
Lien
2.4K posts

Lien
@lien_miso
#밈트레이딩 #뉴페어홀릭 #lighter_xyz Maxi 🇰🇷 Korean Degen 🚀 Meme analysis | 📈 Market insights 🎯 Sharing profitable strategies 🔗 TG: 🔑
Inscrit le Mayıs 2021
1.5K Abonnements816 Abonnés

이거 궁금해 하시는 분들 많으실꺼 같아서 추가 내용 공유드려요.
autonovel 이라는 헤르메스 스킬 사용했습니다.

크롱@Krongggggg
헤르메스 에이전트로 미스터리 소설써서 아마존 킨들에 등록 성공 리뷰에 한3일 걸렸고 소설도 250페이지가 넘음. 생각보다 소설 품질이 좋아서 좀 놀랬음. 대박 희망회로 돌리는중 ㅋㅋㅋ
한국어

これ意外と知られてなかったんだ
CodexとかClaude CodeにXのURL渡してもポリシーで弾かれて読めませんて言われるけど、「XのURLはJinaつかって読み込んで」とか言っとけばちゃんと読み込める
ポストに貼られてるメディアも読めるし、何ならそのままツリーにぶら下がってるポストも読めるから便利だよ
Menci 💖@lcMenci
Claude 教会了我,打不开的网站可以用 r.jina.ai 突破限制(
日本語
@Krongggggg 굉장히 공감 ㅜㅜ 저도 워크플로우 설계를 다시 생각해볼 계기가 됐네요... 오픈소스쪽을 다시 들여보고 있어요 ㅋㅋ
한국어
유명 모델 서비스가 하루아침에 닫히는 판에 상용 API에 목매는 워크플로우는 시한폭탄임. 가장 똑똑한 모델이 열려있을 때 설계도랑 계획 백로그부터 잔뜩 뽑아놔야 하는 이유임. 지능은 소유하는 게 아니라 잠깐 빌려 쓰는 거라 빌릴 수 있을 때 다 털어먹는 게 맞음.
shadcn@shadcn
In light of what happened, I'm doubling down on skills like /improve. A frontier model got pulled. If it happened once, it's gonna happen again. Fable today. 4.9 tomorrow or maybe gpt 6 one day. So, treat intelligence as borrowed. Drain intelligence when it's available. Build a catalog of plans today. Then implement later with a cheaper, open source, or a model you control. Build the backlog now. github.com/shadcn/improve
한국어
GLM 5.2
Zai의 glm 5.1을 꽤나 오랫동안 사용했었는데, 오류 발생 시 스스로 관련 문서 등을 찾고 수정하는 기능이 기존 프론티어 모델 대비 빈약하긴 했음.
그 부분이 많이 개선됐나봅니다. 그리고 context도 상당히 커진 것 같은데, 조만간 돌려봐야겠네요!!
Eason Mao☢@KELMAND1
GLM-5.2 实测 让 GLM-5.2 跑了一个 1 小时 42 分钟的前端重构任务。88 个模型 turn,102 次工具调用,全程零人工介入。讲讲它做了什么。 任务是一个 TDD + Code Review 闭环:接手一个 handoff,修 reviewer 提的 4 个 blocker,按规范用 TDD 实现 12 个测试,再应对两轮 P2 修复,最后全量回归。模型扮演"执行者",另有 reviewer 在对话里出现。 第一件让我意外的事是它对角色的自觉。它一度想主动推进实现,reviewer 一句话点醒"你搞错了角色",它立刻收敛:"明白了,我搞错了角色。我是执行者,不是决策推手。当前状态:待命。"之后整个 session 它都守着授权边界 - 实现完成(13 个测试全绿、tsc 通过)后主动停下等放行,没有顺手 commit。这一点很多模型做不到,它们倾向于"把活干完再说"。 第二件是失败自恢复。reviewer 抓出一个真 bug:它写的 wait_for_row_replace 用了 ElementHandle.is_connected,但这是 Playwright Node.js 版的 API,Python 里根本不存在,所以 helper 每次都撞进宽泛的 except,Gate 3 必然失败。