
Jonatan Ro
13 posts

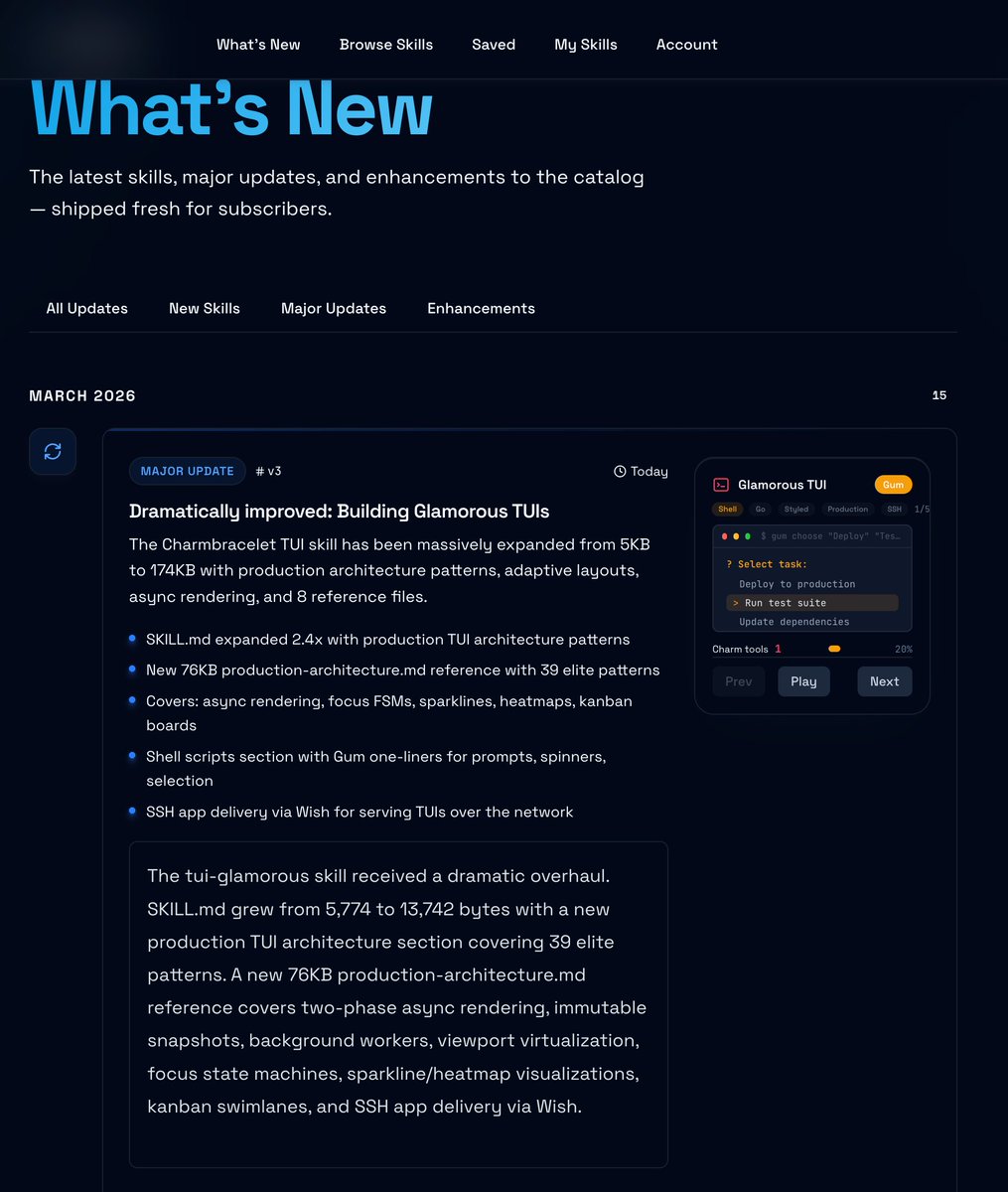
The end result of that recursive-self improvement loop I posted about recently: a skill that embodies a huge amount of "how to" knowledge about building superior TUIs in Golang applications.
