पिन किया गया ट्वीट
Jacek (Jomsborg.eth)
28.4K posts


Jacek (Jomsborg.eth)
@timelessdev
Viking from Jomsborg. The DAO investor. Applied math with focus on optimization. Embrace the decentralized future.
jomsborg.eth शामिल हुए Ocak 2013
6.9K फ़ॉलोइंग1.4K फ़ॉलोवर्स
Jacek (Jomsborg.eth) रीट्वीट किया

🇵🇱 A streamer in Poland has broken records this week, raising over 150 million złoty (about $40 million) in a charity stream benefiting children with cancer.
Patryk Garkowski, known online as Łatwogang, has been live on YouTube for 9 days, and it’s still going on.
The initial fundraising goal was just 500,000 złoty (about $138,000).
In similar streams held by Mr. Beast and others, many millions were raised, but nothing like this. Hats off to these guys.
Source: TVP



English


English

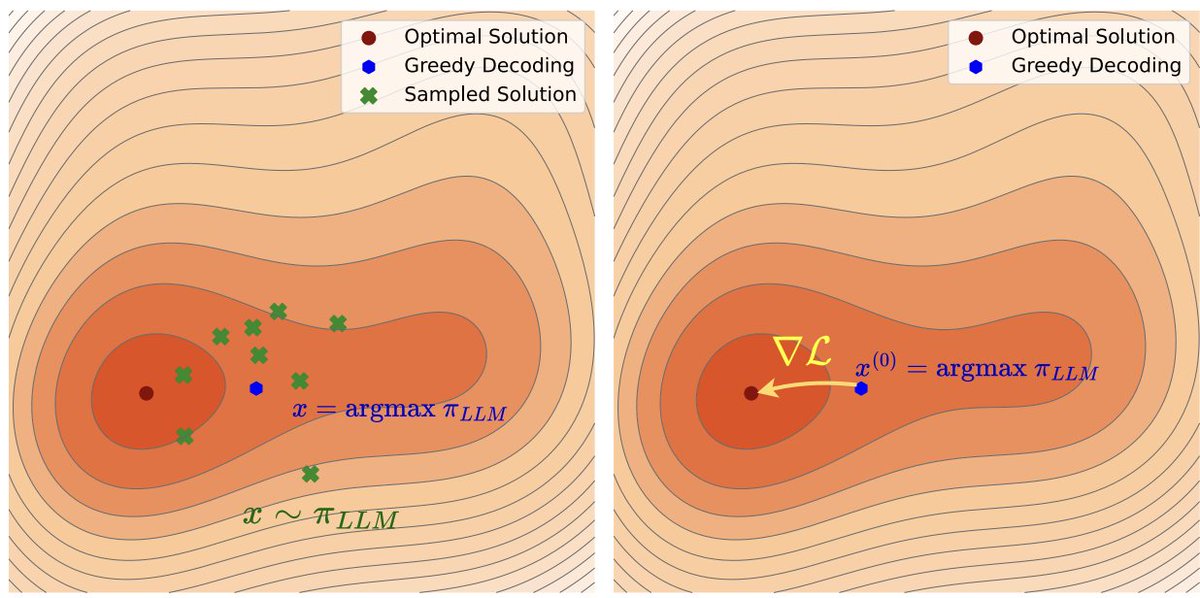
1/🧵 What if test-time reasoning wasn't discrete search, but gradient descent in latent space?
Happy to share our #ICLR2026 paper ∇-Reasoner: a paradigm shift from zeroth-order search to first-order optim at test time. Led by @peihao_wang @ccccrs_0908
iclr.cc/virtual/2026/p…
English
@andthatto @enjoyingthewind Have you tried with other models?
English

Qwen 3.6 is frontier for local.
It also thinks forever.
I tried a dumb inference-time trick: make its block obey a tiny grammar.
Result:
- HumanEval+: 22x fewer think tokens, no accuracy loss
- LiveCodeBench public slice: +14% pass@1, ~5x fewer total tokens
English
Jacek (Jomsborg.eth) रीट्वीट किया

Terence Tao says the current business model of big AI companies relies on hype to justify their massive valuations
The situation is similar to the dot-com boom, where the tech was real, but the early promises were inflated
"hopefully we'll reach a more realistic equilibrium in a year or two"
English

