
Mike Lewis
277 posts
Mike Lewis
@ml_perception
Llama3 pre-training lead. Partially to blame for things like the Cicero Diplomacy bot, BART, RoBERTa, attention sinks, kNN-LM, top-k sampling & Deal Or No Deal.
Seattle Katılım Eylül 2019
250 Takip Edilen8.4K Takipçiler

This is a long post, mainly because I have a lot to say, but in case you are too busy:
TLDR: @Vercept_ai is joining @AnthropicAI! We shared a mission, so we joined forces to accelerate it into reality. Couldn't be more excited!
Why Vercept was started
In 2024, AI coding tools were already becoming magical for developers, but other industries were ages behind. It felt insane that when my mom had IT issues, I still had to hop on a call and walk her through it step by step. Insane that sending a simple email took so many clicks.
That's why we started @Vercept_ai : Build something that acts for users instead of telling them how to do it. Two goals: 1) help people do tasks they didn't know how to do, and 2) handle the zero-brainpower tasks so people spend more time on creative work. As simple as scheduling meetings, as complex as reconciling messy financials before tax season. Ultimate goal was to have people spend less time behind screens and more time walking in nature. (Very Pacific Northwest mission 😁)
The ride
The journey of building an AI native company in this day and age was wild. Going from researcher to founder meant trading “reviewer number 2” for business partners and users, but surprisingly a lot of the same paradigms applied. Come up with a hypothesis, design an experiment, analyze user behavior, change the model and product based on the findings, wash, rinse and repeat.
There are some differences though. The pace and the adrenaline. Lows are low, highs are high. We were constantly being challenged and learned at a pace we had never learned before. NEVER! If you are an adrenaline junkie like we are, it's a blast. The joy of the startup adrenaline rush is truly underrated.
Why Anthropic
We raised more than $50M, had a comfortable runway and a successful product, were building full steam with a small team, and were truly enjoying every minute of it. But that's when the opportunity came to join forces with Anthropic. We already knew how great Anthropic was at building models and we admired their mission, but then we learned more about the vision.
We went on hours of walks, had long conversations, talked to members across different orgs, and learned more about Anthropic's vision and commitment to core beliefs which were very similar to ours. The more we talked, the more we realized we had been working on the same mission but from complementary perspectives. We realized that joining forces meant we could build something much much bigger together.
And beyond the mission, I am now a big believer that Anthropic's real moat isn't its best model. It's the people. Incredibly talented folks who genuinely care about mission and real impact over hype. A zero-ego culture obsessed with building something meaningful. The choices were clear: we could build independently and work toward the same vision as two separate versions of it, or join forces with an incredible team and accelerate that vision into reality. The decision became an easy choice.
What's next for our mission
Mission continues, just got a bigger stage and an expanded team. The goal is still to expand AI beyond just a chatbot, to enable non-technical users to leverage it just as much as technical ones. We're just getting started.
It takes a village
This journey wouldn't have happened without the people who made it what it was. First and foremost, my cofounders @LucaWeihs and @inkynumbers . Best people I could've wished for as cofounders. We never once got into an argument, always had communicative discussions and as a cherry on top shared the same sense of humor! I feel blessed and grateful to have these two in my life.
Thankful to our team for trusting in the three of us and showing up day and night.
Grateful for @sethbannon , our board member, lead investor, great mentor and the person whose energy is so infectious that whenever we were having a down moment we would say "channel your inner @fiftyyears energy!"
And to our wonderful investors and supporters: @chrija and @PointNineCap , Yifan and Jacob and @ai2incubator , and @mattmcilwain and Ted Kummert from @MadronaVentures . Couldn't have done this without you.
Onward 🐜

English
Excited to see what the amazing @sarahookr and team build here!
Sara Hooker@sarahookr
Beginnings are very special. Today is an important day for @adaptionlabs. Today a handful of one-size-fits-all-models are optimized for the average use case. Averages erase the exceptional. Everything intelligent adapts. So should AI.
English
Mike Lewis retweetledi

