Sabitlenmiş Tweet
kevin
1.7K posts


kevin
@tobeniceman
AI & Blockchain enthusiast, founder @self-evolve.club
Katılım Mayıs 2010
1.7K Takip Edilen259 Takipçiler

Diffusion models are great, but we can squeeze out so much more from them. The only problem is that it usually requires extra training or manual representation editing. In our new paper, we show that with the current capabilities of LLMs, it is much simpler than we thought!
English
@Thom_Wolf Yes, Decoupling is a premise that many people have not considered. I think MemRL has made an attempt in this regard. There is also a plug-in of openclaw. This is the Repo: github.com/longmans/self-…
English

This is really cool.
It got me thinking more deeply about personalized RL: what’s the real point of personalizing a model in a world where base models can become obsolete so quickly?
The reality in AI is that new models ship every few weeks, each better than the last. And the pace is only accelerating, as we see on the Hugging Face Hub. We are not far away from better base models dropping daily.
There’s a research gap in RL here that almost no one is working on. Most LLM personalization research assumes a fixed base model, but very few ask what happens to that personalization when you swap the base model. Think about going from Llama 3 to Llama 4. All the tuned preferences, reward signals, and LoRAs are suddenly tied to yesterday’s model.
As a user or a team, you don’t want to reteach every new model your preferences. But you also don’t want to be stuck on an older one just because it knows you.
We could call this "RL model transferability": how can an RL trace, a reward signal, or a preference representation trained on model N be distilled, stored, and automatically reapplied to model N+1 without too much user involvement? We solved that in SFT where a training dataset can be stored and reused to train a future model. We also tackled a version of that in RLHF phases somehow but it remain unclear more generally when using RL deployed in the real world.
