Mack retuiteado
Mack
2.1K posts


Mack retuiteado


Mack retuiteado

The X Money card is gorgeous. Solid metal, numberless, and having the @ handle printed right on the back is such a clean detail.
- get 3% cashback on everything
- earn 6% interest
- 0% FX fee
- reimbursed ATM fees globally
- insured up to 250k
What more could you ask for?


English


🚨 BREAKING: Meta researchers showed a model 2 million hours of video. No labels. No physics textbook. No supervision at all.
It learned gravity. Object permanence. Inertia.
And it just beat Gemini 1.5 Pro and GPT-4 level models at physics understanding.
Here's what just happened:

English
Mack retuiteado

AI won't kill fundamental investing because more information doesn't kill alpha. We have decades of priors here (Excel, Bloomberg, alt data...all democratized analysis & information gathering, and didn't kill alpha). As measured by factor volatility, stocks are less efficient and more alpha-rich than ever (and empirically, the ability of multi-eight figure market neutral multi-managers to consistently grind out 10-15% returns in an idio-maximized way proves this point...15 years ago a $10bn hedge fund was considered to be impossibly large).
Innovations in investment process have shifted alpha pools, for sure, and systematic investors have arbitraged many old, reliable fundamental alpha pools. But as the players at the poker table have shifted, the constraints of those new players have created new alpha pools. Long duration fundamental investing has been gutted, and definitionally competing against a group of non-fundamental (quants, factor/thematic investors, indexers) and duration-constrained (multi's) investors should be a huge competitive advantage, long term (however frustrating in the near term). To wit, a 9-month thesis where I "look through" the next two prints is now considered a long-term thesis.
Rigorous investment process serves investment judgment, but the real alpha generation fits a power-law distribution and there is some ineffable "nose for money" that the great investors have, that cannot be trained necessarily. Investing is a very hard game, that cannot be distilled to a reinforcement learning sandbox (by the time it is, the regime will have shifted and new drivers move stocks). AI has no sense of materiality, no true discernment, and the lack of context of N of 1 situations (if you haven't noticed, we are living in an N of 1 world!). There is a irreducible element of humanness that is critical to success in fundamental investing, and that won't change.
What does this all mean? In my opinion, there is no better time to be starting a careers as an investor. My first year on the desk, I spent a lot of time doing grunt work: updating Nielsen files, updating models for my PM, creating same store sales master files, building question lists for CEO meetings, etc. This is grunt work. I can automate this all now, and get more quickly to the deep, value added parts of learning the investment process.
Will AI drive alpha? This is a debate people are having, which I find sort of silly. When used correctly, by the right investor, of course it will. Ask any great investor if they had another 4 hours of research time per day whether the quality of their research would improve? That's kind of a dumb question...of course it will. Compressing the mechanical part of your job to focus more on the artisanal part of the job is Step 1, and with agentic systems accelerating fast is now in the strike zone of possibility. This is before we start to layer in a broader monitoring net and use cases to go deeper and build more rigor, finding signals in unstructured data that were missed before, as well as turning your investment genius into a co-pilot pattern recognition system.
The future is very bright for fundamental investing, in my opinion.
English
Mack retuiteado

That is really really impressive: GPT-5.4 pro has solved one of the open problems in FrontierMath.
Kevin Barreto and Liam Price, using GPT-5.4 Pro, produced a construction that Will Brian confirmed, with a write-up planned for publication
We are accelerating

Epoch AI@EpochAIResearch
AI has solved one of the problems in FrontierMath: Open Problems, our benchmark of real research problems that mathematicians have tried and failed to solve. See thread for more.
English
Mack retuiteado

