
Alexander Richard
46 posts
Alexander Richard
@AlexRichardCS
I'm a research scientist @Meta in Pittsburgh where I work on audio-visual modeling for photorealistic avatars.
Bergabung Haziran 2020
172 Mengikuti739 Pengikut
‼️500h of 3D motion data released‼️
Our team at the Codec Avatars Lab just released a large scale dataset of 3D tracked human motion, including audio and text annotations. Check it out here: meta.com/emerging-tech/…
English
Join our team for an internship in 2025!
Michael Zollhoefer@MZollhoefer
Looking for a research internship in 2025? The Social AI Research group at Meta’s Codec Avatars Lab in Pittsburgh is offering topics such as neural rendering, body tracking, motion synthesis, and animation from multimodal sensor inputs. Link: metacareers.com/jobs/822652889…
English
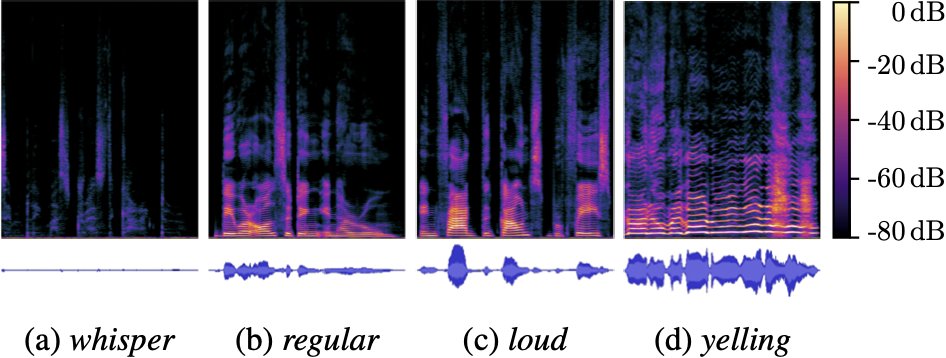
Working on your next big speech paper but still looking for a suitable dataset?
Check out EARS: 100h of full-band expressive, anechoic recordings of speech from 107 speakers with 22 different emotions, 7 different reading styles, and more.
sp-uhh.github.io/ears_dataset/
English
Alexander Richard me-retweet

If you're at #CVPR2024 this week, don't miss talking to @AlexRichardCS we are hiring for postdoctoral and full time positions! metacareers.com/jobs/380024285… metacareers.com/jobs/803309161…
English
Alexander Richard me-retweet

Want to make computers that can see *and* hear? Come to the Sight and Sound workshop on Monday, 6/17 at #CVPR2024!
Schedule: sightsound.org
Invited talks by:
@HildeKuehne, @ShyamGollakota, @RuohanGao1, @TengdaHan, @SamuelPClarke, @AlexRichardCS

English
Alexander Richard me-retweet

📢Curious about the future of 3D scene understanding? Join us at the 1st Workshop on Multimodalities for 3D Scenes @CVPR! Learn about the latest research on using vision, audio, touch, and language to understand 3D scenes around us.
📅June 17, 1:30-5:20PM
multimodalitiesfor3dscenes.github.io

English
Alexander Richard me-retweet
We have 4 amazing speakers (@xiaolonw, @andrewhowens, @KaterinaFragiad, Linda Smith) to cover different modalities, from vision, language, robotics, touch, and cognitive science.
Co-organizing with Angel Chang, @_krishna_murthy, @AlexRichardCS, Kristen Grauman.
#AI #CVPR
English
Real Acoustic Fields are here!
Check out or dataset of densely captured room impulse responses paired with multi-view images! See you all on CVPR :)
project page: facebookresearch.github.io/real-acoustic-…
arxiv: arxiv.org/abs/2403.18821

English
Alexander Richard me-retweet




@angrypenguinPNG @_akhaliq Nice. As Mentioned in the google collab, lip sync gets significantly better if you have at least 10 seconds of audio :)
English

Quick test of Meta's Photoreal Embodiment 🤖
Audio to Synthesized Human Movement in under 10 mins ⚡️
Weights, Code, and Dataset: github.com/facebookresear…
English
@danveloper The restriction comes from our data collection: we only train on dyadic conversations, so the model has never seen 3+ people in the same environment.
English

@AlexRichardCS This is really cool, Alex! Is the reason it’s constrained to dyadic conversation because of speaker diarization problems across a long running conversation?
English
Motion generation for photorealistic avatars? Say no more!
Check out how we animate full body avatars exclusively from audio input!
Paper: arxiv.org/abs/2401.01885
Project page: people.eecs.berkeley.edu/~evonne_ng/pro…
Dataset + Code: github.com/facebookresear…
English
3D body models now have sound!
We demonstrate 3D spatial audio synthesis for 3D full body models. (NeurIPS 2023 Spotlight)
Paper: openreview.net/pdf?id=zQTi3pz…
Dataset + Code (to be released): github.com/facebookresear…
English
Alexander Richard me-retweet
Work done in collaboration with @AlexRichardCS, @ovrdr, Vamsi Ithapu, @NataliaNeverova, Kristen Grauman, and Andrea Vedaldi @MetaAI @RealityLabs
The poster session is Tues-PM and I will also give a talk at the sight and sound workshop Monday 4:30pm.
English
Alexander Richard me-retweet

