Sabitlenmiş Tweet
DataVoid
6.8K posts


DataVoid
@DataPlusEngine
Independent ML researcher. The First step in knowing is admitting you don't
https://discord.gg/KkKSVqU4Gs Katılım Haziran 2023
633 Takip Edilen2.1K Takipçiler
@pretendsmarts @RivraDev Thank you! It's not clear that this tag exists, I assumed it would be like the articles and models with separate tabs
English

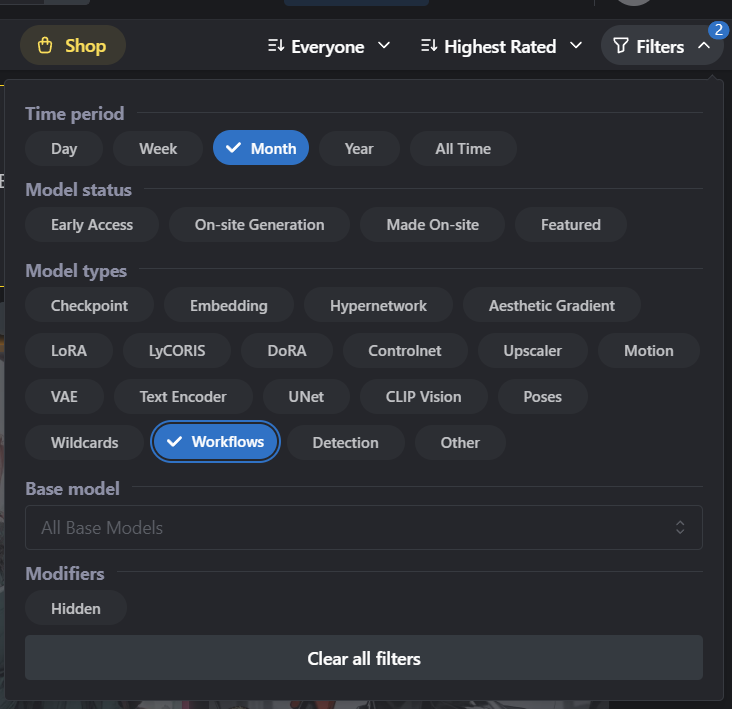
@pretendsmarts @RivraDev Agreed, a small amount of the old workflows are present there but most are still lost it seems. Also, they don't have a category for workflows so its a pain to search for on their website
English
@DataPlusEngine @RivraDev civitai?
not meant as primarily for comfy workflows, but seems like there are a lot of WF there
English
@crystalwizard I haven't been paying attention lately, I didn't even notice that damn. They completely redesigned it again!
English

yeah, comfy is pissing a lot of people off, the new version doesn't work with most of the old workflows, so why bother having a site with stuff no one can use
DataVoid@DataPlusEngine
I have just noticed quite litearlly 100% of the ComfyUI workflow websites are gone. OpenArt does not have it anymore, Comfy Workflows is gone, and esheep is gone,
English
@migtissera exactly! What I am doing right as of this moment. its ticking me off because i need some of those resources for a project i am working on.
GIF
English