Sorry for posting this again, I'm still processing it:
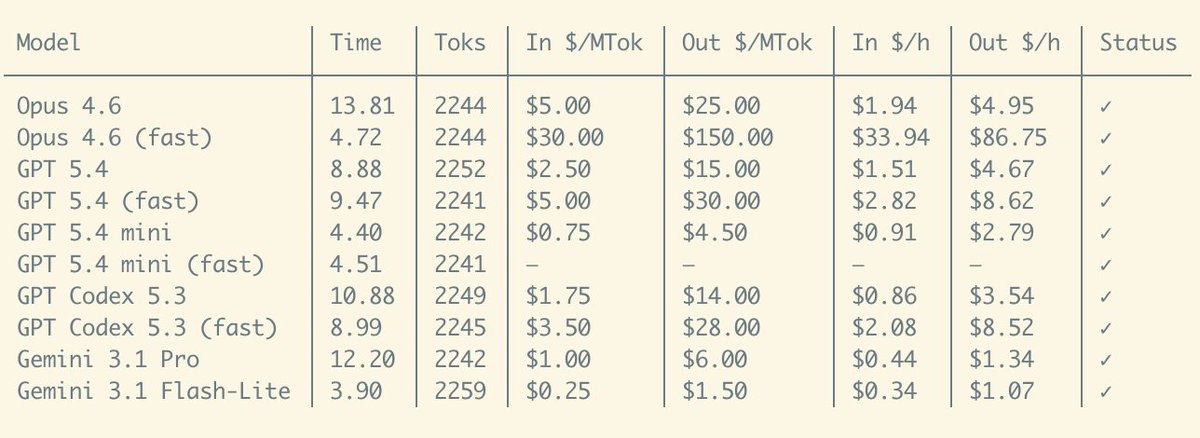
It'd cost >>> $743k per year <<< to run Opus-4.6 fast-mode nonstop
Literally my company cannot afford a single person using it for daily coding. And that's a shame because the experience is truly magical. I've spent the last 2 days using it on Pi (nearly $500 gone 💀), and it was the first time I kinda got into the flow state while using an agent, because the feedback is just so fast. This is not something I ever experienced before, definitely not with GPT 5.4's own fast mode.
I can't wait for this kind of super fast, super high intelligence to be available for a reasonable cost...
English
Mack retuiteado

Today we filed the initial S-1 for Grayscale HYPE ETF (ticker: $GHYP) with the @SECGov.
Read the S-1: sec.gov/Archives/edgar…
English

I wrote a new paper on autonomous swarm orchestration fo quant finance.
The Hive: an autonomous swarm orchestration system that spawns, directs, and kills its own agents, shares knowledge across all of them through a centralized graph.
It also learns from you. And eventually, it stops needing you.
Paper dropping soon.




English
Mack retuiteado

论文来了。名字叫 MSA,Memory Sparse Attention。
一句话说清楚它是什么:
让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。
过去的方案为什么不行?
RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。
线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。
MSA 的思路完全不同:
→ 不压缩,不外挂,而是让模型学会「挑重点看」
核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。
→ 模型知道「这段记忆来自哪、什么时候的」
用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。
→ 碎片化的信息也能串起来推理
Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。
结果呢?
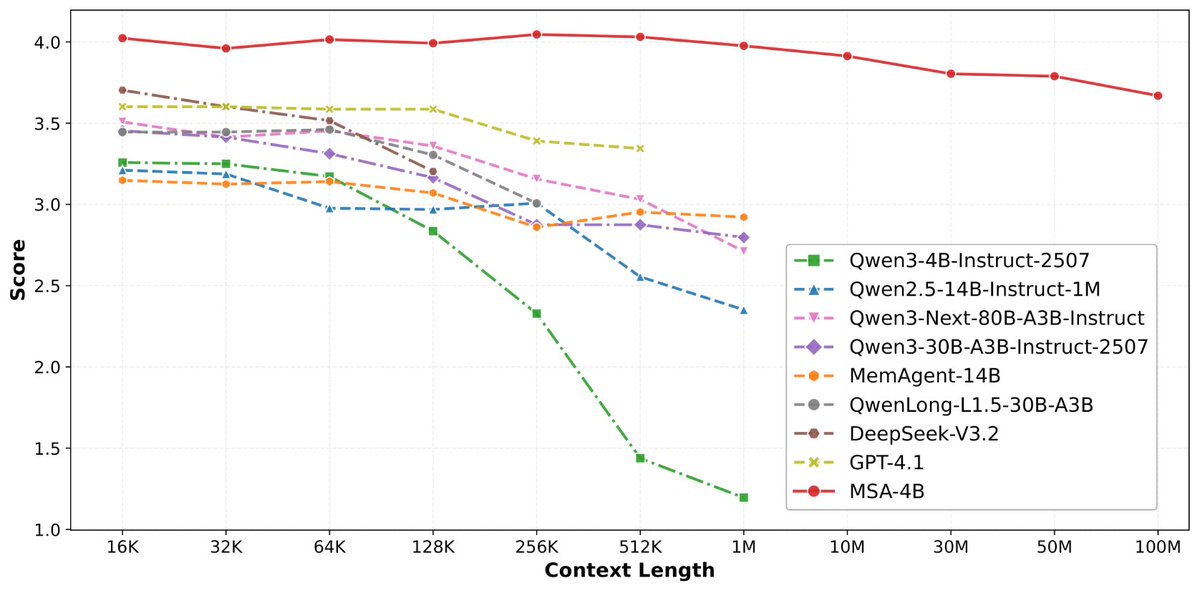
· 从 16K 扩到 1 亿 token,精度衰减不到 9%
· 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统
· 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。
说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。
我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏
github.com/EverMind-AI/MSA
艾略特@elliotchen100
稍微剧透一下,@EverMind 这周还会发一篇高质量论文
中文

