dfi
2.6K posts


dfi
@dfi
M&A & Blockchain lawyer in NYC | Tweets not legal advice (email me) | Opinions are my own | DAO Council Member @FRWCCouncil | Claw & LocalLLM Hobbyist



Quantization can make an LLM 4x smaller and 2x faster, with barely any quality loss. But what *is* it? @samwhoo crafted a beautiful interactive essay explaining it from first principles, aimed at coders, not mathematicians. ngrok.com/blog/quantizat…

🚨 Yes, running a ~400B (397B) parameter AI on an 🍎 iPhone is 100% REAL. 🤯 Been following the posts and reactions over the weekend. The Flash-MoE engine ingeniously shatters hardware limits 🧠, running massive Mixture-of-Experts models on Apple Silicon (iPhone 17 Pro & Macs) with only 12GB of RAM. Here’s how it works & how to try it yourself. 🧵👇 🧠 How is this physically possible? Normally, a 397B model in 4-bit quantization needs ~209GB just to load fully. Flash-MoE bypasses this with two key tricks: 1️⃣ By using SSD-to-GPU streaming, it doesn't load the entire model into RAM. It streams only the necessary expert weights on demand directly from @Apple's ultra-fast NVMe SSD to the GPU using parallel pread() calls. The OS page cache handles hits automatically ("trust the OS"). ⚡ 2️⃣ Only a tiny fraction of parameters activate per token due to MoE. For Qwen3.5-397B-A17B, it activates ~17B total (top K experts per layer, reduced to K=4–6 on mobile for speed). As a result, ~0.6–2 tokens/sec on iPhone 17 Pro for the 397B model (0.6 t/s in early demos; 1–2 t/s projected with K-reduction & splits). Extremely slow but usable for short prompts! 📱💨 💻 How to build & run on Mac Start with the 35B model—it's much faster (~9–10 t/s on M3 Max, ~5.5+ t/s on iPhone). 1️⃣ Clone the repo: git clone Alexintosh/flash-moe 2️⃣ Build the Metal engine cd flash-moe/metal_infer && make 3️⃣ Run it ./infer --model /path/to/weights --prompt "Hello" --tokens 100 (Add --tiered if using tiered-quant weights for smaller footprint) ⚠️ Note that you should use pre-packed raw .bin weights from Hugging Face (NOT safetensors). Pre-packed models available under alexintosh/... 📱 How to build & run on iPhone 1️⃣ Build the Xcode project from FlashMoE-iOS/ in the repo (or check releases if available). Requires iOS 18+. 2️⃣ Download pre-packed 35B from Hugging Face: alexintosh/Qwen3.5-35B-A3B-Q4-Tiered-FlashMoE (~13.4–19.5GB). 3️⃣ Push model files to the app's Documents directory (use copy_model_to_iphone.sh script over USB, or UIDocumentPicker). Set files to isExcludedFromBackup. 4️⃣ Open the app, select the model folder, and start prompting! 💬 🔥 Warning Heavy SSD streaming + GPU compute draws massive power. Your phone WILL get very hot and drain battery fast! Avoid long sessions. 🔋📉 GitHub: Alexintosh/flash-moe

🚨 BREAKING: Claude can now write legal contracts like NDAs, freelance agreements, and LLC paperwork better than $800/hour corporate lawyers. Here are 12 prompts that replace $15,000 in legal bills: (Save this before it disappears)

@pierrelezan Yes, @Ex0byt is working on this.

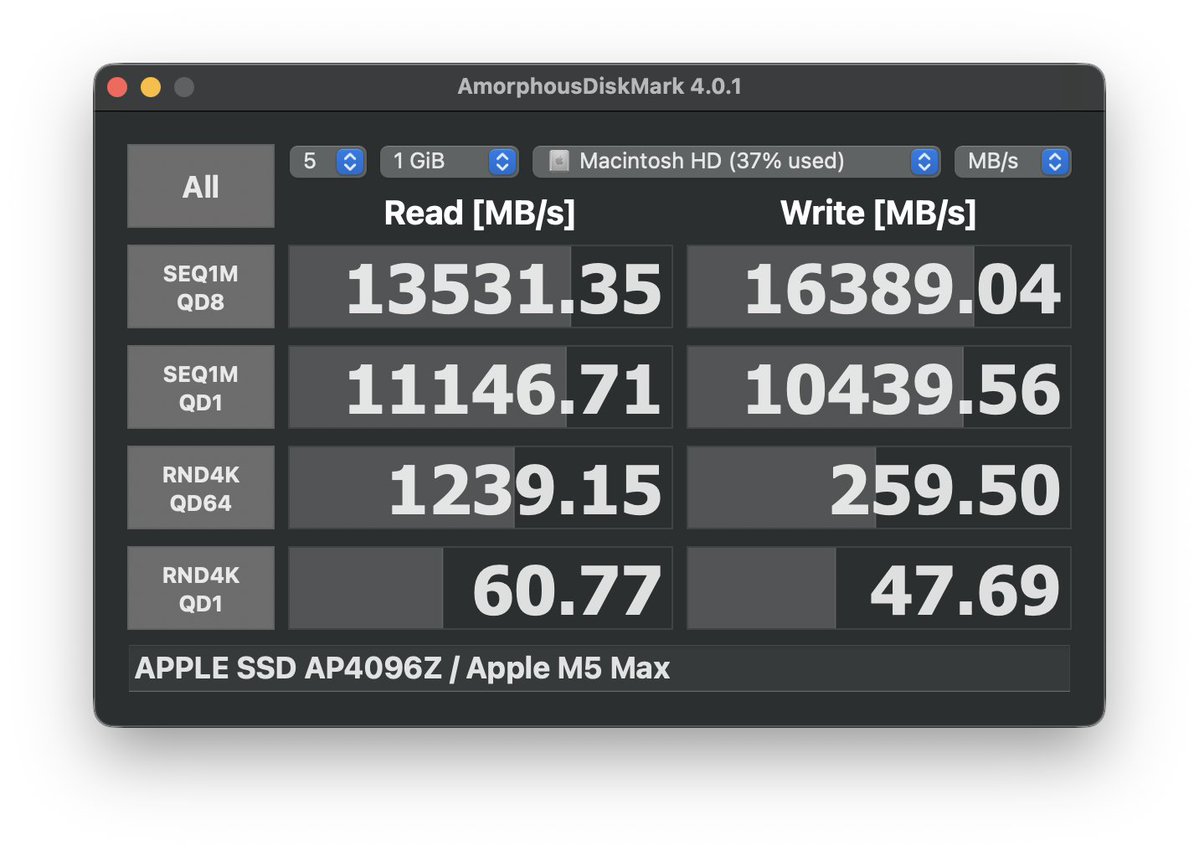

Jensen Huang is loving the new Dell Pro Max with GB300 at NVIDIA GTC.💙 They asked me to sign it, but I already did 😉






Another great article from Zack. The “hollowed out” segment of legal services is enormous and where the most interesting developments are about to take place.