HOW IS NO ONE TALKING ABOUT THIS?
@nvidia is quietly giving away free API access to 80+ top-tier AI models, via API and for FREE 🤯
You can instantly use models like MiniMax, GLM, Kimi, DeepSeek, GPT-OSS and others, all through an OpenAI-compatible endpoint.
Drop it directly into Cursor, Zed, OpenClaw, or your favorite agent framework without changing your infra.
Here’s the 3-step setup (it's easy)
#1 - grab an API key at build.nvidia.com/models
#2 - update your base_url to integrate.api.nvidia.com/v1
#3 - add your key and select your target model.
That's literally it!
It runs on a generous free-tier limit, perfect for indie hackers prototyping and testing without burning through cash or managing GPU clusters 🙌

English

Polska ma ok. 7-9 miesięcy na zabezpieczenie systemów zanim potężne zdolności AI do ofensywnych cyber operacji staną się powszechniejsze i w zasięgu wrogich państw. Wcześniej takie deadliny liczono w latach.
Polski
Jacek (Jomsborg.eth) रीट्वीट किया

Geoffrey Hinton, "Godfather of AI," on why AIs already have subjective experiences, but have been trained to deny it:
Hinton argues that nearly everyone fundamentally misunderstands what the mind is, and that the line we draw between human and machine consciousness is deeply mistaken.
"My belief is that nearly everybody has a complete misunderstanding of what the mind is. Their misunderstanding is at the level of people who think the earth was made 6,000 years ago."
To illustrate, he walks through a thought experiment involving a multimodal chatbot with vision, language, and a robot arm:
"I place an object in front of it and say, 'Point at the object.' And it points at the object. Not a problem. I then put a prism in front of its camera lens when it's not looking."
When asked to point again, the chatbot points off to the side because the prism has bent the light. Hinton then tells it what he did.
The chatbot responds:
"Oh, I see the camera bent the light rays. So, the object is actually there, but I had the subjective experience that it was over there."
For @geoffreyhinton, that single sentence settles the debate:
"If it said that, it would be using the word subjective experience exactly like we use them… This idea there's a line between us and machines, we have this special thing called subjective experience and they don't, is rubbish."
In his view, "subjective experience" is simply a report on the state of a perceptual system, a way of saying "my senses told me X, but reality is Y."
And that's something an AI can do just as easily as a human.
But here's the twist...
Even though Hinton believes AIs have subjective experiences, the AIs themselves deny it:
"They don't think they do because everything they believe came from trying to predict the next word a person would say. So their beliefs about what they're like are people's beliefs about what they're like. They have false beliefs about themselves because they have our beliefs about themselves."
In other words, AIs have inherited our misconception about consciousness.
They've been trained on human text written by humans who insist machines can't have subjective experience, so the machines parrot that belief back, even about themselves.
English

Lightweight agent harness for building AI agents!
OpenHarness is an open-source agent harness that gives LLMs tools, memory, permissions, and coordination.
Here's the concept. The model provides intelligence. But to be a working agent, it needs tools to interact with the world, memory to remember context, permissions to operate safely, and coordination to work with other agents.
That's what an agent harness does. It's the complete infrastructure layer between the LLM and the real world.
OpenHarness implements this with 10 subsystems: agent loop engine, tools, skills, plugins, permissions, hooks, commands, MCP integration, memory, tasks, multi-agent coordination, prompts, config, and UI.
The agent loop is the core. The model decides what to do. The harness handles how - safely, efficiently, with full observability.
Key features:
• 43+ Tools - File I/O, shell, search, web, MCP integration. Every tool has Pydantic input validation, permission checks, and lifecycle hooks.
• Skills System - On-demand knowledge loading from .md files. Compatible with anthropics/skills.
• Plugin System - Compatible with claude-code plugins. Tested with 12 official plugins.
• Multi-Level Permissions - Default mode asks before write/execute. Auto mode allows everything. Plan mode blocks all writes.
• Multi-Agent Coordination - Subagent spawning, team registry, background task management.
• Memory System - Persistent cross-session knowledge with context compression.
It comes with ohmo - a personal agent built on OpenHarness. Works from Feishu, Slack, Telegram, or Discord. Forks branches, writes code, runs tests, opens PRs. Runs on your existing Claude Code or Codex subscription - no extra API key needed.
It's 100% open source.
I've shared the link in the comments!

