Tweet épinglé
fullstack
18.4K posts



fullstack retweeté

It would be a shame if everyone emailed `dylan @ dylanmtaylor [.] com` with their concerns about him opening age verification PRs
Absolutely don't email dylan @ dylanmtaylor [.] com with your concerns about him opening age verification PRs

Vini B |「 thecoding 」@vinibarbosabr
@LundukeJournal daylanmtaylor tried the same thing on Arch Linux's archinstall repo he is pushing these implementations everywhere
English
fullstack retweeté

Damn, she's spitting fire on H-1B. She was replaced by H-1Bs and is now running for office. Nice, give her some love!
Kim Georgeton for Lt. Governor of Ohio@KimGeorgeton
Let’s talk H1B. In March 2024, I got a call. My job was gone. So was everyone else's. Infosys didn't replace one or two of us. They replaced the whole department. Every. Single. One. Their guy chose to keep his friends employed over American workers. This isn't a story. It's a playbook. Here's what they don't tell you about H-1B abuse in Ohio: → Ohioans have lost ~$300M per H-1B worker cycle → Wages drop tens of thousands per replaced job → That money doesn't pay Ohio rent. Doesn't hit Ohio restaurants. Doesn't pay Ohio taxes. It leaves. Infosys paid $34M settling federal fraud charges for exactly this. Now Vivek Ramaswamy wants to be Ohio's governor. The same man whose company used H-1B visas 29 times. The same man who told Americans we "venerate mediocrity over excellence." He got fired from DOGE partly for saying that. He says he wants to reform H-1B now. His record says otherwise. I'm running for Lt. governor because I know what it feels like. To be told your job, your team, your livelihood just doesn't matter. Ohio workers matter. Ohio paychecks should stay in Ohio. We will solve this. Share this. 🗳️ Vote @CaseyPutsch — May 5 📋 Register by April 6
English
@YebHavinga if you can crack this and subagents which is summarizing the context and doing a defined task, it's joe_over.jpg
youtube.com/watch?v=a4eav7…