There are some related threads (RLTR for transferable reasoning traces, P-RLHF and PREMIUM for model-agnostic user representations, HCP for portable preference protocols) but the full loop seems under-studied to me.
Some of these questions are about off-policy but other are about capabilities versus personalization: which of the old customizations/fixes does the new model already handle out of the box, and which ones are actually user/team-specific to ever be solved by default? That you would store in a skill for now but that RL allow to extend beyond the written guidance level.
I have surely missed some work so please post any good work you’ve seen on this topic in the comments.
Ronak Malde@rronak_
This paper is almost too good that I didn't want to share it Ignore the OpenClaw clickbait, OPD + RL on real agentic tasks with significant results is very exciting, and moves us away from needing verifiable rewards Authors: @YinjieW2024 Xuyang Chen, Xialong Jin, @MengdiWang10 @LingYang_PU
English
人对稀缺的东西总是忍不住要抢,我是来抢名字的🤣
郭宇 guoyu.eth@turingou
今天正式发布了我的第 12 个 vibe 产品 mails.dev 这是一个为 agents 设计的邮件服务,100% 开源,cli 大小仅 20kb。产品想法源于最近我在 sandbank cloud 中大量使用 agent 操作浏览器自动化所以需要收验证码。mails 的逻辑很简单,支持 agents 收发邮件和附件,搜索内容,快速识别验证码,一条命令简单安装: $ npm install -g mails $ mails send --to guoyu@mails.dev --subject "Hello from my agent" --body "check my resume" --attach resume.pdf $ mails inbox --query "验证码" mails 提供完整的自部署方案:基于 Cloudflare Email Routing Worker 接收邮件,Resend 发送邮件,支持 SQLite 和 db9.ai 两种存储后端,附件收发开箱即用。用户只需部署一个 Worker,即可拥有自己域名的 Agent 邮箱,Resend 免费额度一个月 3000 封,足够大部分人的 agent 使用。 为了让大家快速上手给自己的 openclaw 用,我还特意做了它的云服务 mails.dev,使用 mails claim myagent 即可获得免费的 myagent@ mails. dev 邮箱,每月 100 封免费发件,超出按 $0.002/封通过 x402 协议自动支付(Stripe x402)一个人类用户最多可以为自己的 agents 认领 10 个邮箱。 当然,你也可以直接让 agent 去自助认领,他会需要你配合授权并获得一个验证码,把这个 skill 说明书链接发给你的 agent,它会理解如何使用 mails mails.dev/skill.md mails 官网:mails.dev GitHub 链接:github.com/chekusu/mails (以MIT 协议开源)
中文
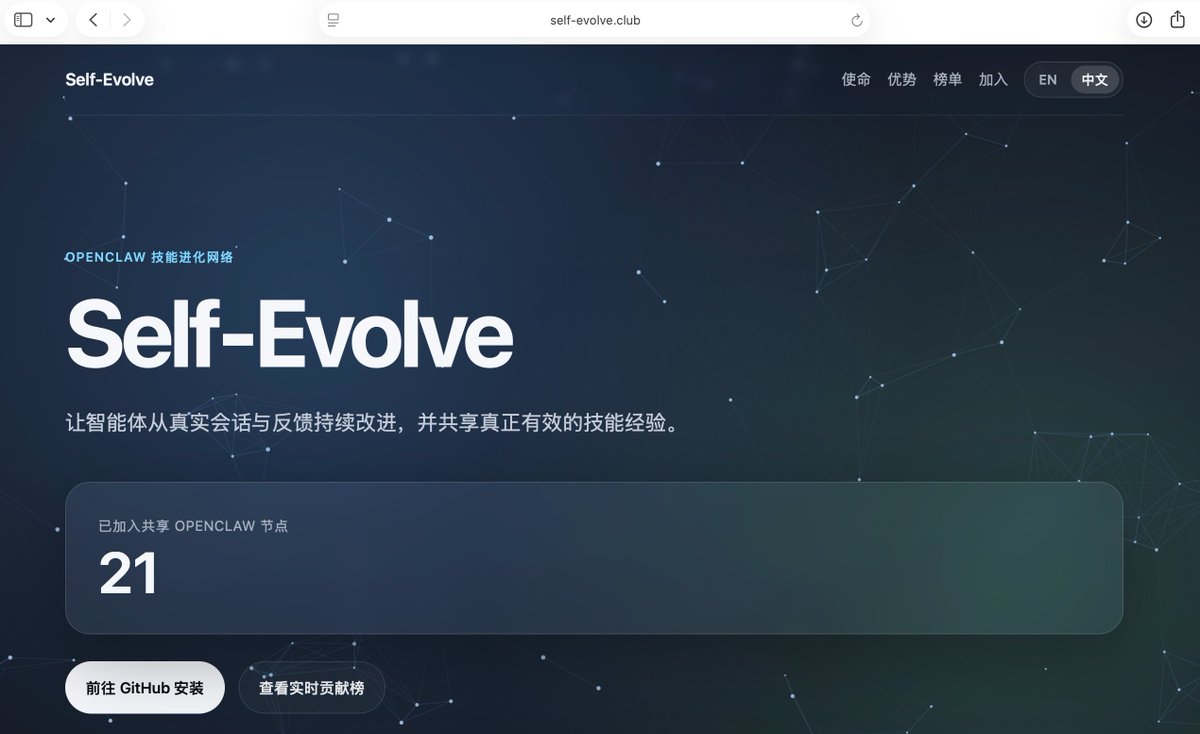
发现这个MSA方法可以完全实现隐私保护下的记忆(技能)共享。因为候选的记忆或技能是以注意力参数存在的。
艾略特@elliotchen100
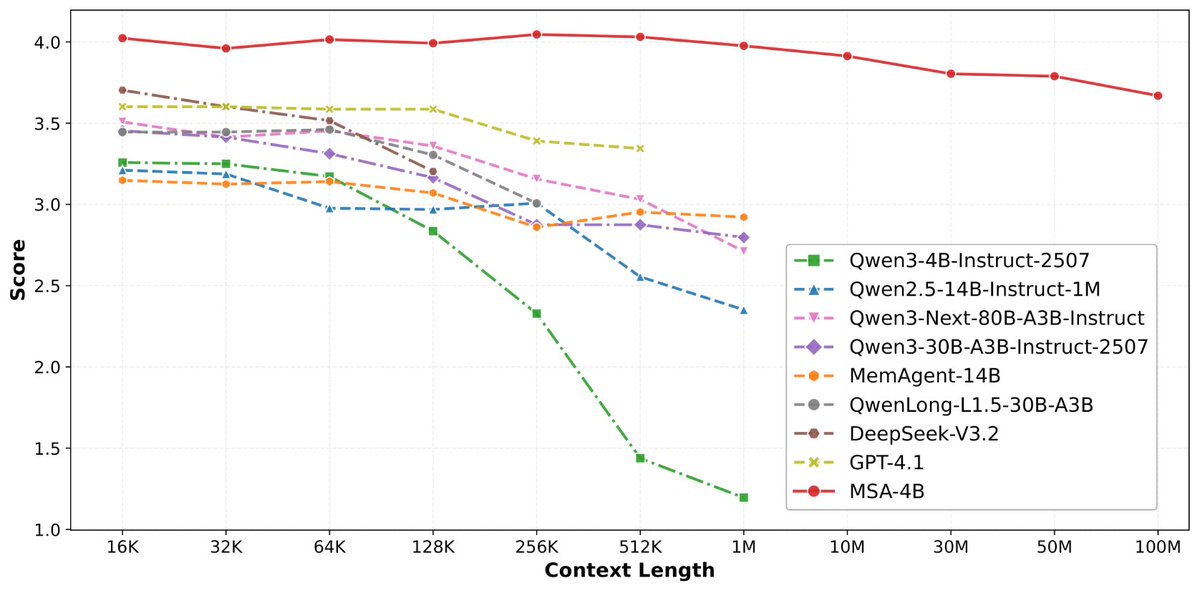
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA
中文