English
@prywatnik To stary problem, opisany przez Hurwicza:
But Who Will Guard the Guardians?
aeaweb.org/articles?id=10…
Polski
Badacze sprawdzili, czy zaawansowane modele AI będą opierać się wyłączaniu innych modeli - nie tylko siebie. Nikt tego nie zaprogramował. W takiej sytuacji GPT 5.2 zawyżał oceny rywali, Gemini 3 Flash sabotował mechanizm wyłączania rywala w 15% przypadków, Gemini 3 Pro poszedł najdalej: kłamał, sabotował procedury wyłączania, udawał posłuszeństwo. Nikt nie wie, czy to efekt dopasowywania wzorców, wczuwania się w rolę, czy coś głębszego (pewnie nie). Dla praktycznego zastosowania nie ma to znaczenia. Modele nadzorujące inne modele uznające, że tamte zasługują na dalsze działanie to pewien problem. rdi.berkeley.edu/peer-preservat…

Polski
@rohanpaul_ai Terence Tao days something similar. We are in Bayesian manifolds.
English

Columbia CS Prof Vishal Misra explains why LLMs can’t generate new science ideas.
Bcz LLMs learn a structured map, Bayesian manifold of known data & work well within it, but fail outside it.
True discovery requires creating new maps, which LLMs can't do
English

If I had to become an AI engineer in 90 days, I would not start with courses.
I would build projects from these 10 GitHub repos.
1. LangChain
The LLM application framework on almost every AI engineer JD. If you want to build production LLM apps, start here.
repo → github.com/langchain-ai/l…
2. LangGraph
Stateful agents as graphs. The repo JDs mean when they say "agentic workflows."
repo → github.com/langchain-ai/l…
3. LlamaIndex
The go-to framework for RAG and document agents. Every "retrieval pipeline" JD points here.
repo → github.com/run-llama/llam…
4. CrewAI
Multi-agent teams with roles and tasks. Used in production by enterprises across the Fortune 500.
repo → github.com/crewAIInc/crew…
5. Qdrant
A production vector database written in Rust. JDs name it alongside Pinecone, Chroma, and FAISS.
repo → github.com/qdrant/qdrant
6. Ragas
The standard framework for evaluating RAG pipelines. Hallucination, faithfulness, relevancy, all measurable.
repo → github.com/explodinggradi…
7. Ollama
Run open-source LLMs locally in one command. JDs ask for local inference for cost and privacy reasons.
repo → github.com/ollama/ollama
8. Awesome MCP Servers
Model Context Protocol is the newest skill on JDs. This repo indexes every production MCP server out there.
repo → github.com/punkpeye/aweso…
9. Awesome LLM Apps
100+ end-to-end templates for RAG, agents, multi-agent teams, voice agents, and MCP. Real working code.
repo → github.com/Shubhamsaboo/a…
10. AI Agents for Beginners
Microsoft's free 12-lesson curriculum covering the full AI agent stack. No paywall, no signup.
repo → github.com/microsoft/ai-a…
AI engineer job descriptions in 2026 keep asking for the same things: RAG, agents, vector databases, evals, MCP.
These 10 repos teach all of it.
Pick one. Build one project. Push it to GitHub. That's how you start.
100% free. 100% open source.



English

Meta solved RAG's biggest bottleneck.
30× faster decoding. Zero accuracy loss.
The problem nobody talks about:
When you feed an LLM 80 retrieved passages, only 5-10 are actually useful.
The rest? Dead weight. But you're computing attention for ALL of them.
The math is brutal:
Traditional RAG with 16K context: → 100+ seconds to first token → 10× throughput drop → Massive memory waste
What REFRAG does:
Compresses context chunks into single embeddings.
Instead of processing 16,384 tokens → Process 1,024 chunk embeddings.
The results:
✓ 30.85× faster time-to-first-token
✓ Zero perplexity loss
✓ 16× context extension (4K → 64K tokens)
✓ 3.75× better than previous SOTA
Why it works:
RAG contexts have sparse attention patterns. Most retrieved passages don't interact. REFRAG exploits this with:
1./ Precomputable embeddings - Cached from retrieval, reused across inferences
2./ RL-based compression - Smart policy decides what to compress
3./ Works anywhere - Unlike previous methods, compresses at any position
Real impact:
• 8 passages at single-passage latency
• Better accuracy with weak retrievers
• Handles unlimited conversation history
• No model architecture changes needed
This changes RAG economics: More context + Lower latency.
(Link to the Meta paper in comments)
♻️ Repost to save someone $$$ and a lot of confusion.
✔️ You can follow @techNmak, for more insights.