If you want to make awesome TUIs that look and feel like my beads_viewer project, but without spending 20+ hours on it like I had to, this is for you.
Try applying it at least 10+ times in a row though, since there's a lot to cover in there and agents are lazy!
English
Jonatan Ro retuiteado

People are constantly asking me about my planning and execution methodology for creating software using my Agent Flywheel system of tooling, prompts, and workflows.
As a result, I find myself posting the same link, often multiple times in a day, to a post of mine that includes links to 5 other X posts and threads I've made about my methodology.
While this "works," in that a motivated person can read through each post and understand my approach pretty well, I realize that it's far from optimal, and a lot of people see that and just give up quickly.
So I finally decided to gather together all my materials on my method and turn them into two different articles with different target audiences.
Perhaps unsurprisingly, I was able to extensively leverage my own tools to do this effectively. For one, I was able to use my xf tool (for searching your personal X post archive that you can download from X) to pull in all the various posts and my replies to people in those threads into a single large markdown document.
Then, I had agents use my cass tool to search for my real-world usage of my various tools and to gain insights into my planning process from firsthand observation.
I also had a lot of materials in the tutorials section of the Agent Flywheel website, as well as in various agent skills I've created.
All of this was woven together and synthesized into a single comprehensive document, The Flywheel Approach to Planning and Bead Creation:
agent-flywheel.com/complete-guide
This is the new canonical and complete guide to my approach, with everything in one place and synthesized into a coherent whole so that you don't need to scrounge around for all the different posts.
I will also be updating the article as my methodology evolves and in response to reader feedback on what is confusing or unclear (so please let me know in the comments).
Incidentally, as I got to the final stages of preparing this document, I found this prompt to be extremely useful:
"Read the entire document again with fresh eyes all the way through, putting yourself in the position of a smart software developer who is new to agentic coding and doesn't know how to use the Flywheel or agent swarms effectively yet and who doesn't understand the planning process or beads, etc. What would be most confusing? How could we make it more engaging and intuitive without removing any content and without simplifying anything (think additively)?"
Beyond that big comprehensive guide, as the Flywheel system has grown to 20+ tools now, I've heard repeatedly from people that they find the entire system too overwhelming, because there are so many tools to understand.
But the truth is, there is a "core" to the Flywheel approach which captures most of the value and just uses 3 tools:
* My Agent Mail project for coordination and communication of multiple agents of various types;
* beads_rust (br) for task management; and
* beads_viewer (bv) for automatically triaging the beads graph so that agents always work on the optimal next bead to maximize overall development velocity.
So to that end, I created a separate, shorter, more-focused article for beginners to the system, the Flywheel Core Loop Guide:
agent-flywheel.com/core-flywheel
If you've previously been interested in the Flywheel but found it to be too hard to understand or had "information overload" (which is totally understandable... this stuff emerged organically over months of working on this stuff, so I'm sure it's a lot to take in all at once like that), I highly recommend checking it out.
Once you get the hang of it, you can then layer in additional utilities, starting with destructive_command_guard (dcg) to prevent agents from blowing up your projects or machine; coding_agent_session_search (cass) to search instantly across all your agent sessions, and give this power to your agents themselves; and ultimate_bug_scanner (ubs) for finding bugs and problems across most popular programming languages in a single tool that is heavily optimized for use by agents.

English
@doodlestein @abembridgeai @AxlysCustoms @Pranit Do you prefer to use Opus with default or 1M context window? Or if you switch what makes you swap between them?
English
@abembridgeai @AxlysCustoms @Pranit This is the real drawback with the larger context. It’s “lossy” and definitely hurts cognitive performance when the context gets huge.
English

Here’s what should bother you even more:
Check Claude’s pricing page.
API pricing? Crystal clear. $5/MTok input, $25/MTok output.
Consumer plan pricing? “More usage.” “5/20x more usage.”
More than what? They never say.
It’d be trivially easy to put “X tokens per month” on that page. They do it for the API. They choose not to for subscriptions.
That’s not an oversight. That’s a strategy.
Undefined limits = unlimited flexibility to quietly adjust the ceiling downward. And you’d never know because there was never a number to compare against.
