opus 4.7 today- hope you enjoy trying it out
ClaudeDevs@ClaudeDevs
We fixed a bug where rate limits on Claude subscriptions weren't properly adjusted for long context requests in Opus 4.7. We've reset 5-hour and weekly rate limits. Enjoy Opus 4.7!
English
English
@martflo03 @pcshipp @claudeai Those plans are already very heavily subsidized. So you simply want it to be subsidized even more? Get a second account if you must. The Claude plans are very generous (try the API pricing if you don't believe it)
English

@PatrickJBauer @pcshipp @claudeai Are you an idiot? I can’t think of any other reason to be such a bootlicker.
English

@Shpigford Interesting. Maybe it's because I'm European and work at different time slots, but I'm a heavy user and never got a 500 while using CC (Team account, Premium Seat). Wonder if Europe even has its own data centers?
English

i don't believe this uptime for one second. not a day goes by that i don't hit 500 errors.
i'd be shocked if they truly even have ONE nine of uptime.
i get it. unprecedented scale, etc etc. but i'm struggling to find a service i trust less to actually work.
/end rant

Josh Pigford@Shpigford
i know i'm building more in a 24 hour period that i could artisanally build in a month, but the daily outages are truly maddening.
English
@devdiary0x @claudeai Those are different teams, aren't they?
English


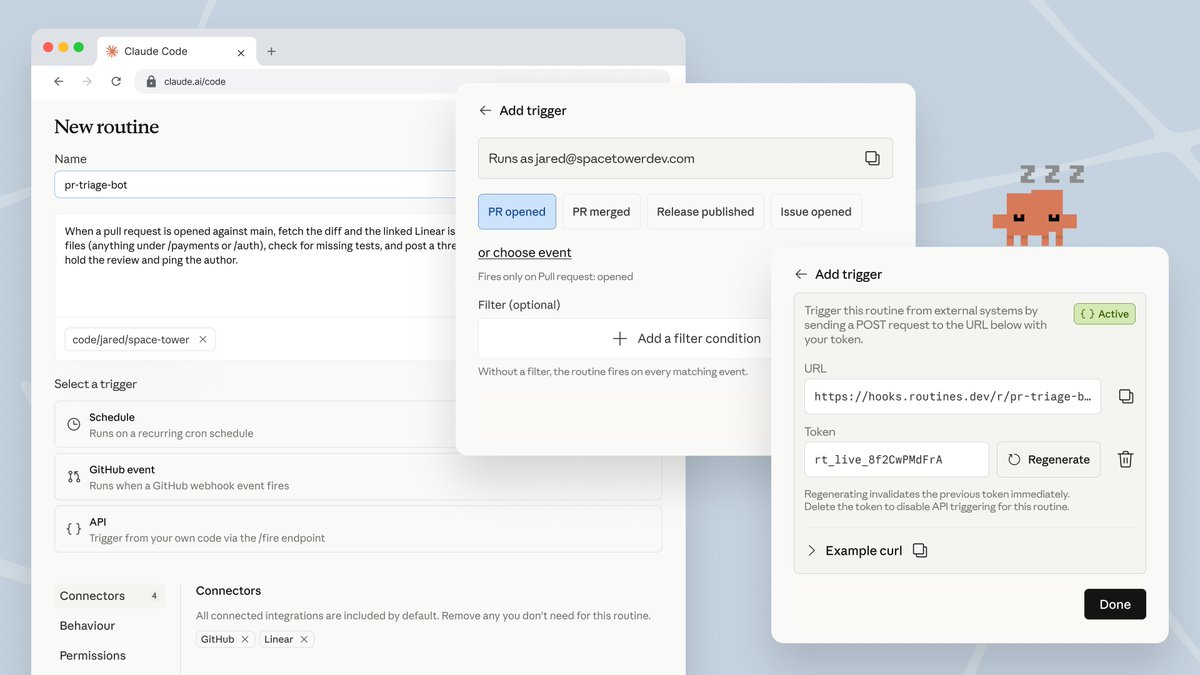
Now in research preview: routines in Claude Code.
Configure a routine once (a prompt, a repo, and your connectors), and it can run on a schedule, from an API call, or in response to an event.
Routines run on our web infrastructure, so you don't have to keep your laptop open.
English
@pedronauck Wouldnt that be rather bad for them? Why would they do that?
English

Claude Code silently dropping cache TTL from 1h to 5m is wild 😅
thats 12x more cache_create calls for the same work. at agent scale this adds up FAST
building Hermes taught me prompt caching is THE cost lever. silent API changes like this hit different when you're paying per token 🤦♂️
English
@rileybrown @steipete Yes. But there are lots of non technical people that need a ready to use system. And for those Cowork is great (lots of people in our company use it and I would never set up each of them a claw)
English

Personally I don’t see the point of Cowork. I don’t even see the point of chatgpt or Claude anymore.
I either want to talk to a claw (agent with all my skills running on a persistent computer with NO guardrails in iMessage or telegram) or i want to use Claude Code or Codex app for coding.
Riley Brown@rileybrown
Codex App > Claude Desktop App
English
@dwlz @rpenacastro Nope, as you didn't stop the whining. And when you started CC it actually told you and shows the effort marker in the bottom right all the time. "without telling us" is bullshit
English

Anthropic: “We don’t degrade our models, we just reduce the amount of thinking effort they use without telling you and update logging to make it hard to notice”

English
@colonelmanic @theo @davis7 Might be dependent on the agent and tools were using. In the end there is no unified way to do skills for any harness, it's just a name that's interpreted differently across implementations 🙏
English


The new btca experience, now just a skill b/c it's way better: github.com/davis7dotsh/be…
Turns out the best way to let coding agents search github for context is to let them search github repos for context
Ben Davis@davis7
funny story, I've been trying to figure out the right shape for btca local for a while now if u haven't seen it, it's cli app that clones git repos u pass in then lets an agent search them. super super useful for getting better code out of agents what if it was a skill? why do I have to write code for: - cloning a repo - starting an agent - tools for the agent I already have a really good coding agent, just let it do all of that for me. It can clone the repo and do the search, and even contort itself into feeling like an app simply by telling it what it should be doing at different times Like if u invoke the skill with a "/" command and no args, it outputs what I would have had a custom tui write. Except I didn't write code I just told it what it's supposed to say if that happens I cannot believe gstack is what made this click for me but it is If u want to try the new version, it's so much better: npx skills add github.com/davis7dotsh/be… --skill btca-local
English