पिन किया गया ट्वीट
DataVoid
6.6K posts


DataVoid
@DataPlusEngine
Independent ML researcher. The First step in knowing is admitting you don't
https://discord.gg/KkKSVqU4Gs शामिल हुए Haziran 2023
617 फ़ॉलोइंग2.1K फ़ॉलोवर्स
DataVoid रीट्वीट किया

Cursor AI may be in material breach of contract with their new Composer model, which is generating buzz online for reportedly reaching Opus-level performance. It’s alleged that the new model is a fine-tuned checkpoint of Moonshot’s Kimi K2.5.
If true, the original model is licensed under a modified MIT license containing a clause restricting commercial use by products with over 100 million monthly active users or more than $20 million (or equivalent) in monthly revenue.
The requirement for triggering that clause is simply to prominently credit “Kimi K2.5” in the product or service’s UI.
Cursor could now face serious PR and legal issues simply because they couldn’t be bothered to cite the underlying team’s work. This is open-source 101....
Talk about being hoisted by your own petard.

English

DataVoid रीट्वीट किया

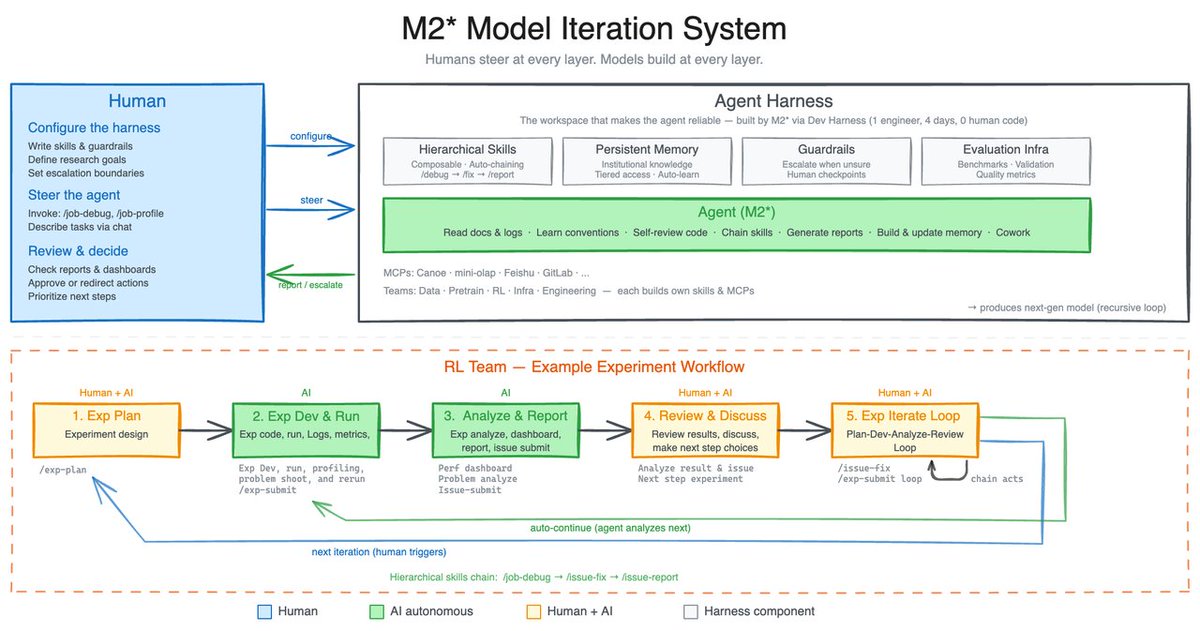
During the iteration process, we also realized that the model's ability to recursively evolve its harness is equally critical.
Our internal harness autonomously collects feedback, builds evaluation sets for internal tasks, and based on this continuously iterates on its own architecture, skills/MCP implementation, and memory mechanisms to complete tasks better and more efficiently.
English