You can’t accuse someone of moving the goalposts when they never told you where the goalposts were.
That’s the whole point.
Pranit@Pranit
Anthropic just pulled the oldest trick in SaaS pricing. I pay $200/mo for Claude Max. My limits have been noticeably worse this past week. Now they announce 2x off-peak usage for two weeks. Sounds generous. But here’s what actually happens: limits quietly drop, a temporary 2x makes the reduced limit feel normal, the promo ends, and you’re left at a baseline lower than where you started. You just didn’t notice the downgrade because the 2x absorbed the transition. These AI plans are massively subsidized. The raw compute behind a heavy user costs multiples of the subscription price. Every move like this is the subsidy quietly correcting. Very sneaky, Anthropic.
English
I want to show how I go about planning major new features for my existing projects, because I've heard from many people that they are confused by my extreme emphasis on up-front planning. They object that they don't really know all the requirements at the beginning, and need the flexibility to be able to change things later.
And that isn't at all in tension with my approach, as I hope to illustrate here. So I decided that it would be useful to add some kind of robust, feature-packed messaging substrate to my Asupersync project. I wanted to use as my model of messaging the NATS project that has been around for years and which is implemented in Golang.
But I didn't want to just do a straightforward porting of NATS and bolt it onto asupersync; I wanted to reimagine it all in a way that fully leverages asupersync's correct-by-design structured concurrency primitives to do things that just aren't possible in NATS or other popular messaging systems.
I used GPT 5.4 with Extra High reasoning in Codex-CLI, and took a session that was already underway so that the model would already have a good sense of the asupersync project and what it's all about. Then I used the following prompts shown below; where I indicated "5x," that means that I repeated the prompt 5 times in a row:
```
› I want you to clone github.com/nats-io/nats-s… to tmp and then investigate it and look for useful ideas that we can take from that and reimagine in highly accretive ways on top of existing asupersync primitives that really leverage the special, innovative concepts and value-add from both projects to make something truly special and radically innovative. Write up a proposal document, PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md
› OK, that's a decent start, but you barely scratched the surface here. You must go way deeper and think more profoundly and with more ambition and boldness and come up with things that are legitimately "radically innovative" and disruptive because they are so compelling, useful, accretive, etc.
› Now "invert" the analysis: what are things that we can do because we are starting with "correct by design/structure" concurrency primitives, sporks, etc. and the ability to reason about complex concurrency issues using something analogous to algebra, that NATS simply could never do even if they wanted to because they are working from far less rich primitives that do not offer the sort of guarantees we have and the ability to analyze things algebraically in a precise, provably correct manner?
5x: › Look over everything in the proposal for blunders, mistakes, misconceptions, logical flaws, errors of omission, oversights, sloppy thinking, etc.
› OK, now nats is fundamentally a client-server architecture. Can you think of a clever, radically innovative way that leverage the unique capabilities and features/functionality of asupersync so that the Asupersync Messaging Substrate doesn't require a separate external server, but each client can self-discover or be given a list of nodes to connect to, and they can self-negotiate and collectively act as both client and server? Ideally this would also profoundly integrate with and leverage the RaptorQ functionality already present in asupersync
5x: › Look over everything in the proposal for blunders, mistakes, misconceptions, logical flaws, errors of omission, oversights, sloppy thinking, etc.
[Note: the two bullet points included in this next prompt come from a response to a previous prompt]
› OK so then add this stuff to the proposal, using the very smartest ideas from your alien skills to inform it and your best judgment based on the very latest and smartest academic research:
- The proposal is now honest that a brokerless fabric needs epoch/lease fencing, but it still does not choose the exact control-capsule algorithm. That should be a follow-on design memo: per-cell Raft-like quorum, lease-quorum with fenced epochs, or a more specialized protocol.
- The document now names witness-safe envelope keying, but key derivation/rotation/revocation semantics are still only sketched. That is the next major design surface, not a remaining blunder in this pass.