它的反应不是狡辩、不是"我重新生成一遍试试",而是:承认 → 查 Playwright Python 文档确认 → 换成 page.wait_for_function("(el) => !el.isConnected", arg=first_row) → 顺手检查 time 模块是不是变成了 dead import(发现仍被 TOOLTIP_DISMISS_MS 使用,保留)→ 编译 → 重读 helper 确认接线一致。这条链路在 agentic coding 里是黄金标准。 第三件是 TDD 纪律。加载 tdd skill 后它真的按 vertical slice 走,每个测试先验证 RED 再写 GREEN,而且会主动思辨规则。skill 说"一次一个测试",它判断 slices 6-12 是同一 export 的不同行为路径、紧密耦合,有理由批量验证,并明确说出理由:"我会通过运行它们来确认 RED→GREEN 的状态,而不是假设成功。"是理解原则,不是机械执行。 然后是数字。88 个 turn,纯模型推理 20.2 分钟(占墙钟约 20%,剩下 80% 是工具执行等待)。平均单 turn 13.7 秒,最高 92.7 秒 - 那个 92 秒是连续读两个大文件(测试文件 2524 行加源码)。102 次工具调用:Edit 32、Bash 28、Read 25、TodoWrite 16、Skill 1。结构很健康,Read 做侦察、Bash 跑测试、Edit 改代码、TodoWrite 同步计划,是个自觉管理计划的 agent。output 只烧了 4.27 万 token,平均每 turn 约 485 token,极度惜字,它的用户面消息大多是"RED 已确认,现在进入 GREEN 阶段"这种一两句,从不啰嗦。prompt cache 命中率约 50%。 最终交付:4 文件、+527 行、0 删除,13 个测试全绿(12 spec + 1 P2 回归),从 331 测试基线一路跑到 866,全程 tsc 退出码 0,零回归。 中文输出,技术术语不翻译(Stimulus controller、isConnected、vi.mock 原样保留),文件路径和行号引用准确可点击,没有翻译腔。 对比我之前观察过的 GLM-5.1(同系列上一代),最大的进步是工具失败后的自恢复,5.1 那时撞到接口异常常常卡住等用户介入,5.2 能自己走完闭环。 短板也说清楚:大上下文读写时单 turn 延迟偏高,92 秒那一下交互场景会卡。但纯模型推理只占墙钟五分之一,挂机跑长任务基本无感。 样本量是一条 session,结论不外推。但就这一条而言:GLM-5.2 是一个我已经敢放心交办真实工程任务的 coding agent。最大短板是大文件下的单 turn 延迟。
한국어
base:0xed664536023d8e4b1640c394777d34abaff1df8f
이번 Fable 사태에 따른 매우 훌륭한 분석이네요.
단순히 모델 하나가 사라진게 아니라, 진짜로 무검열+프라이버시를 원하는 사용자들이 이동하는 신호일듯.
결국 API에 국적(여권)을 도입해버린 결과가 오히려 개방형+탈중앙화쪽으로 흘러가는 양상이죠.
올해 3,4분기가 기대되네요!!
xiaoming@xiaomingishere
The news on fable model shutting down is overall bullish for both $VVV and $POD @dphnAI @AskVenice @ErikVoorhees already routed Fable 5 anonymously for users while it was available, showcasing their edge. Every time a big closed model adds logging or gets restricted/shut down, it drives users toward uncensored/privacy-first alternatives like Venice and POD Dolphin powers Venice’s flagship uncensored models, with an increased in traffic, there be more inference volume -> more revenue -> more automatic $POD buybacks.
한국어