YouTube
English

I just asked claude to rerun the batched test for 27b and in in the <4K window size (where the int8 kv cache is not really helpful, but speed max) and got 1312 tok/s at batch size 256 where it plateaued. Maybe there the int8 kv cache is only interesting to allow higher batch sizes.
English
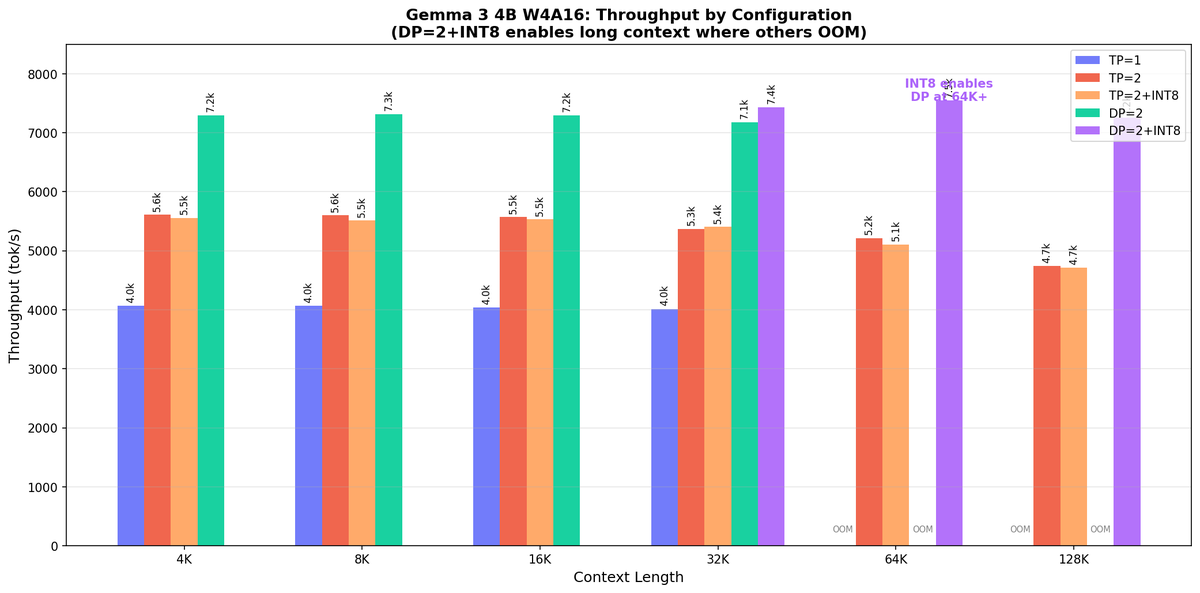
I have a dual RTX 3090 system that has lately been mostly collecting dust. Inspired by Karpathy's autoresearch post, I wondered: can I get a frontier-class open model running well on this setup with a coding agent?
Turns out yes. I’m particularly interested in the Gemma 3 series, since they handle Dutch well and the dense Gemma 3 27B follows complex instructions reliably. Gemma 3 27B now runs at 67 tok/s for short prompts and 45 tok/s for long context (7K+ tokens), with a 128K context window.
The starting point was bad, out of the box I got 11 tok/s with vLLM. The model loaded fine (W4A16 quantized fits in 48 GB with tensor parallelism), but something was killing performance.
Discovery 1: CUDA graphs need `--disable-custom-all-reduce` on RTX 3090. vLLM’s custom all-reduce kernel crashes during CUDA graph capture at 94% completion. Disabling it and falling back to NCCL from 11 tok/s to 67 tok/s.
Discovery 2: Long-context performance cliffs at ~4K tokens. Gemma 3 uses hybrid attention : 52 layers with 4K sliding window and 10 layers with full attention. Beyond 4K tokens, vLLM falls back from CUDA graphs to eager mode, causing speed to drop from 67 to 24 tok/s.
The initial hypothesis was wrong. Claude thought cascade attention was disabling CUDA graphs and spent a day chasing that. In reality, cascade attention is already disabled for sliding-window models. The bottleneck is memory bandwidth: the 10 global attention layers must read the entire KV cache every decode step.
Discovery 3, main idea: Use an INT8 KV cache to fix long context memory bound inference. The Ampere RTX 3090 lacks FP8 hardware (Ada/Hopper only), but has INT8 tensor cores. Claude wrote Triton kernels to quantize K and V to INT8 on write and dequantize on read. Result: 24 tok/s → 45 tok/s at 7K context (+87%). KV memory halved, so 128K context now fits, where before with 16bits 32K was the max.
Discovery 4: Per-layer scales matter. Gemma 3 has 62 attention layers. With uniform / global scaling, layer 42 (v_absmax=884) and layer 59 (v_absmax=2.6) share the same quantization budget, a 340x ratio. Layer 59 uses only 47 of 127 INT8 levels. Per-layer calibration gives each layer its full dynamic range.
Discovery 5: V values need FP8, not INT8. This was the final piece. K values flow through Q·Kᵀ into softmax—linear quantization error maps linearly to attention logits, so INT8’s uniform spacing works fine. But V values have heavy-tailed distributions in deeper layers. I borrowed the FP8-E4M3 encoding from Qwen’s quantization work (thanks to @QuixiAI for reverse engineering it, see link below). This datatype preserves relative precision across three orders of magnitude. The main idea for the RTX 3090: it has no FP8 hardware, but it can be emulated. Store FP8 bit patterns in INT8 bytes, then decode them in the Triton attention kernel. Same memory footprint, better precision where it matters.
What didn’t work:
- Native Triton FP8 (tl.float8e4nv): requires Ada/Hopper
- Disabling cascade attention: no effect, memory bandwidth is the bottleneck
- Piecewise CUDA graphs: OOM on 24 GB GPUs with TP=2
- Speculative decoding: draft model overhead exceeded gains
This wasn’t autoresearch in Karpathy’s sense , there was no training involved, also I did not setup a autoresearch prompt + loop. But the spirit was similar: iterative experimentation, let Opus write Triton kernels and systematic measurement. Claude helped me stay organized, generate hypotheses, and most importantly write the Triton kernels. The whole project took perhaps an hour of two of my time over the course of a week. The images show single-session inference speed with the 27B model, and batched inference with the 4B model.

English
@YebHavinga i got 1500tk/sec on 9b on one 3090. but your first 27b test seems right you should be able to split the cards and run bs=8 I think that would be the ultimate setup. 600-800watts 24/7 though
English
I (Claude :-) tested AWQ INT4 but it failed (torchao compatibility). The max batched tokens/s for 27B I tested was 244 tok/s. For smaller models (1B/4B) I got to 7-12K tok/s with DP=2 on two 3090's. Would be interested to learn more about the 500-1000 tokens/s config/hardware/model especially if that was with the dense 27b!
English

@neogoose_btw fuck, I'm part of the permanent underclass
English

I just want to remind the rest of the world: every single AI company here in Silicon Valley get tokens for absolutely free rn
It’s only you paying those 200$ for max plan
TFTC@TFTC21
Jensen Huang: "If that $500,000 engineer did not consume at least $250,000 worth of tokens, I am going to be deeply alarmed. This is no different than a chip designer who says 'I'm just going to use paper and pencil. I don't think I'm going to need any CAD tools.'"
English
@neogoose_btw if you are a $250k engineer and you don't get it for free, i'd be like what the fuck is wrong with you
English
fullstack retweeté