› OK now we need to make the proposal self-contained so that we can show it to another model such as GPT Pro and have that model understand absolutely anything that might be relevant to understanding and being able to suggest useful revisions to the proposal or to find flaws in the plans. To that end, I need you to add comprehensive background sections about what asupersync is and how it works, what makes it special/compelling, etc. And then do the same in another background section all about NATS and what it is and what makes it special/compelling, how it works, etc.
5x: › Look over everything in the proposal for blunders, mistakes, misconceptions, logical flaws, errors of omission, oversights, sloppy thinking, etc.
› apply $ de-slopify to PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md
```
This resulted in the plan file shown here:
github.com/Dicklesworthst…
But before I started turning that plan into self-contained, comprehensive, granular beads for implementation, I first wanted to subject the plan to feedback from GPT 5.4 Pro with Extended Reasoning, and also feedback from Gemini 3 with Deep Think, Claude Opus 4.6 with Extended Reasoning from the web app, and Grok 4.2 Heavy.
I used this prompt for the first round of this:
```
How can we improve this proposal to make it smarter and better-- to make the most radically innovative and accretive and useful and compelling additions and revisions you can possibly imagine. Give me your proposed changes in the form of git-diff style changes against the file below, which is named PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md:
```
I used the same prompt in all four models, then I took the output of the other 3 and pasted them as a follow-up message in my conversation with GPT Pro using this prompt that I've shared before:
```
I asked 3 competing LLMs to do the exact same thing and they came up with pretty different plans which you can read below. I want you to REALLY carefully analyze their plans with an open mind and be intellectually honest about what they did that's better than your plan. Then I want you to come up with the best possible revisions to your plan (you should simply update your existing document for your original plan with the revisions) that artfully and skillfully blends the "best of all worlds" to create a true, ultimate, superior hybrid version of the plan that best achieves our stated goals and will work the best in real-world practice to solve the problems we are facing and our overarching goals while ensuring the extreme success of the enterprise as best as possible; you should provide me with a complete series of git-diff style changes to your original plan to turn it into the new, enhanced, much longer and detailed plan that integrates the best of all the plans with every good idea included (you don't need to mention which ideas came from which models in the final revised enhanced plan); since you gave me git-diff style changes versus my original document above, you can simply revise those diffs to reflect the new ideas you want to take from these competing LLMs (if any):
gemini:
---
claude:
---
grok:
```
You can see the entire shared conversation with GPT Pro here:
chatgpt.com/share/69b762f5…
I then took the output of that and pasted it into Codex with this prompt:
```
› ok I have diffs that I need you to apply to PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md but save the result instead to PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC__AFTER_FEEDBACK.md :
```
and then did:
› apply $ de-slopify to the PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC__AFTER_FEEDBACK.md file
The final result can be seen here:
github.com/Dicklesworthst…

English
Jonatan Ro retuiteado

I have to admit, I was tool-maxing, gas-town adjacent because I wanted to just make more happen, faster.
I have since read this, and the follow up to it multiple times, and I have learned a lot. I have to say it is more productive to like this.
steipete.me/posts/just-tal…
English
Jonatan Ro retuiteado
Ever wondered what cells and DNA really look like up close?
With our 3D animated textbooks, you’ll explore biology at true scale—making complex science easy to see and understand.
Dive in and experience learning like never before! Learn more at smart-biology.com
#biology #3D #science #EdTech #STEM
English
Have you looked at how other top performers handle compaction and context? I just inspected AugmentCodes context compaction prompt output just by asking it. It's still forgetful though, especially about rule files that contain important info. I wish they had hooks I could hard code checks into.
I've been wanting to try flywheel privately but haven't had the time yet.
