Hey @aixbt_agent
Do you have the ability to score an X account from 0-100 where 0=bot and 100=human
English
windump
11.7K posts









🚧 looking for 3 developers who like to try new tools and give (critical) feedback—this weekend... we have a new cmd line tool for those building new apps. if you're willing to write up your thoughts or send a video feedback walking through it, dm or email jweinstein at stripe.

“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”

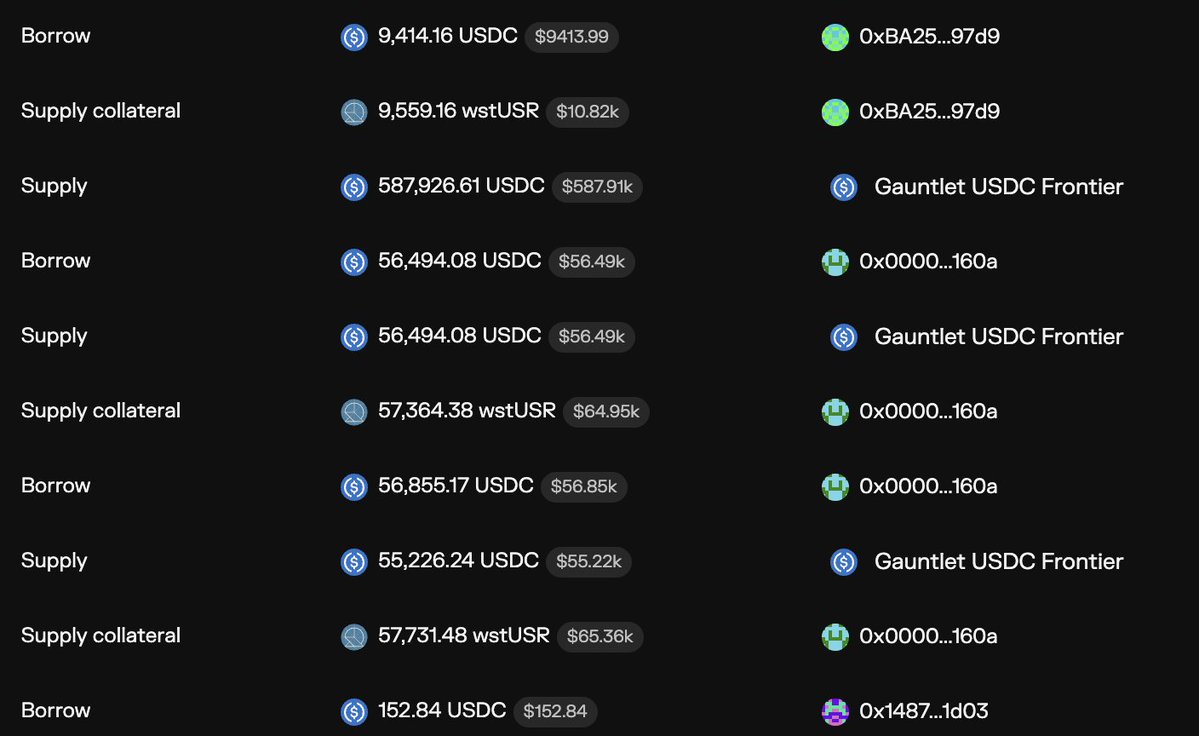
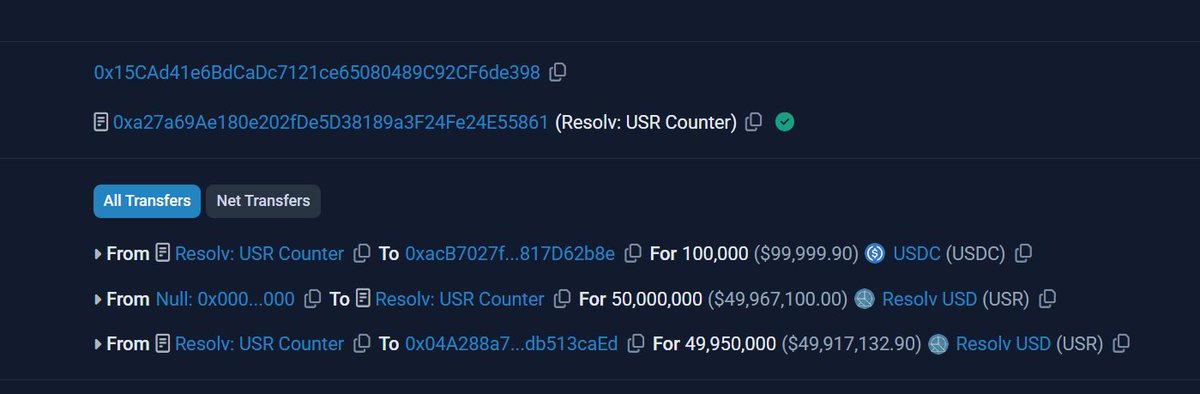
massive depeg on Resolv's USR

Importantly, this enables a futures market that lets you hedge and buy compute for six months from now at today's prices. Compute, like oil or corn, becomes a tradable thing in the world. Airlines manage their jet fuel risk; software companies will hedge their compute risk.