Yann LeCun and his team dropped yet another paper!
"V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning"
In this V-JEPA upgrade, they showed that if you make a video model predict every patch, not just the masked ones AND at multiple layers, they are able to turn vague scene understanding into dense + temporal stable features that actually understands "what is where".
This key insight drove improvements in segmentation, depth, anticipation, and even robot planning.

English
Mack retuiteado

On the @theallinpod this week, @chamath asked @nvidia CEO Jensen Huang about decentralized AI training, calling our Covenant-72B run "a pretty crazy technical accomplishment."
One correction: it's 72 billion parameters, not four. Trained permissionlessly across 70+ contributors on commodity internet. The largest model ever pre-trained on fully decentralized infrastructure.
Jensen's answer is worth hearing too.
English
Mack retuiteado

Mack retuiteado

We will make frontier intelligence run on 1000$ of hardware by the end of the year.
Eric@Ex0byt
Kimi-K2.5 (1T-parameter MoE) running coherently on 25GB of GPU memory (on a unified 128 GB machine)!
English
Mack retuiteado

Mack retuiteado

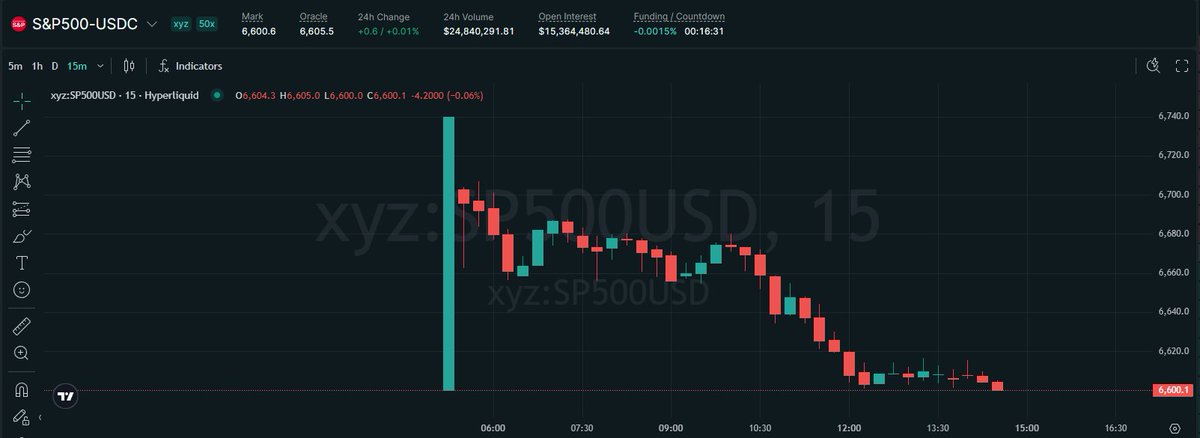

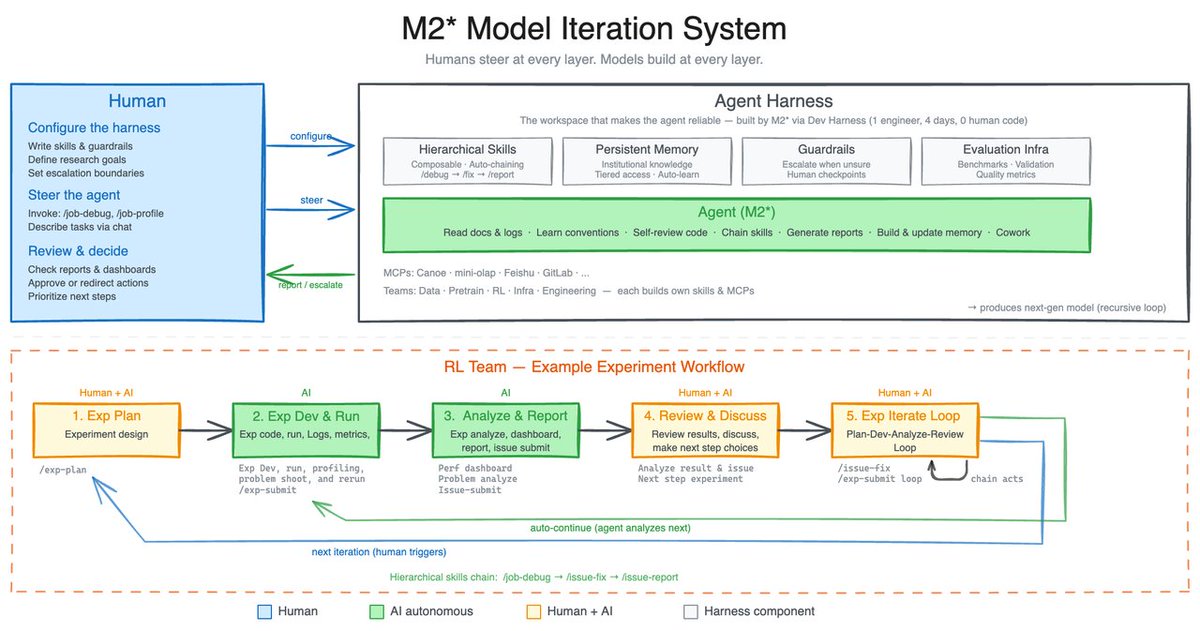
During the iteration process, we also realized that the model's ability to recursively evolve its harness is equally critical.
Our internal harness autonomously collects feedback, builds evaluation sets for internal tasks, and based on this continuously iterates on its own architecture, skills/MCP implementation, and memory mechanisms to complete tasks better and more efficiently.
English
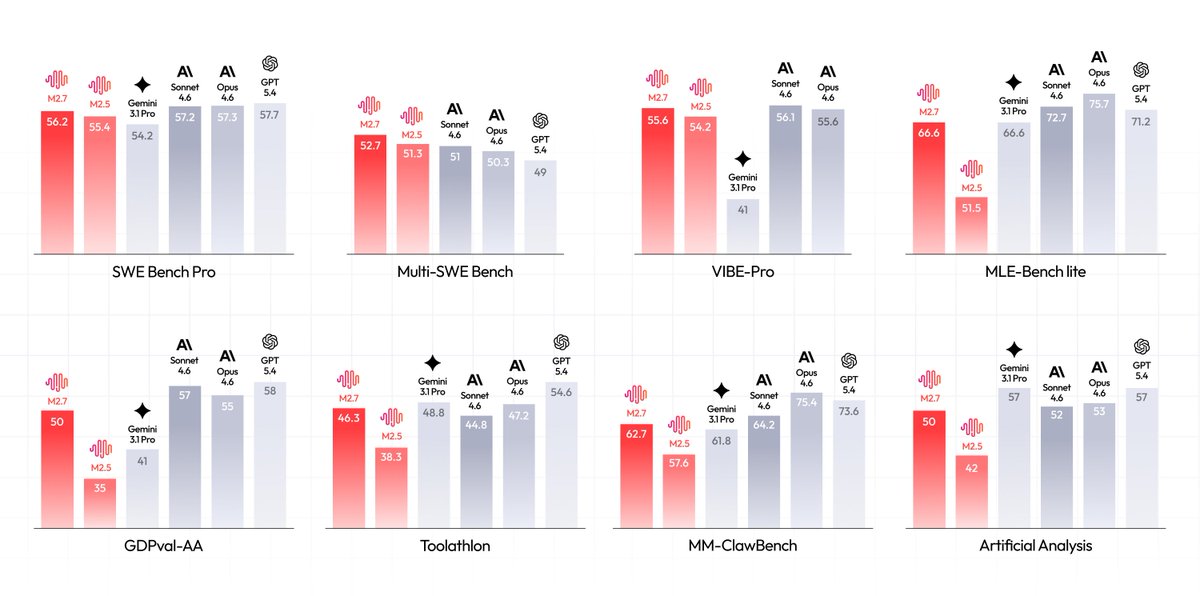
Introducing MiniMax-M2.7, our first model which deeply participated in its own evolution, with an 88% win-rate vs M2.5
- Production-Ready SWE: With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%), M2.7 reduced intervention-to-recovery time for online incidents to 3-min on certain occasions.
- Advanced Agentic Abilities: Trained for Agent Teams and tool search tool, with 97% skill adherence across 40+ complex skills. M2.7 is on par with Sonnet 4.6 in OpenClaw.
- Professional Workspace: SOTA in professional knowledge, supports multi-turn, high-fidelity Office file editing.
MiniMax Agent: agent.minimax.io
API: platform.minimax.io
Token Plan: platform.minimax.io/subscribe/toke…
English
Mack retuiteado