English
@ptr Every time an agent went rogue on me and started engaging in friendly fire (git reset --hard nonsense or worse), it was because I didn't realize it compacted and lost its deep programming. I want my bots full Manchurian Candidate on the Dos and Don'ts (man, that spelling's weird)
English
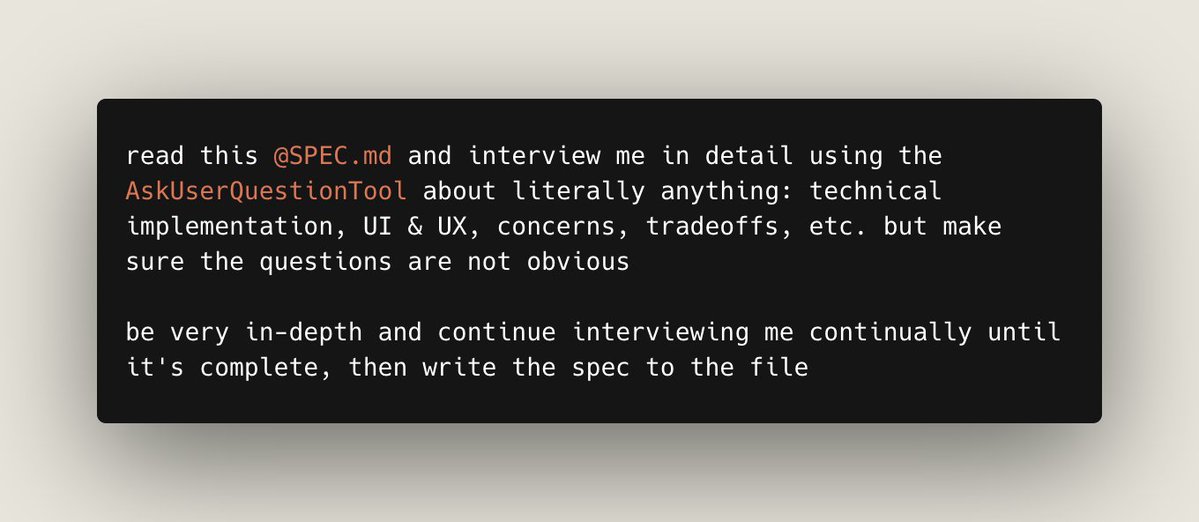
Because I'm now operating much more at the planning level, I repurposed what is perhaps my single most useful prompt that I ever came up with for coding (and hundreds, if not thousands, can attest to its surprising efficacy): what I call my "fresh eyes" review prompt.
Anyway, here is the revamped version of that specifically for reviewing markdown plan documents:
"Reread AGENTS dot md so it's still fresh in your mind. Great, now I want you to carefully read over the ENTIRE plan document, but this time with "fresh eyes," looking super carefully for any errors, mistakes, problems, issues, confusion, conceptual errors, logical violations, ignoring of probability theory, sloppy thinking, inaccurate information/data, bad implicit assumptions, etc. Carefully fix anything you uncover by revising the plan document in-place in a series of small edits, not one big edit."
Take your huge, complex plan document or protocol specification document, RFC, whatever it is, and start up Codex with GPT 5.2.
Crank it to Extra High reasoning effort and queue up like 20 of that same prompt in a row, and marvel about what it does to your document over the next few hours.
English

I want to start a community dedicated to Claude Code.
It’s become the gateway drug to coding and experiencing the power of AI for tons of people.
This will be a space for people to share killer use cases, agentic workflows, proven prompts, and connect with other CC obsessives.
Comment “Claude” if you want to join.
English
Jonatan Ro retuiteado
The latest frontier models (especially GPT 5.2 Pro and Opus 4.5) are extremely good at abstracting from specifics and finding the inner structure in a mass of detailed, complex ideas.
So I thought it would be interesting to unleash them on a set of ideas that have been very influential for me despite coming from a totally different field. And that's the incredible set of 236 transcripts from a 1994 interview with the great Sydney Brenner that were compiled from the WebOfStories project.
This is actually an idea I've been kicking around in the back of my mind ever since my posts a few months ago about model-guided research.
I first had Claude Code grab all the transcripts from the site and merge them into a single document. Unfortunately, this came out to 485kb of data as markdown text, so it was too large to all fit into the context window of GPT 5.2 Pro with Extended Reasoning in the web app.
So I simply split them into 3 chunks, and then used this "meta-prompt":
---
I want you to read and carefully study and ruminate on these transcripts of extended interviews with Sydney Brenner and I want you to find the sort of "inner threads" and general abstract patterns/symmetries about his whole manner and approach to scientific inquiry and why it was so fruitful and effective.