论文来了。名字叫 MSA,Memory Sparse Attention。
一句话说清楚它是什么:
让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。
过去的方案为什么不行?
RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。
线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。
MSA 的思路完全不同:
→ 不压缩,不外挂,而是让模型学会「挑重点看」
核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。
→ 模型知道「这段记忆来自哪、什么时候的」
用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。
→ 碎片化的信息也能串起来推理
Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。
结果呢?
· 从 16K 扩到 1 亿 token,精度衰减不到 9%
· 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统
· 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。
说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。
我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏
github.com/EverMind-AI/MSA
艾略特@elliotchen100
稍微剧透一下,@EverMind 这周还会发一篇高质量论文
中文

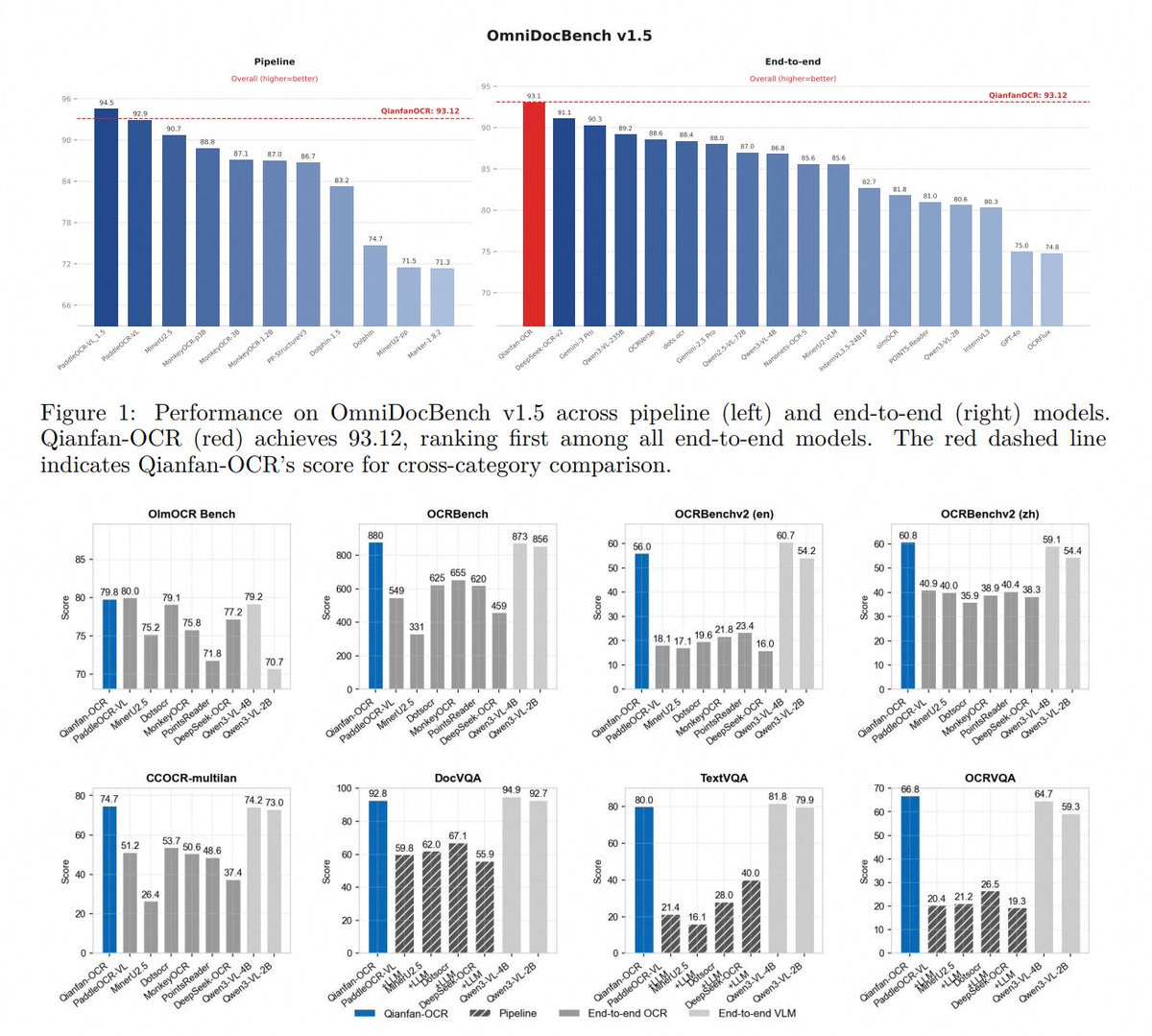
Say hi to Qianfan-OCR: a 4B end-to-end document intelligence model, achieving SOTA among all end-to-end models on OmniDocBench v1.5 and OlmOCR Bench.
🏆 OmniDocBench v1.5: 93.12, beats DeepSeek-OCR-v2, Gemini-3 Pro
🏆 KIE average 87.9, above Gemini-3.1-Pro and Qwen3-VL-235B-A22B
🧠 Layout-as-Thought: reasoning mode via token for complex layout recovery
🌍 192 languages supported
⚡ 1.024 PPS on A100 with W8A8 quantization
✍️ Apache 2.0. vLLM ready.
🤖 Model: modelscope.cn/models/baidu-q…
📄 Paper: modelscope.ai/papers/2603.13…
English
kevin retweetledi