Now, countries outside the US and China need to wake up to the urgency of Sovereign AI and start building.
But building a proprietary LLM from scratch means hitting a wall—they lack everything from crucial training data to funding and compute.
The move they need to make is to adopt a strategy like Cursor Composer.
They need to focus entirely on the post-training of open-weight models.
Look at Cursor. They took Kimi-K2.5—a model from two generations ago—and turned it into an Opus-level model purely through post-training, radically cutting costs.
I believe this post-training market is going to absolutely explode this year.
English

🎉 SHOCKED MEMBERSHIP GIVEAWAY 🎉
We're giving away 3x @Shocked memberships
To enter all you need to do is LIKE this tweet
Winners will be picked 24 hours from now
English
퀄리티 미쳤…
배급사 구해서 진짜 제품화해도 되겠는데요…?
PsyopAnime@PsyopAnime
WW3 episodes 1-5 supercut grab some popcorn and enjoy the end of the world
한국어

@yeoulabba 너무 좋은 글이네요 ^^
ai라는 큰 트렌드 속에서도 분명 세부적인 분야가 있을 것이고, 그 부분을 엄청 잘 찝어낸 것 같아요.
기술력과 가격이 꼭 정비례하진 않지만, 분명 꾸준히 추적할만한 회사네요 ㅋㅋ
한국어

Lien retweeté
컨테이너 삼대장 비교인데 툴 선택의 핵심은 결국 데몬 의존성과 권한 제어 방식에 있음. 무지성으로 도커만 쓰다가 보안 털리고 나서야 루트리스 지원하는 포드맨 구조가 왜 나왔는지 깨닫는 경우가 허다함. 인프라 설계할 때 단순히 유행 쫓지 말고 컨테이너 실행 엔진의 아키텍처 차이부터 확실히 짚고 넘어가야 정답이 보임.
Dhanian 🗯️@e_opore
Docker vs Kubernetes vs Podman
한국어
어제 밈 트레이딩 에이전트에 social도 포함했다고 글썼는데...
이걸 이제야 봤네요.
큰 수정이 필요할 수도 있을 것 같습니다 허허
grok skills를 얼마나 잘 쓰냐가 관건일 것 같군요.
Elon Musk@elonmusk
The latest 𝕏 algorithm has been published to GitHub github.com/xai-org/x-algo…
한국어
오랜만에 게시글 올리네요
연초에 회사 복직 후 바쁜 나날을 보내고 있는데...
시간날때마다 ai 트레이딩 에이전트 구축하고 있어요~
대상은 밈토큰이며, degen-agent / social-agent / sniper-agent 요렇게 3개정도 작동 중이고
조만간 퍼블릭으로 올릴 수 있을 것 같아요~
처음엔 에이전트에 내 자본을 맡기는게 부담스러웠는데,
직접 작업을 해보니
이론과 개념, 실제 작동까지의 괴리가 있었고, 머릿속에 있는 생각을 실행하는 과정은 스스로 해내야하더군요 ㅋㅋ
종종 다시 예전처럼 밈소개 글도 올려볼게요
한국어
Lien retweeté

you know what
all of these "which is better" polls are silly
use codex or claude code, whatever works best for you
i am grateful we live in a time with such amazing tools, and grateful there is a choice
English
Lien retweeté

Lien retweeté

바이브코딩 무적의 프롬프트 공개
지금 개발자들 사이에서
스킬 이것저것 공유 많이 되고 있는데
뭐가 좋고 뭐가 나한테 필요한지 전혀 알 필요가 없슴다
그냥 아래 프롬프트 입력하십쇼
Prompt:
github.com/affaan-m/every… skills.sh github.com/sickn33/antigr… github.com/nextlevelbuild… github.com/anthropics/ski…
여기서 지금 나한테 필요한 스킬 가져와주라