@DataPlusEngine Seems like an opportunity for you to build a site!
English
Agreed absolutely, but from what I see, you require direct access from the website curators to upload workflows, and the collection they have is extremely small. Almost less than 100 workflows.
The vast majority of the resources are still just flat out gone from a platform like this
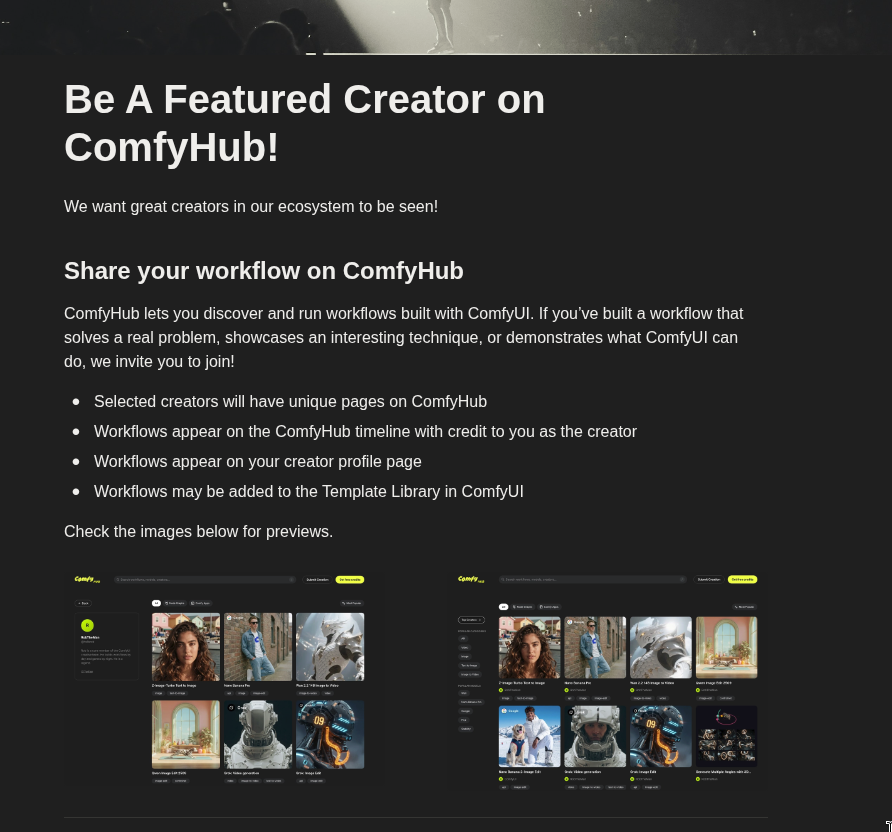
English
The largest AI image and video generation local platform. It's the equivalent of oogabooga/llama.cpp/vllm for video and image modalities.
It would be like that r/localllama just got whipped one day. all of those community resources, problem-solving, system prompts, and projects. just *poof* disappeared one night. (since most of the workflows were not shared via Reddit)
pretty big deal
English
All of the sites that the community used to use to share ComfyUI workflows, their projects, etc, are just gone.
meaning tens of thousands of workflows that you could use for your own projects and ask questions on if you run into issues, are no longer available. Everyone used those sites, and the workflows were rarely shared elsewhere. So they are flat out inaccessible.
For instance, high-quality IP-adapter workflows are borderline unfindable now
English
@DataPlusEngine I didn’t understand a single thing here my guy.. what are these things??
English

@DataPlusEngine Wait they are gone??? That's a shame. OpenArt comfyui wf gallery was just fun to browse through.
English
@RivraDev No it doesn't make them redundant because I can't find a single workflow.
From what I see all shared workflows have just be whipped clean off the internet.
I am going to make my own website for this because everyone involved seems to be heavily mentally impaired
English

@DataPlusEngine This tracks with a broader pattern: workflow marketplaces die when the underlying tool gets stable enough that people build internally instead of sharing. ComfyUI's own node registry might be making third-party galleries redundant.
English

Anthropic pays $750K/ year per senior engineer.
The creator of Claude Code just revealed his coding setup at the Sequoia AI session.
Boris Cherny: "100% of my code is written by Claude Code. I run around 100 agents at one time."
free. 24 minutes. watch it
then read article below
Movez@0xMovez
English

My first public website: ytfinder.app
I think this tool is very much needed these days, and i could not find one like it.
GIF
English
DataVoid retweetledi

I have met with many companies that heavily benefit from my work to discuss the possibility of them supporting me. They frequently commit to do so, but they almost never do. When most companies "support open source", what they mean is they like profiting off it for free.
English


Over the past month, some of you reported Claude Code's quality had slipped. We investigated, and published a post-mortem on the three issues we found.
All are fixed in v2.1.116+ and we’ve reset usage limits for all subscribers.
English
DataVoid retweetledi

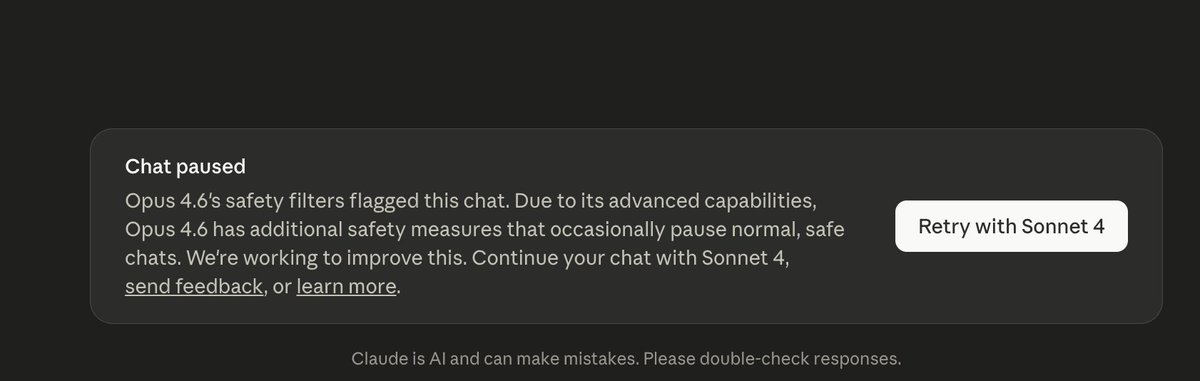
DataVoid retweetledi
I can't even do basic cryptographic challenges with Opus. I get that they're trying to limit it for safety but this is insane

English