A new generalized and universal audio-visual speech enhancement model, powered by SSL.
A single model for denoising, source sep, inpainting and lip-reading!
Checkout the paper and demo video!!
🗣️🤖🔊
More details below
with @mhnt1580
Wei-Ning Hsu@mhnt1580
📢New paper We are announcing ReVISE, the first universal audio-visual speech enhancement model powered by SSL. paper: arxiv.org/pdf/2212.11377… demo: wnhsu.github.io/ReVISE w/ @adiyossLC @TalRemez @BowenSh08204149 @_JacobDonley
English
Alexander Richard me-retweet

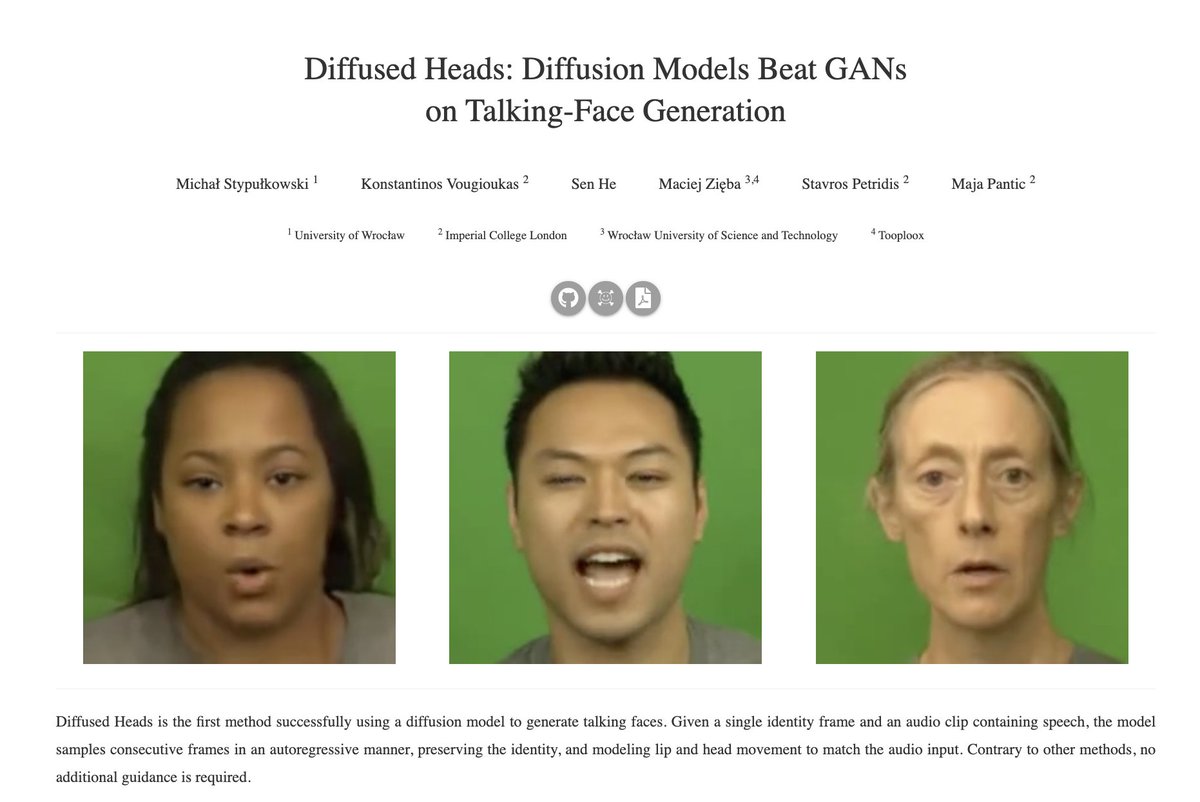
Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
abs: arxiv.org/abs/2301.03396
project page: mstypulkowski.github.io/diffusedheads/
English
Alexander Richard me-retweet

📢Excited to share our recent #ECCV2022 paper: "LiP-Flow: Learning Inference-Time Priors for Codec Avatars via Normalizing Flows in Latent Space" with Shugao Ma, @akcalakcal, Stanislav Pidhorskyi, @AlexRichardCS, Shih-En Wei, Jason Saragih and @OHilliges.
GIF
English
Happy to be on the list of outstanding reviewers for @eccvconf with my dear friends and coworkers @aayushbansal and @c_richardt
Congratulations!
European Conference on Computer Vision #ECCV2026@eccvconf
List of #ECCV2022 Outstanding Reviewers. Thank you all for your service! 👏 eccv2022.ecva.net/program/outsta…
English
**Dataset Release!**
We released high-quality 3D face data of 13 persons captured with up to 150 cameras while performing 100+ facial expressions!
github.com/facebookresear…
GIF
English