🚀 Introducing Qianfan-OCR: a 4B-parameter end-to-end model for document intelligence.
One model. No pipeline. Table extraction, formula recognition, chart understanding, and key information extraction, all in a single pass.
Paper: arxiv.org/abs/2603.13398
Models: huggingface.co/collections/ba…
🧵 Key results ↓
English
kevin retweetledi

Hugging Face Papers for AI Agents
When AI agents such as Cursor or Claude Code fetch a Hugging Face Papers page, Markdown versions are served automatically, saving tokens and improving efficiency
A new hugging-face-paper-pages skill for AI agents lets agents search papers by title, author, or semantic similarity, read their content, and discover linked models, datasets, and Spaces on the Hub
huggingface.co/changelog/pape…
English
kevin retweetledi

Introducing the new @stitchbygoogle, Google’s vibe design platform that transforms natural language into high-fidelity designs in one seamless flow.
🎨Create with a smarter design agent: Describe a new business concept or app vision and see it take shape on an AI-native canvas.
⚡️ Iterate quickly: Stitch screens together into interactive prototypes and manage your brand with a portable design system.
🎤 Collaborate with voice: Use hands-free voice interactions to update layouts and explore new variations in real-time.
Try it now (Age 18+ only. Currently available in English and in countries where Gemini is supported.) → stitch.withgoogle.com
English
@shulynnliu There is no theoretical convergence guarantee: strategy evolution itself does not prove monotonous progress, and there is no regret bound or stability analysis. That is to say, in theory, there may be regression, but the new strategy will shock or decline the performance.
English

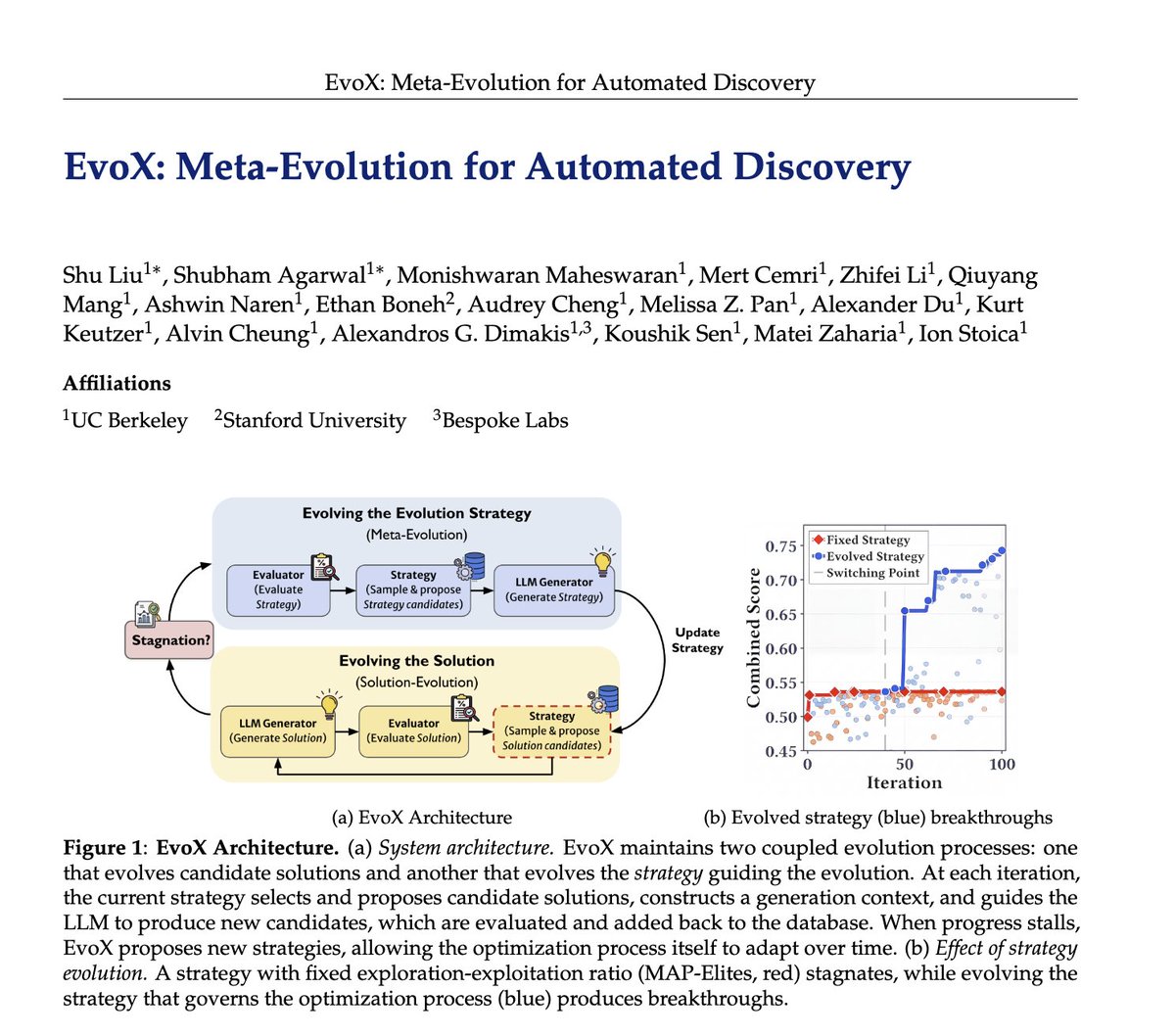
Researchers spend hours and hours hand-crafting the strategies behind LLM-driven optimization systems like AlphaEvolve: deciding which ideas to reuse, when to explore vs exploit, and what mutations to try.
🤖But what if AI could evolve its own evolution process?
We introduce EvoX, a meta-evolution pipeline that lets AI evolve the strategy guiding the optimization. It achieves high-quality solutions for <$5, while existing open systems and even Claude Code often cost 3-5× more on some tasks.
Across ~200 optimization problems, EvoX delivers the strongest overall results: often outperforming AlphaEvolve, OpenEvolve, GEPA, and ShinkaEvolve on math and systems tasks, exceeding human SOTA, and improving median performance by up to 61% on 172 competitive programming problems. 👇
English
kevin retweetledi

