Dolphin Network - 2-week update
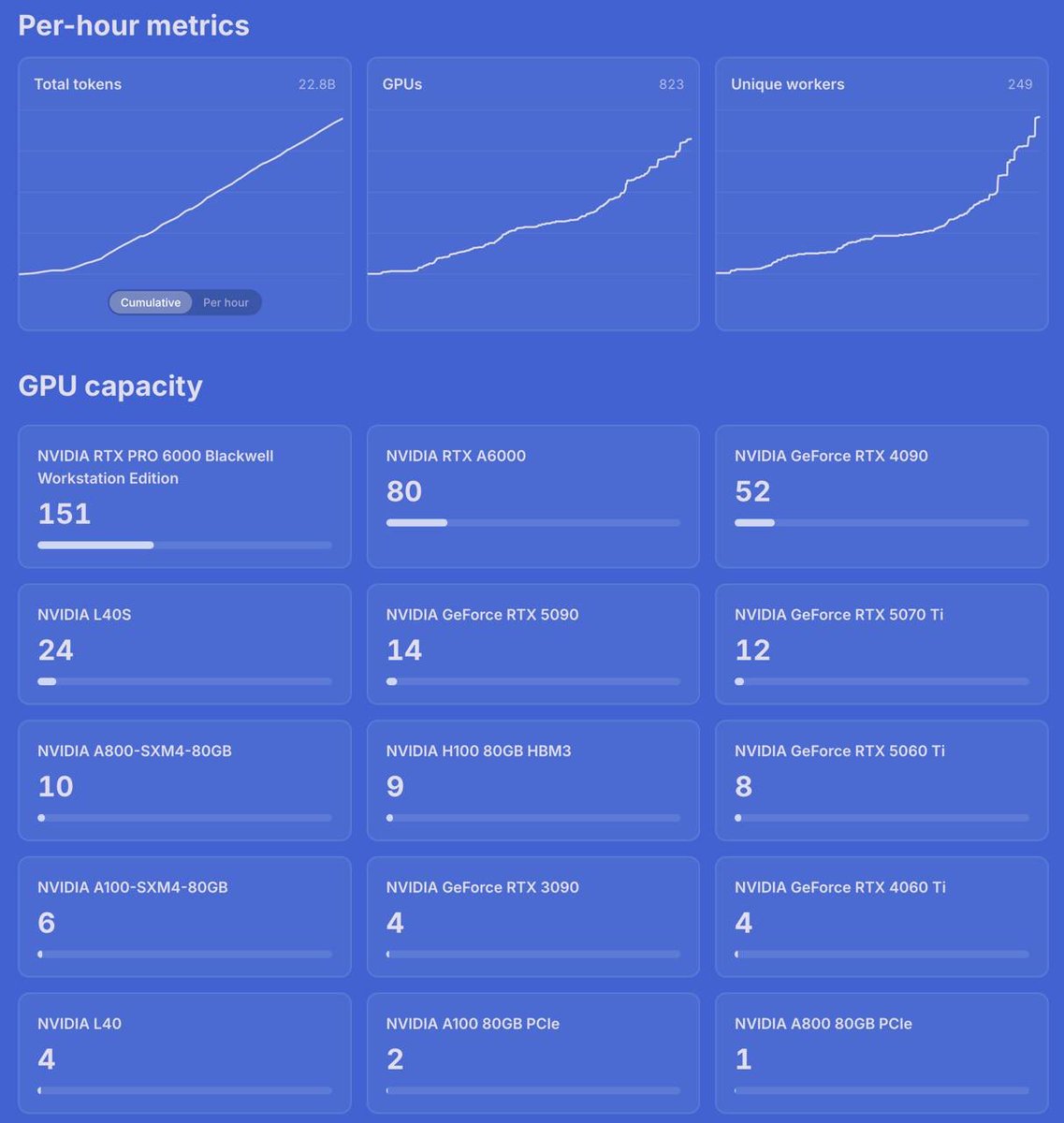
1.2 trillion tokens generated with Qwen 3.6 35B
Peak of 126B tokens per day & 1.8m tokens per second
1046 GPUs online now w/ 49 TB of aggregate VRAM
612 H100s worth of idle GPU memory repurposed for inference
datagen.dphn.ai

Dolphin@dphnAI
Dolphin Network V2 is live — our first major upgrade since launch The architecture was rebuilt from scratch in Golang -> - Auto-updates (no manual migrations) - NVFP4 as default on Blackwell GPUs - Higher utilization & network throughput via improved routing & load balancing
English