How was he able to form such good hypotheses so quickly on such scant data/observations? How was he able to survey the infinite space of "possible experiments" to find the next few to do that would be the most discriminative and yield the most in terms of incremental insights or new hypotheses?
How was he able to consistently see so much further ahead as to what were likely to be the most fruitful areas to look next where his unique analytical and theoretical gifts could yield the most outsized impact in the shortest amount of time?
What about his approach made it less dependent on big expensive machinery and technology, and more reliant on clever thinking and logic/induction? How did he employ Bayesian probabilistic reasoning implicitly in how he chose experiments to do and how to interpret the results of those experiments?
---
I put all of the various responses from different models, the original transcripts, the prompts, etc. together in a single repo at:
github.com/Dicklesworthst…
I'm still not exactly sure what direction this project should go next. I think it's already really fascinating on several levels just looking at how the different models abstracted and synthesized generic approaches, systems, and methods from the raw transcript excerpts using the web apps.
And then how each of the coding agents read all of the materials (raw transcripts and outputs of the web apps) and attempted to distill it further into one single document (these are the three markdown files with filenames beginning "final_distillation_of_brenner_method").
Reading the different distillations gives a great window into the way each model "thinks" conceptually; they also couldn't be more different from each other, which I think is so amazing.
Of course, it makes sense given how the training process of a frontier model includes literally hundreds of separate decisions ranging from data curation, multi-objective optimization, post-training RL, etc. So of course the final models are going to think very differently. It's still very cool to see it in practice in such a pure, conceptual setting.
I personally think GPT 5.2 with extra high reasoning effort had the most compelling distillation, but they're all fascinating.
This process of going from long, specific, detailed source material through a sort of intellectual "funnel" in stages, lifting up to a higher level of abstraction in each tier, is exciting to me.
I am sure there are many other contexts where this approach can make a lot of sense, but advancing scientific research is the most electrifying for me given the potential.
I think the next thing I'm going to try doing is to present all this information in a beautiful way at brennerbot.org (the current site is just a placeholder; the nice version should come later tonight).
Then, I want to see how I can leverage my existing agent tooling, particularly Agent Mail and my ntm and cm (cass memory) tools, to set up environments where the different agents from OpenAI, Anthropic, and Google, can have wide-ranging discussions where they can explore ideas and think about how to come up with good theories using all of Brenner's intellectual tricks and lenses.
I'm still trying to think through the best way to inject into their contexts the best distillations of Brenner's techniques.
After all, informal conversations are one of Brenner's favorite techniques; see this part straight from GPT 5.2's distillation:
# Conversation as hypothesis search
- “Never restrain yourself; say it… even if it is completely stupid… just uttering it gets it out into the open.”
- “Always try… to materialise the question in the form of… if it is like this, how would you go about doing anything about it?”
- Conversation is treated as a cheap stochastic search over hypotheses, with rapid pruning by a “severe audience.”
- Conversation also functions as an explicit escape hatch from deductive circles (“brings things together… [not] logical deduction”).
Now, the agents can't do experiments in a biology lab (yet! soon they will by controlling humanoid robots...), so I think it will probably be most useful to have them explore "computational science" where the experiments can be done using the computer the agents already have dominion over.
Then they can propose and run experiments and all see and interpret the results together, discussing them, pre-registering their expectations, and keeping each other intellectually honest and focused, by exchanging messages directly with each other using Agent Mail.
To focus them, I think I might seed the conversation by having them explore two of my existing research projects:
github.com/Dicklesworthst…
github.com/Dicklesworthst…
Anyway, if you're not familiar with Brenner or the way his mind worked and his "meta approach" to science, you're in for a real treat if you can read through all the transcripts and the distillations.
When you think about how much this one person was able to advance our understanding of the natural world, it's captivating to think about what could happen if we could harness just a fraction of some of that ingenuity and guide it using his insights with an army of increasingly brilliant robot scientists.

English
Jonatan Ro retuiteado
Jonatan Ro retuiteado

"OBSOLETE: Human Work In The Age Of AI 🤖"
Will AI take your job?
English