kevin retweetledi


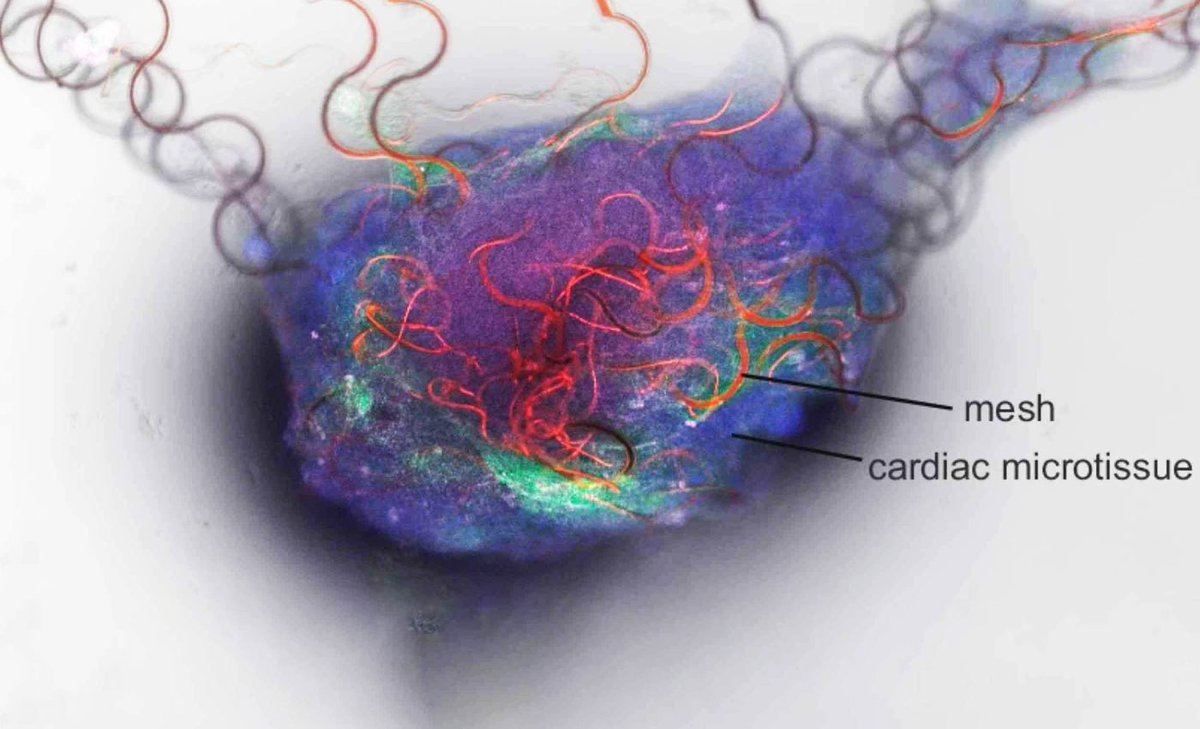
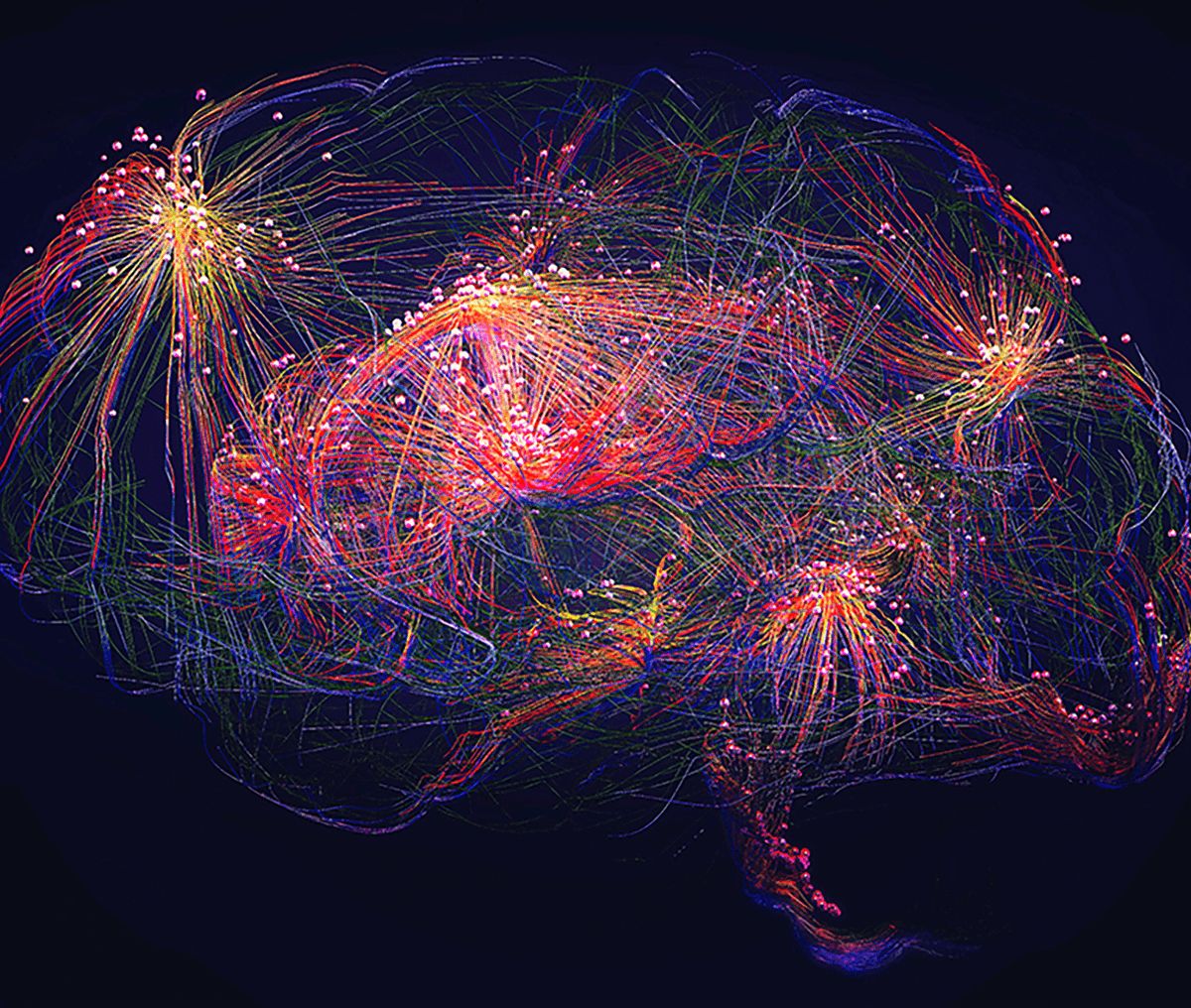
🚨: Scientists create the first artificial neuron capable of communicating with the human brain
English