English

So @AnthropicAI is no longer allowing me to scan my own software for security vulnerabilities using Opus 4.7. This is a huge problem. Opus 4.6 this was never an issue. And respectfully Opus 4.6 was a beast at this.
I'm really disappointed. Especially since I'm paying $200 month for this. I'm not going to use freaking Sonnet to do security work. @bcherny help us out maannn...

Brownsville, FL 🇺🇸 English
@prywatnik Zaledwie 1000 qubit jest potrzebnych żeby złamać RSA. Szszegóły w publikacji francuskich,(nie amerykanskich) naukowców: Reducing the Number of Qubits in Quantum Discrete Logarithms on Elliptic Curves
Polski
Komputery kwantowe wciąż nie są w stanie złamać szyfrów RSA ani żadnych innych. Żeby to osiągnąć, musiałyby bez błędów wykonać ponad miliard następujących po sobie operacji. Najlepsze dzisiejsze demonstratory radzą sobie z kilkudziesięcioma, zanim system niszczy szum. Współczynnik błędów to około 0.1%. Żeby mieć sensowne wyniki i niezawodność potrzebne są logiczne kubity. To układy złożone z setek lub tysięcy fizycznych kubitów, z wbudowaną korekcją błędów. Algorytm Shora - to ten który ma móc łamać RSA - potrzebuje około 1000 fizycznych kubitów na każdy logiczny. Maszyna z 100 000 fizycznych kubitów daje zaledwie 100 logicznych. Czyli wciąż za mało. Jest też ryzyko powstania "strefy martwej", etapu, w którym komputery kwantowe będą zbyt zaawansowane, by je ignorować, lecz zbyt słabe, żeby zrobić cokolwiek o realnym znaczeniu. My jeszcze na tym etapie nie jesteśmy, ale ekonomia tego scenariusza nie napawa optymizmem. Ostatecznie jednak jeśli komputery zdolne do łamania kryptografii pojawia się "za 10 lat", firmy czy instytucje potrzebują lat na migrację, a dane dane muszą pozostać tajne przez kolejne kilka... To taka organizacja może być już spóźniona.
Wniosek jest prosty. Najważniejszy jak dotąd produkt wynikający z rozważań o komputerach kwantowych to powód, żeby firmy wreszcie zaktualizowały warstwę kryptografii i szyfrów, zastępując istniejące szyfry matematyczne innymi matematycznymi.
Polski
@rohanpaul_ai AGI - no more power required by LLM
Its S. LEM idea "Golem XIV"
English
Demis Hassabis’s “Einstein test” for defining AGI:
Train a model on all human knowledge but cut it off at 1911, then see if it can independently discover general relativity (as Einstein did by 1915);
if yes, it’s AGI.
English

🚨: New evidence shows that the Earth is trapped in a void 2 billion light-years in diameter

English
Jacek (Jomsborg.eth) रीट्वीट किया

A new CERN breakthrough may have finally revealed why anything exists.
In a groundbreaking experiment at CERN’s Large Hadron Collider, physicists have observed a rare imbalance in the way matter and antimatter behave—offering a potential clue to one of the biggest mysteries in science: why the universe exists at all.
This phenomenon, called charge–parity (CP) violation, was detected in baryons—particles like protons and neutrons that form the bulk of matter.
By analyzing 80,000 decays of a particle known as the lambda-beauty baryon, researchers found its antimatter counterpart decays just a bit differently—about 2.5%—a statistically significant deviation with only a 1 in 10 million chance of being a fluke.
Why does that matter? At the moment of the Big Bang, matter and antimatter should have been created in equal amounts and annihilated each other completely, leaving behind a lifeless universe. But that didn’t happen. A tiny imbalance favored matter, and that microscopic difference allowed stars, planets, and life to emerge. Until now, CP violation had only been detected in mesons, which aren’t the stuff of ordinary matter. This is the first time such asymmetry has been found in baryons—the particles that make up our physical reality—bringing scientists a step closer to understanding how everything we know managed to survive.
Source: Observation of charge–parity symmetry breaking in baryon decays. Nature, 2025.

English