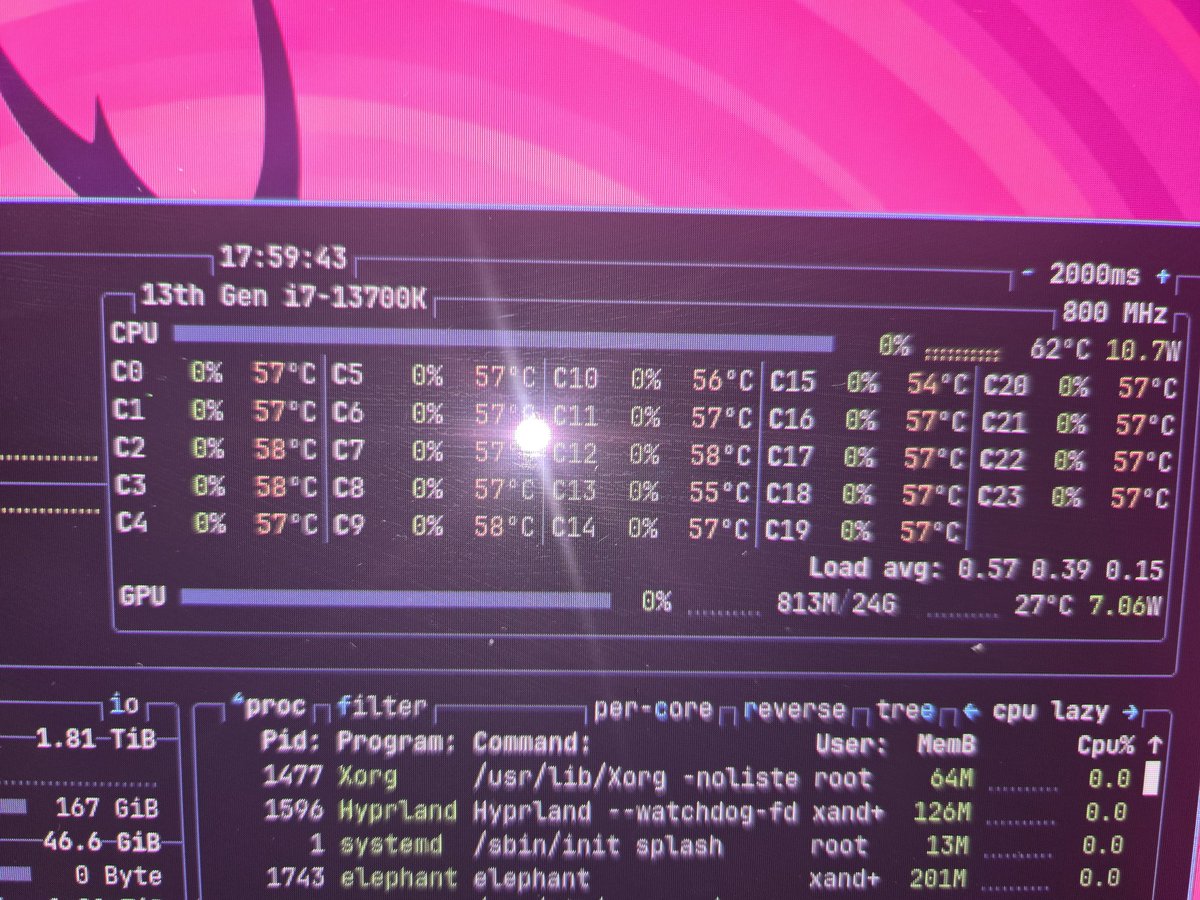
I pushed my tests to hard for Hermes-Agent and trashed my CPU somehow. Literally burnt it.
It's now 62ºc under no load and than overheats.
Oops lol
I got wayyyy to into Hermes dev. Props to @Teknium @NousResearch for making a project that has gotten me so enveloped.

English
@DavidSHolz @Angaisb_ I have said for years. Diffusion has a much more authentic feel than AR.
English


Midjourney should have gone full AR and left diffusion behind
They had the data, the compute and the talent yet somehow they still managed to become irrelevant. This isn't any better than older Midjourney models
Sad to watch a company I genuinely liked fade out in real time

Mark Kretschmann@mark_k
The long-awaited testing phase for @Midjourney V8 has officially begun, marking a massive leap forward for the generative art platform. This latest iteration promises a significant boost in efficiency, operating at five times the speed of its predecessors while maintaining a much tighter grip on complex prompt instructions. High-resolution creators will find the native 2K modes particularly useful for professional workflows. The update also brings more reliable text rendering and enhanced "sref" styling, allowing for a level of aesthetic consistency that was previously difficult to achieve. Personalization is a major focus of this release, with improved moodboard performance to help users fine-tune their unique visual language. It is an impressive step toward making AI-assisted design both faster and more intuitive.
English
@PurzBeats I am not a Nitro user and I haven't seen a single ad to date
English

DataVoid रीट्वीट किया

𝗞-𝗺𝗲𝗮𝗻𝘀 𝗶𝘀 𝘀𝗶𝗺𝗽𝗹𝗲. 𝗠𝗮𝗸𝗶𝗻𝗴 𝗶𝘁 𝗳𝗮𝘀𝘁 𝗼𝗻 𝗚𝗣𝗨𝘀 𝗶𝘀𝗻’𝘁.
That’s why we built Flash-KMeans — an IO-aware implementation of exact k-means that rethinks the algorithm around modern GPU bottlenecks.
By attacking the memory bottlenecks directly, Flash-KMeans achieves 30x speedup over cuML and 200x speedup over FAISS — with the same exact algorithm, just engineered for today’s hardware. At the million-scale, Flash-KMeans can complete a k-means iteration in milliseconds.
A classic algorithm — redesigned for modern GPUs.
Paper: arxiv.org/abs/2603.09229
Code: github.com/svg-project/fl…
English
DataVoid रीट्वीट किया

ByteDance also implemented attention over depth. They literally combined it with sequence attention.