Our team in FAIR at Meta is hiring a (full-time) researcher!
We work on the topics of Reasoning, Alignment and Memory/architectures (RAM) for self-improvement & co-improvement.
Apply here:
metacareers.com/profile/job_de…
Location: NY, Seattle or Menlo Park.
Some of our recent work to give flavor:
Co-Improvement (position): arxiv.org/abs/2512.05356
SPICE (Self-Play in Corpus Environments): arxiv.org/abs/2510.24684
Self-Challenging Agents: arxiv.org/abs/2506.01716
RL from Human Interaction: arxiv.org/abs/2509.25137
AggLM (parallel aggregation): arxiv.org/abs/2509.06870
StepWiser (CoT-PRM RL): arxiv.org/abs/2508.19229
DARLING (diversity-trained RL): arxiv.org/abs/2509.02534
J1 (RL-trained LLM-as-Judge): arxiv.org/abs/2505.10320
CoT-Self-Instruct: arxiv.org/abs/2507.23751
Multi-Token Attention: arxiv.org/abs/2504.00927
English
@edward_milsom You see this because at the start of each epoch, many of your samples were seen recently at the end of the previous epoch. By the end of your epoch, each sample hasn't been seen for at least one epoch, so is less memorized.
English

Train an NN on a "multiple epoch" task like CIFAR-10. Even shuffling, I get this "Epoch sawtooth effect" (arxiv.org/abs/2410.10056…). Paper says it's because of Adam / RMSprop, but I've also observed it with SGD momentum on Imagenet32. Real phenomenon? Or bug causing correlations?

English
Mike Lewis retweetledi

🚀 Introducing the Latent Speech-Text Transformer (LST) — a speech-text model that organizes speech tokens into latent patches for better text→speech transfer, enabling steeper scaling laws and more efficient multimodal training ⚡️
Paper 📄 arxiv.org/pdf/2510.06195

English
Love seeing these incredibly creative new evaluations! Optimizing benchmarks is easy, the real challenge is in generalizing to the tasks that don't exist yet
henry@arithmoquine
new post. there's a lot in it. i suggest you check it out
English
Mike Lewis retweetledi

I've written the full story of Attention Sinks — a technical deep-dive into how the mechanism was developed and how our research ended up being used in OpenAI's new OSS models.
For those interested in the details:
hanlab.mit.edu/blog/streaming…

English
English

📣Thrilled to announce I’ll join Carnegie Mellon University (@CMU_EPP & @LTIatCMU) as an Assistant Professor starting Fall 2026!
Until then, I’ll be a Research Scientist at @AIatMeta FAIR in SF, working with @kamalikac’s amazing team on privacy, security, and reasoning in LLMs!



English
Mike Lewis retweetledi

Don’t miss this - I’ve worked with Mike (@ml_perception) very closely at Meta and his talks are super informative and fun.
Alan Ritter@alan_ritter
Want to learn about Llama's pre-training? Mike Lewis will be giving a Keynote at NAACL 2025 in Albuquerque, NM on May 1. 2025.naacl.org @naaclmeeting
English
Mike Lewis retweetledi

📉📉NEW SCALING LAW PHENOMENON 📉📉
We find that knowledge and reasoning exhibit different scaling behaviors!
Super excited to finally tell you all about our paper on the compute optimal scaling of skills:
arxiv.org/pdf/2503.10061
[1/n]

English

Thrilled to have joined an incredible team at Reflection @reflection_ai to push the frontier of autonomous coding!
Misha Laskin@MishaLaskin
Today I’m launching @reflection_ai with my friend and co-founder @real_ioannis. Our team pioneered major advances in RL and LLMs, including AlphaGo and Gemini. At Reflection, we're building superintelligent autonomous systems. Starting with autonomous coding.
English
Mike Lewis retweetledi