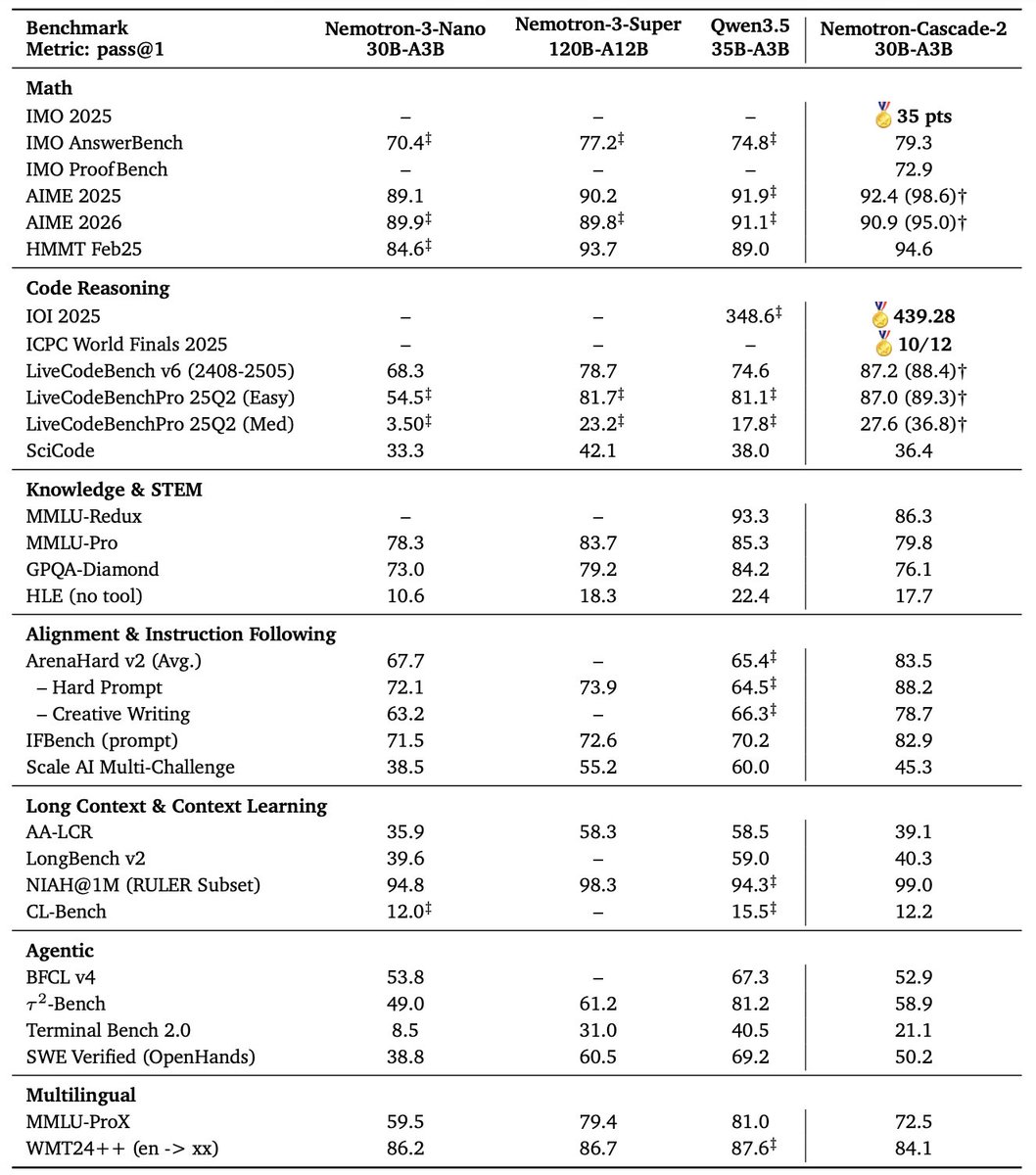
🚀 Introducing Nemotron-Cascade 2 🚀
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 huggingface.co/collections/nv…
📄 Technical report:
👉 research.nvidia.com/labs/nemotron/…
English
fullstack retweeté


fullstack retweeté



🇯🇵 We're going to revise the Japanese constitution and we're going to have an actual army.
There will be no more communism in East Asia.
English
@jakeshieldsajj it'll be $250/b and they'll print beast-bucks loaf of bread will be $1200.
English


prob the best marketer after Steve Jobs. maybe even better
sunny madra@sundeep
“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”
English
fullstack retweeté

"Not currently working, Italy"

Anthropic@AnthropicAI
We invited Claude users to share how they use AI, what they dream it could make possible, and what they fear it might do. Nearly 81,000 people responded in one week—the largest qualitative study of its kind. Read more: anthropic.com/features/81k-i…
English

Lately, Claude makes some shocking mistakes.
⟶ Implements overly complex code
⟶ Ignores the codebase's code style
⟶ Removes working code for no reason
⟶ Replaces code that's out of scope from the task at hand
It feels like it needs 100% supervision. At this point, you're better off writing everything yourself.

English


I think I have only used like $1000-$2000 of AI tokens total in my life so far. I guess Jensen would fire me.
TFTC@TFTC21
Jensen Huang: "If that $500,000 engineer did not consume at least $250,000 worth of tokens, I am going to be deeply alarmed. This is no different than a chip designer who says 'I'm just going to use paper and pencil. I don't think I'm going to need any CAD tools.'"
English
fullstack retweeté

fullstack retweeté



Oil tanker operator paid Iran $2,000,000 for safe passage through Strait of Hormuz, Financial Times reports.
English