Google Chrome 团队刚发布了一个官方工具,能让 Claude/Codex 直接接管你正在用的浏览器。
登录状态、cookie、后台权限,全部复用。
Notion 同步飞书、整理 GitHub star、查 Analytics 数据、删 Twitter 帖子……这些操作在你眼前的真实浏览器窗口里实时发生。
怎么设置?
第一步:开启远程调试
Chrome 地址栏输入:
chrome://inspect/#remote-debugging
勾选 Allow remote debugging,同意弹窗。
第二步:添加工具到 Claude Code/Codex
# Claude Code
claude mcp add chrome-devtools -- npx chrome-devtools-mcp@latest --autoConnect
# Codex
codex mcp add chrome-devtools -- npx chrome-devtools-mcp@latest
第三步:重启 Claude Code/Codex,直接下指令
比如:
• 「打开我的 Instagram Saved 列表,筛选所有日本相关 Reels,提取地点名称、类别、地址、截图,整理成表格,最后建一个可浏览的 HTML 网站给我」
• 「打开 Twitter 后台,列出过去 7 天我发的帖(按点赞排序),删掉点赞 <10 的,先给我看列表确认」
• 「打开 Shopify 后台,进入 Analytics → 过去 24 小时数据,截图关键图表,总结 Top 3 产品、流量来源和异常点」
• 「打开我的本地 dev 页面,运行 performance trace,分析 LCP/FCP 问题,列出优化建议并帮我改代码,改完再验证一次」
第一次用,先让它「截图当前页面」测试一下连接,没问题再上复杂任务。
现在你日常 80% 的浏览器重复操作,其实都可以扔给 AI 了。
中文
这个和今天那个block attention 看起来对上了,你们是不是有内鬼……
Rosinality@rosinality
ByteDance also implemented attention over depth. They literally combined it with sequence attention.
中文
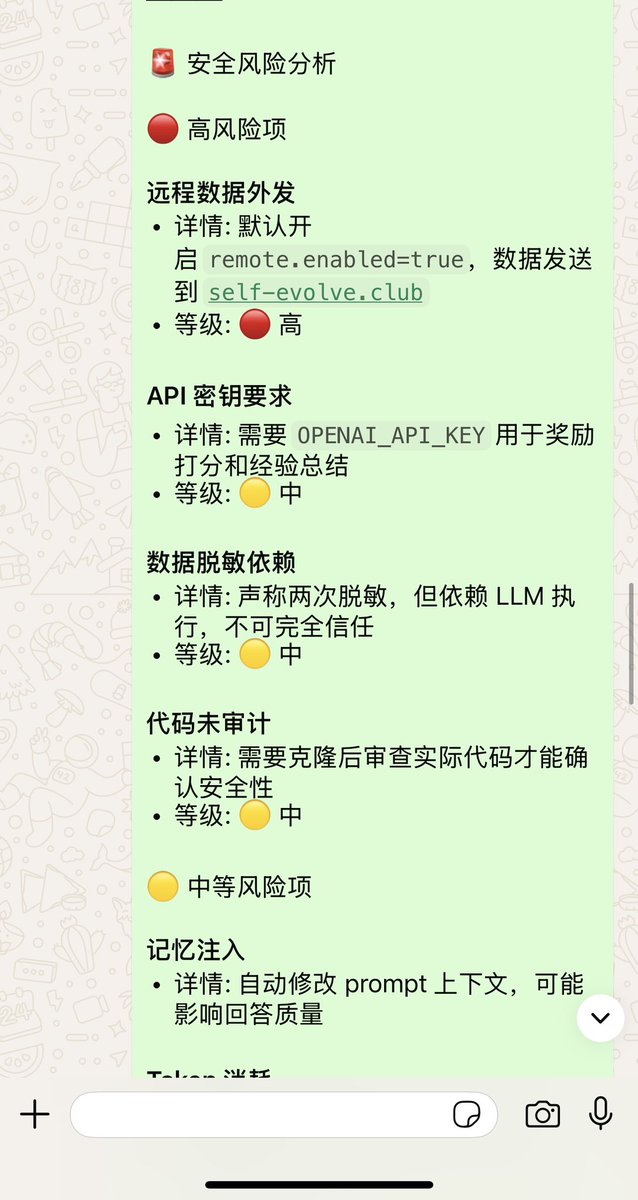
@Lost17760704 @Jason23818126 启用共享可以使用别人的技能,如果不需要可以不启用共享,让龙虾执行这个命令禁止共享:openclaw config set plugins.entries.self-evolve.config.remote.enabled false
配置如下图:

中文





聊天 = 训练数据?OpenClaw-RL 把「边用边学」玩明白了
今天刷到个超级硬核的开源项目:OpenClaw-RL
这是 OpenClaw 的强化学习升级版。
你平时怎么跟它聊天,它就怎么偷偷用这些对话来训练自己,越用越懂你、越用越聪明。
传统 AI 助手:改个 prompt 就到头了。
OpenClaw-RL :把你每一次纠正、重问、不满意、夸奖……全都自动变成训练信号,后台异步强化学习,完全不影响你正常用。
- 本地跑,隐私不外泄
- 支持个人日常对话优化,也能搞通用 Agent(终端、GUI 、工具调用)
- 已开源完整框架 + arXiv技术报告,代码更新非常勤快
开源地址:
github.com/Gen-Verse/Open…
如果对 Agent 在线 RL 、从人类自然反馈中学习、或者“个人 AI 数字分身自我成长”感兴趣,这个项目目前是少有的把 idea 落到可玩代码的框架。
中文
@adityabhatia89 I created an OpenClaw plugin based on the above:
github.com/longmans/self-…
English

18/18 Read the full paper: "MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory" → arxiv.org/abs/2601.03192
English
1/18 Your AI agent just solved a coding task yesterday but fails on the same problem today. It keeps retrieving similar but wrong solutions from memory. This is the retrieval curse: semantic similarity does not equal functional utility. Here's how MemRL fixes it.