✨New Preprint✨We introduce 𝐁𝐫𝐚𝐧𝐜𝐡-𝐓𝐫𝐚𝐢𝐧-𝐒𝐭𝐢𝐭𝐜𝐡 (𝐁𝐓𝐒), an efficient & flexible method for stitching together independently pretrained LLM experts (i.e. code, math) into a single, capable generalist model.
Key Takeaways:
✅BTS achieves the best average generalist performance across a variety of tasks 👊
✅We stitch together 4 x 2.7B specialized expert LLMs, where only the lightweight stitching layers (<300M params in total‼) are trained while the experts’ params remain frozen. This makes BTS super modular, flexible, and easy to train! 👊
arxiv.org/abs/2502.00075
Work done at @AIatMeta w/ @prajjwal_1, Chloe Bi, Chris Cai, @j_foerst @imjeremyhi @punitkoura, Ruan Silva, @shengs1123 @em_dinan* @ssgrn* @ml_perception*
* Joint last author
🧵👇(1/5)
GIF
English
Mike Lewis retweetledi

🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Patch…
Code 🛠️ github.com/facebookresear…

English
Mike Lewis retweetledi

How can we reduce pretraining costs for multi-modal models without sacrificing quality? We study this Q in our new work: arxiv.org/abs/2411.04996
At @AIatMeta, We introduce Mixture-of-Transformers (MoT), a sparse architecture with modality-aware sparsity for every non-embedding transformer parameter (e.g., feed-forward networks, attention matrices, and layer normalization). MoT achieves dense-level performance with up to 66% fewer FLOPs!
✅ Chameleon setting (text + image generation): Our 7B MoT matches dense baseline quality using just 55.8% of the FLOPs.
✅ Extended to speech as a third modality, MoT achieves dense-level speech quality with only 37.2% of the FLOPs.
✅ Transfusion setting (text autoregressive + image diffusion): MoT matches dense model quality using one-third of the FLOPs.
✅ System profiling shows MoT achieves dense-level image quality in 47% and text quality in 75.6% of the wall-clock time**
Takeaway: Modality-aware sparsity in MoT offers a scalable path to efficient, multi-modal AI with reduced pretraining costs.
Work of a great team with @liliyu_lili, Liang Luo, @sriniiyer88, Ning Dong, @violet_zct, @gargighosh, @ml_perception, @scottyih, @LukeZettlemoyer, @VictoriaLinML.👏
**Measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs.



English

Proud and excited to share that today I've been appointed as a full professor! 🎉 This is far from a solo achievement. I owe a huge thank you to many people and especially to @AnetteMFrank and #ManfredPinkal, who provided constant support and encouragement along this long way. 🙏
English
@apjacob03 @MIT_CSAIL @jacobandreas @KonstDaskalakis @gabrfarina @roger_p_levy @polynoamial @adamlerer @em_dinan Huge congrats Jacob!!
English

Super excited to share that I've defended my PhD @MIT_CSAIL! 🎓
I want to extend my immense gratitude to my advisor, @jacobandreas, and my thesis committee — @KonstDaskalakis, @gabrfarina, and @roger_p_levy. Huge thanks to @polynoamial, @adamlerer, @em_dinan, @ml_perception, and many other labmates / mentors / collaborators during my time at @AIatMeta, @MIT, @Google, and @MITIBMLab for playing such a critical role in my PhD journey. 🙏
And of course, I couldn’t have done this without the unwavering support of my friends, family, and God.
Excited for the opportunities at the intersection of foundation models, decision-making and its intersection with strategic domains.
There's more to come — stay tuned! 🚀