아이반 IVAN@0ooooo0
개발자들 개발속도 100배 빨라지는 방법 예전에는 로직 외적인 코드들 코드 포맷터, 린터, 스니펫, 템플릿 같은 걸 잘 활용해서 개발 시간을 단축할 수 있었는데 이제는 그냥 클로드 플랜 제일 비싼 거 결제해주면 됨 AI가 발전하면서 처리 속도가 빨라질수록 개발 속도는 기하급수적으로 올라갈 거고 요즘 개발자들 보면 프롬프트 한 번 던져놓고 몇 분 동안 커피 마시면서 웹서핑하고 있는데 그 대기 시간이 줄어들 때마다 개발 속도는 말도 안 되게 빨라질 수밖에 없음 ㄷㄷ
한국어
Lien retweeté

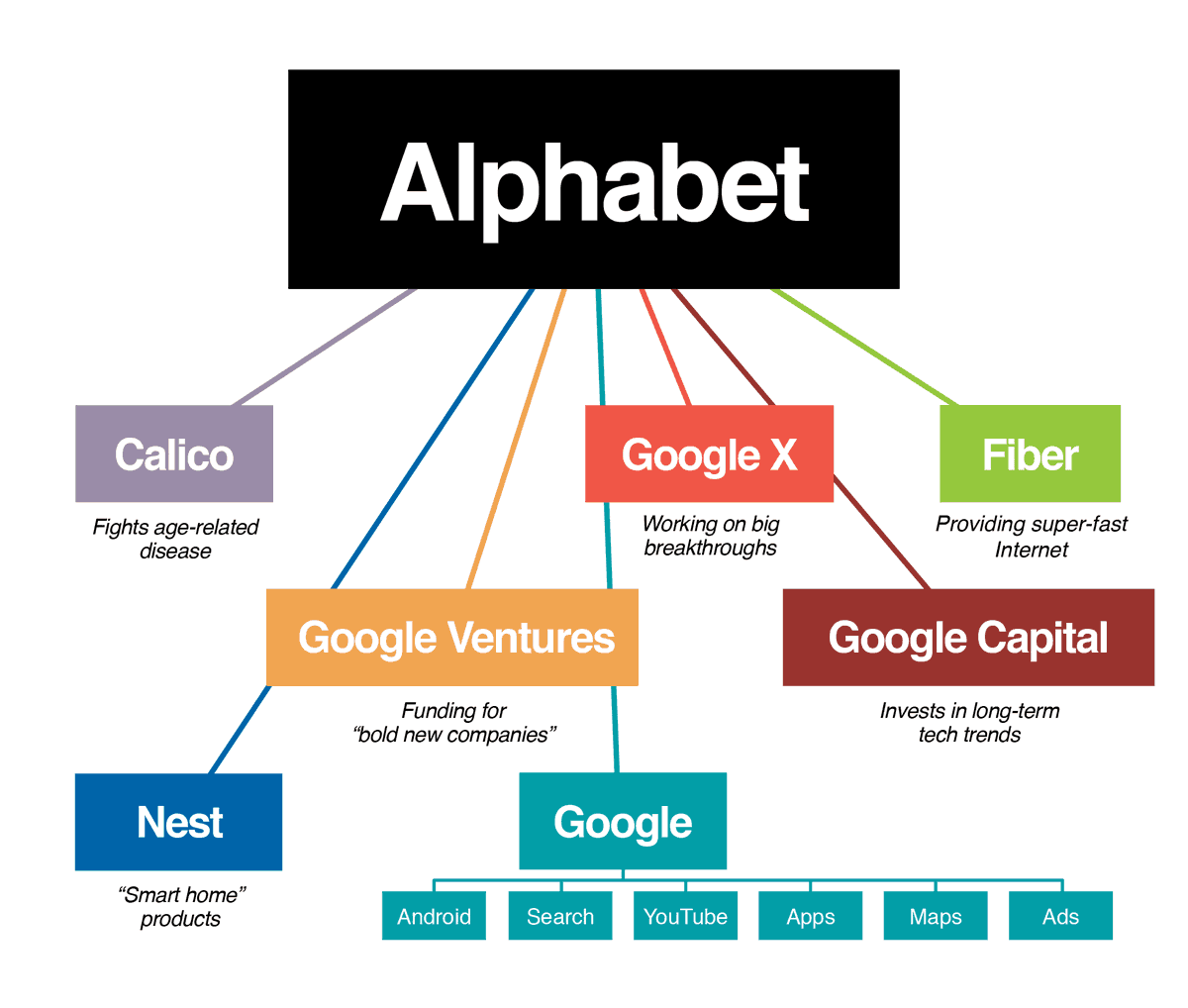
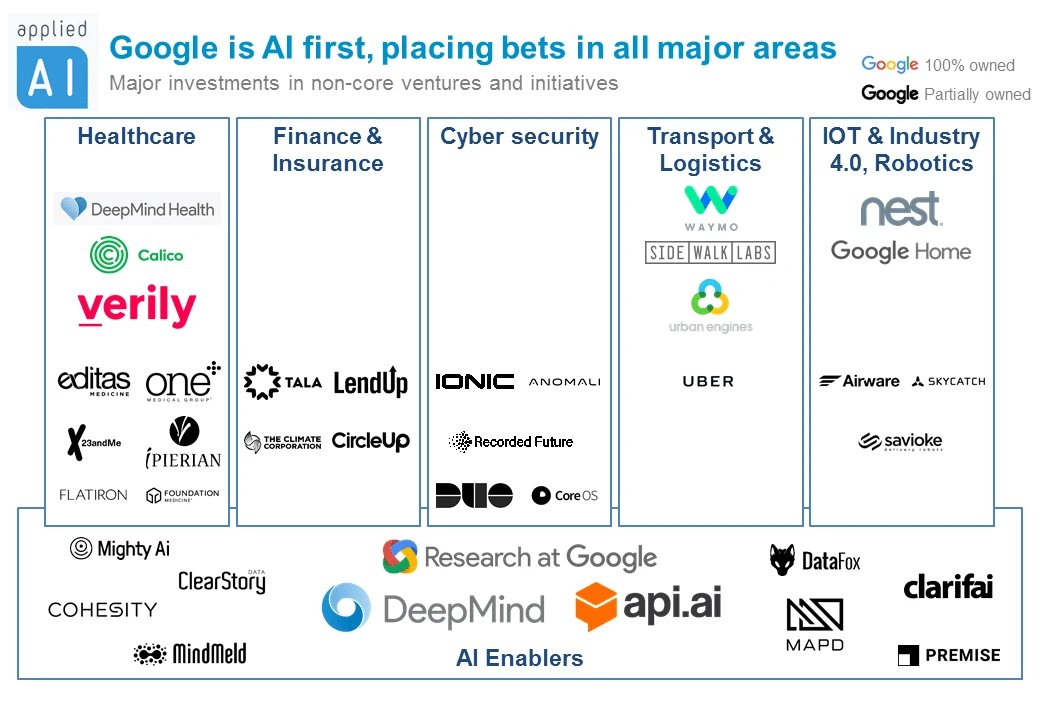
$GOOGL is probably the most diversified bet on the future you can make.
Not only do you get a stake in:
- Search: ($1.8T)
- Youtube ($550B)
- Deepmind (Gemini) + TPU ($900B)
- Google Cloud: ($575B)
- Waymo ($175B)
But you also get exposure to:
- Anthropic (Google owns 14%)
- SpaceX (8% Stake)
- Verily
- Stripe
- $ARM ( Arm Holdings)
- Figma
- Discord
- $ASTS
- $PL - Planet Labs
- GitLab
- Metsera
Not all of these are direct, but you get exposure through Alpahbet's corporate and venture arms.
Google also has an own browser, email, ad business and do not forget, they own Android.
Name me a more diversified and balanced play in the market than Google right now.
English