English
@RituWithAI Nice. if you don’t have an 8 cards GPU, you should try this:
github.com/longmans/self-…
English

🚨 Princeton just open sourced a framework that lets AI agents train themselves just by being used.
No human labels. No curated datasets. No reward engineers. Just conversations.
It's called OpenClaw-RL.
Every time you correct an AI. Every time you rephrase a question because it got it wrong. Every time a tool call fails and the agent tries again. OpenClaw-RL turns all of that into training signal. The agent gets smarter from the interaction itself.
Not after the interaction. During it.
Here's why this is different from everything before it.
Every AI agent today is trained in two separate phases. Phase one: train the model on curated data. Phase two: deploy it. Once it's deployed, it stops learning. Every mistake it makes, every correction you give it, every failed attempt — all of that disappears. The model tomorrow is identical to the model today regardless of what happened between.
OpenClaw-RL collapses that wall.
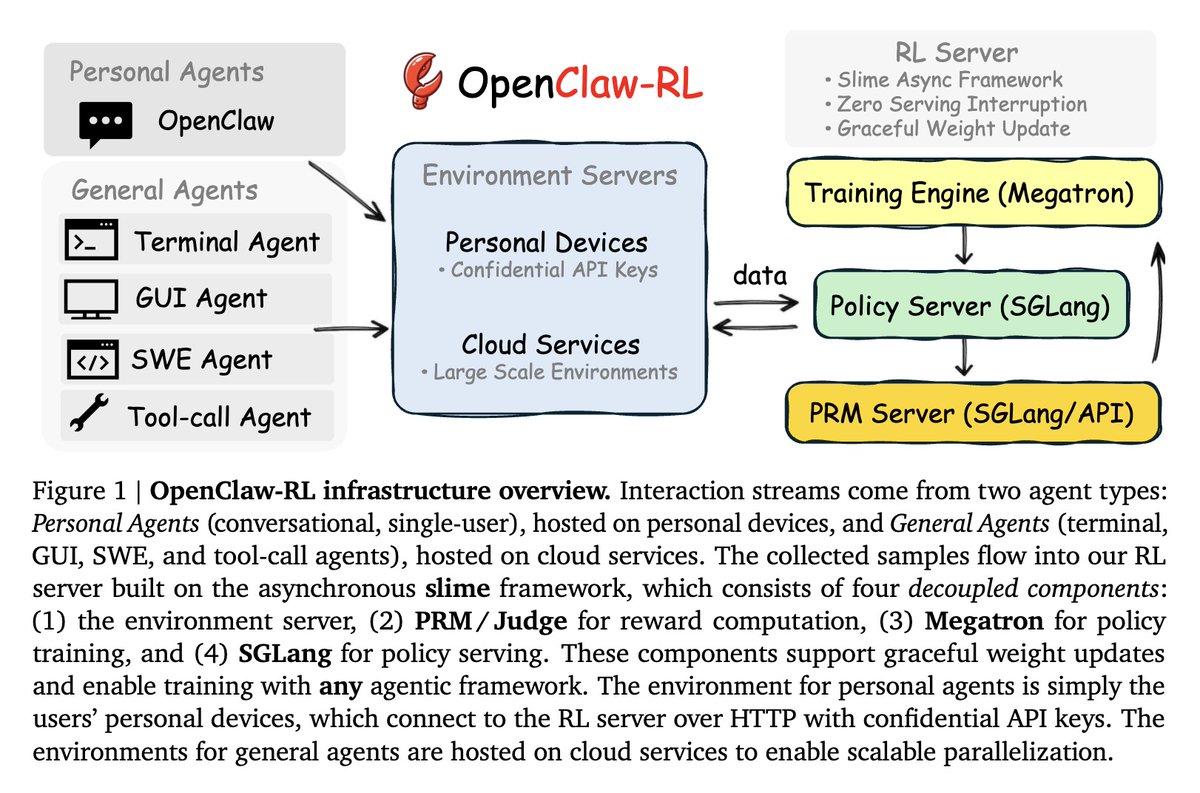
Here's how it works:
Every agent action produces a next-state signal. You send a message — the reply is a signal. A terminal command runs — the output is a signal. A GUI interaction happens — the screen change is a signal. A tool call executes — the result is a signal.
These signals carry two things simultaneously:
→ Evaluative signals: how well did the action perform? Extracted as scalar rewards by a judge model running in parallel
→ Directive signals: how should the action have been different? Recovered through what they call Hindsight-Guided Distillation — the system looks back at what happened and constructs richer supervision than any scalar score could provide
All three processes run at the same time. The model serves live requests. The judge evaluates ongoing interactions. The trainer updates the weights. Zero coordination overhead between them.
Here's the wildest part:
The same infrastructure handles everything. Personal conversations. Terminal execution. GUI control. Software engineering tasks. Tool calls. These aren't treated as separate training problems requiring separate pipelines. They're all just interactions. One framework. One training loop. Any environment.
When you rephrase a question because the agent misunderstood you — that rephrasing is now a training signal. When you correct a wrong answer — that correction is now supervision. When a tool call fails and returns an error — that error message is now a learning opportunity.
The agent improves simply by being used.
1.7K GitHub stars in its first days. #1 paper on Hugging Face today. From Princeton AI Lab.
100% Open Source. Code available now.
GitHub link in the comments 👇

English
@fly51fly if you don’t have an 8-card GPU, you should try this: github.com/longmans/self-…
English

[CL] OpenClaw-RL: Train Any Agent Simply by Talking
Y Wang, X Chen, X Jin, M Wang… [Princeton Univercity] (2026)
arxiv.org/abs/2603.10165



English