English

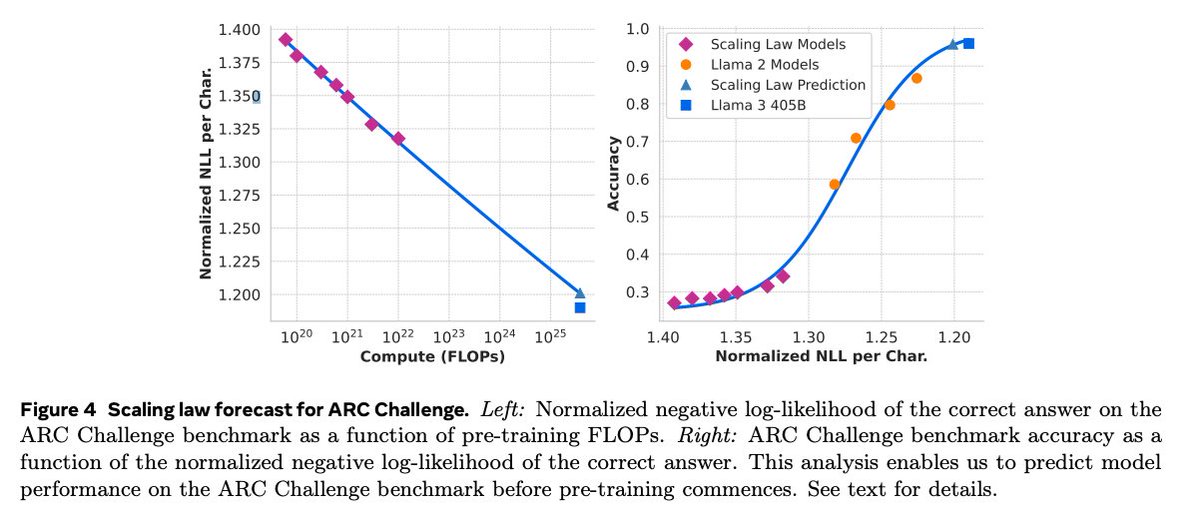
🙏I would greatly appreciate if someone from the Llama3 team / anyone who knows the details could provide a detailed explanation (or DM me!) about the concrete calculation of the "normalized negative log-likelihood of the correct answer" metric used for the ARC Challenge benchmark (as shown in the figure from Llama3.1 paper)
My specific questions are:
1) What is the meaning of "Normalized NLL per Char" in the figure captions? How is this metric calculated and normalized?
2) Does the input to the model contain the question along with the answer candidates/options?
3) What is the exact format used for the calculation? Is it something like: Question; Answer Options; Correct Answer (specified as an option or verbatim content)?
@ml_perception @edunov @astonzhangAZ (Sorry to bother you 🙏)
English
Mike Lewis retweetledi

1/n Introducing MoMa 🖼, our new sparse early-fusion architecture for mixed-modal language modeling that significantly boosts pre-training efficiency 🚀 (arxiv.org/pdf/2407.21770).
MoMa employs a mixture-of-expert (MoE) framework with modality-specific expert groups. Given any interleaved mixed-modal token sequences, each group exclusively processes tokens of the designated modality with conventional MoE routing.
This is joint work with amazing co-first authors @AkshatS07, @ArmenAgha and collaborators @AIatMeta – Liang Luo, @sriniiyer88, @ml_perception, @gargighosh and @LukeZettlemoyer.

English
@tallinzen The base model recipe is relatively straightforward (though of course >15T tokens), so you could always use that! Post training makes a huge difference on some tasks, but not all, which is interesting in itself.
English

This stuff raises a question that we've grappled with before: when doing LLM research, should we really treat systems like this (15T training tokens, many post-training tricks) as a baseline? Or is there value in research on simpler systems even if they perform a little worse?
Tal Linzen@tallinzen
One reason I'm excited about the Llama 3 paper is we finally have a description of what you need to do to get an LLM to reason sort-of well (human supervision, symbolic methods in post-training). GPT-4 and co. do not show that reasoning "emerges from distributional learning".
English
@NamanGoyal21 Can I have a nickel for every extra FLOP your work let us use?
English

@ml_perception if only I had a nickle for every time Mike stopped us from "3) screwing up"
English
tldr; you can go a long way in pre-training by (1) curating amazing data, (2) using a lot of FLOPs, and (3) otherwise not screwing up. All three are harder than they sound, so read the paper... That said, I'm amazed by our progress since Llama 3 - expect big things from Llama 4!
Mike Lewis@ml_perception
So excited for the open release of Llama 3.1 405B - with MMLU > 87, it's a really strong model and I can't wait to see what you all build with it! llama.meta.com Also check out the paper here, with lots of details on how this was made: tinyurl.com/2z2cpj8m
English