Tweet Disematkan

🚀 We’re excited to announce that our paper, “STAN-LOC: Visual Query-based Video Clip Localization for Fetal Ultrasound Sweep Videos,” has been accepted to #MICCAI2024! 🎉
English
Divyanshu Mishra
518 posts
@Perceptron97
Research @AmazonScience. DPhil from @UniOfOxford @NobleLabOxford. Interested in video understanding, world foundation models.





Hello World: I am reviewing Phd applications and the level of talent is amazing. Sadly, the funding situation is extremely challenging. SO: If you'd like to gift someone brilliant literally the opportunity of their lifetime and sponsor their Phd in my group please let me know 🙏






🎉 We're excited to announce the 2025 Google PhD Fellows! @GoogleOrg is providing over $10 million to support 255 PhD students across 35 countries, fostering the next generation of research talent to strengthen the global scientific landscape. Read more: goo.gle/43wJWw8

💡 Should you do a PhD in AI (2025–26)? 🎓 🔗: yashbhalgat.github.io/blog/phd-or-no… Every October, students considering PhD applications ask me: is a PhD still the right path in AI? ⚖️ ⚠️ After a few years moving between academia (@UniofOxford's @Oxford_VGG) and industry (@QCOMResearch, @Meta Reality Labs, and a few startups), I’ve seen both sides of the research world. And the truth is: they’ve never felt further apart. 🌟 Today, most of the *scale-driven* work -- world models, video generation, large VLMs -- happens in industry. Compute access, data scale, and iteration speed make that inevitable. But academia still matters: it’s where new ideas, theory, and deep conceptual work often begin. The difference now is knowing what not to work on. 📢 I’ve written a longer, no-BS post on this -- what makes a PhD worth it, when it doesn’t, and how to think about your timing. 🧭 Read it, share it, debate it -- just don’t decide by inertia. Full post here: yashbhalgat.github.io/blog/phd-or-no… #PhD #AI #ArtificialIntelligence #MachineLearning #PhDLife #Research #AcademicTwitter #GradSchool #CareerAdvice


how a mathematician sees the world
At ICCV 2025, I am organizing two workshops: the LIMIT Workshop and the FOUND Workshop. ◆ LIMIT Workshop (19 Oct, PM): iccv2025-limit-workshop.limitlab.xyz ◆ FOUND Workshop (19 Oct, AM): iccv2025-found-workshop.limitlab.xyz We warmly invite you to attend at these workshops in ICCV 2025 Hawaii!






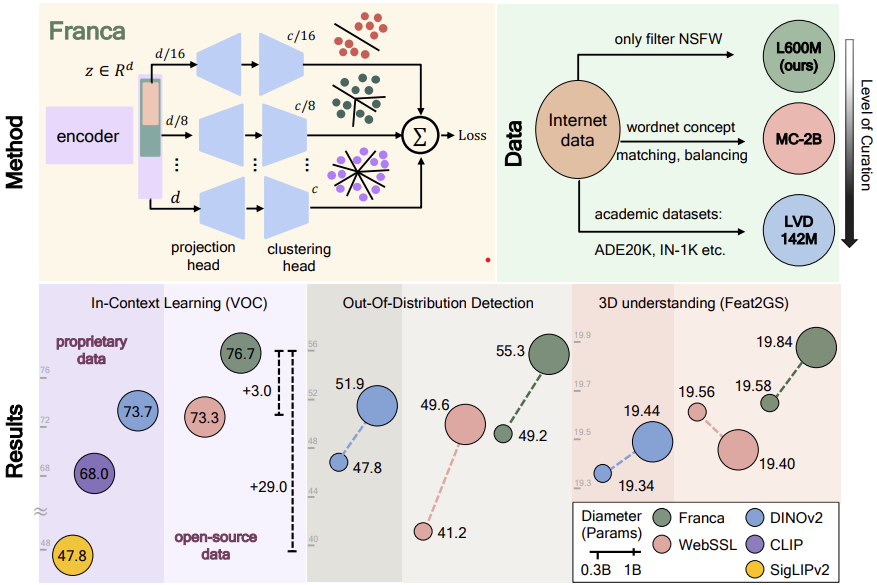


Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research🧵
New paper out - accepted at @ICCVConference We introduce MoSiC, a self-supervised learning framework that learns temporally consistent representations from video using motion cues. Key idea: leverage long-range point tracks to enforce dense feature coherence across time.🧵