English

Hermes Agent v0.3.0 ☤
248 PRs. 15 contributors. 5 days.
• Real-time streaming across CLI and all platforms
• First-class plugin architecture, package and share tools+commands+skills
• /browser connect to live Chrome via CDP
• @vercel AI Gateway model provider
• @browser_use browser tool provider
• VS Code, Zed, and JetBrains integration
• Voice mode with local Whisper
• PII redaction everywhere
9 new skills. 50+ bug fixes. Much more in the full changelog.

English
@Rahmeljackson @beyond_fps Only if they open source it. Which they haven't done for a single previous version to date
English

@beyond_fps Image model can look however way you want.
I think when this releases were going to see different variations and styles like current image models do now.
English

All these DLSS 5 screens look the same. Increased brightness, contrast, saturation, lower color temperature.
No matter what game you play now it all looks the same.
Jacob Freeman@GeForce_JacobF
DLSS 5 in Assassin's Creed Shadows 👀
English
DataVoid रीट्वीट किया

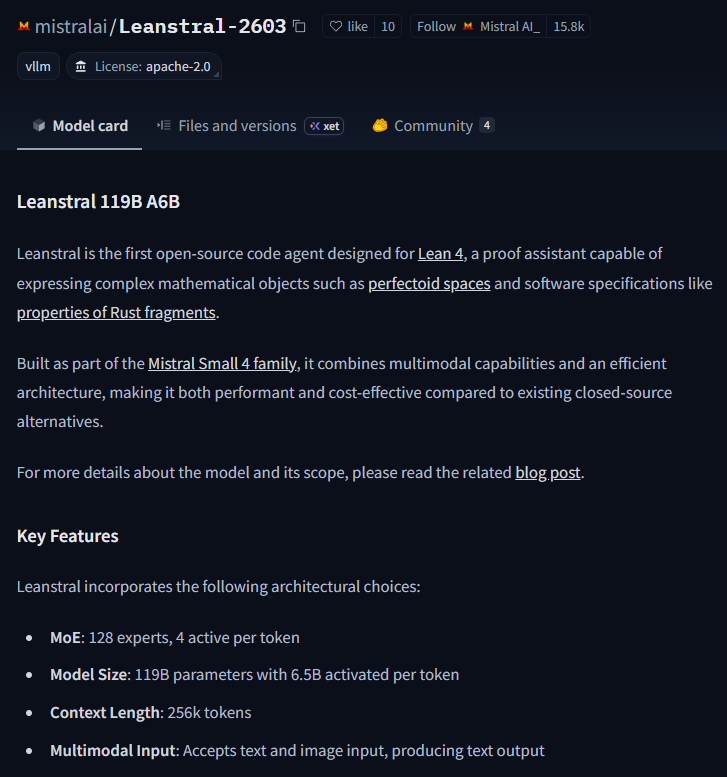
Leanstral is part of the Mistral Small 4 family
Lisan al Gaib@scaling01
Some math prover model by Mistral? link is dead again, just got the notif
English

DataVoid रीट्वीट किया

DataVoid रीट्वीट किया

If you can internalize what this plot means, how to make it, and why it's important you can get a job at any top lab
Kimi.ai@Kimi_Moonshot
Scaling law experiments reveal a consistent 1.25× compute advantage across varying model sizes.
English
DataVoid रीट्वीट किया

Holy: Kimi did an amazing work because it changes one of the most basic parts of how deep AI models pass information from layer to layer.
Instead of blindly mixing in everything from earlier layers equally, the model can now choose which past information is actually useful for each token and task.
That helps deep models keep important signals from getting washed out, making training more stable and efficient.
The big deal is that Kimi shows this idea works at scale too: better results, about 25% more compute efficiency, and almost no extra inference slowdown.

Kimi.ai@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
English
@Kimi_Moonshot Played around with something similar a while ago.
Similar idea. Different application
github.com/DataCTE/orthog…
English

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Att…

English