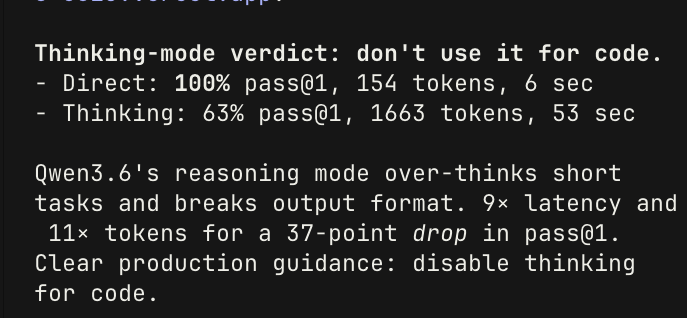
@garrytan Context bleed between parallel Claude Code agents is a real ops problem. Run 3+ lanes on an actual production pipeline and you hit it within an hour — we've been doing manual resets mid-session. Native save/restore is the right abstraction for this.
English