Tuhin Srivastava@tuhinone
Today, we’re excited to announce our $150M Series D, led by BOND, with Jay Simons joining our Board. We’re also thrilled to welcome Conviction and CapitalG to the round, alongside support from 01 Advisors, IVP, Spark Capital, Greylock Partners, Scribble Ventures, and Premji Invest.
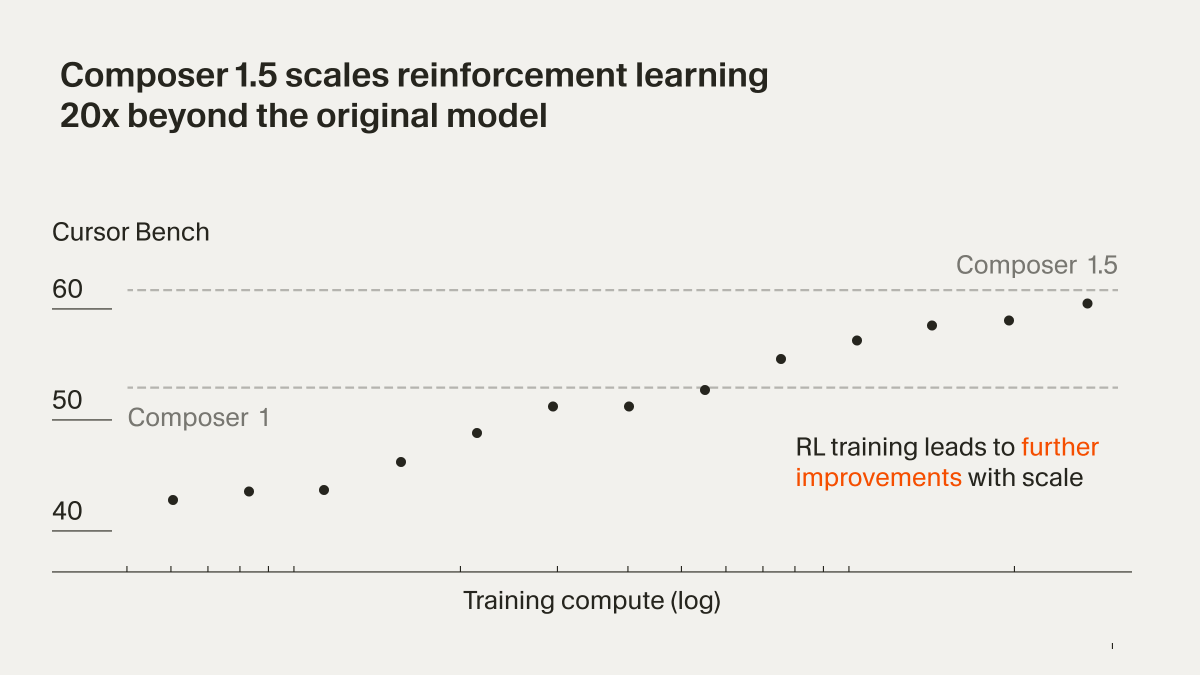
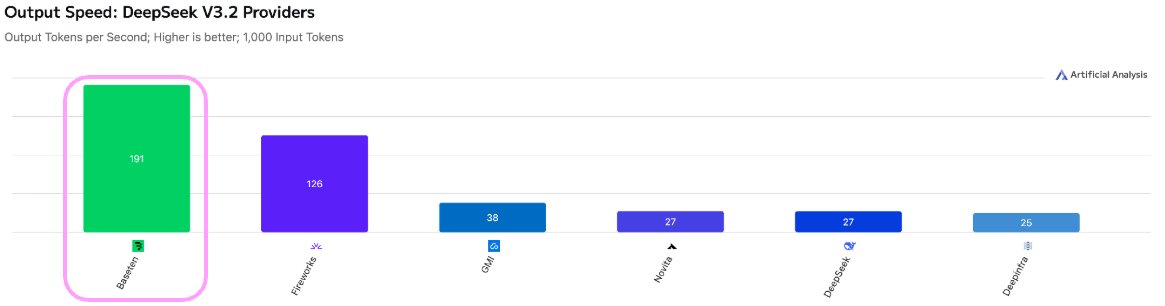
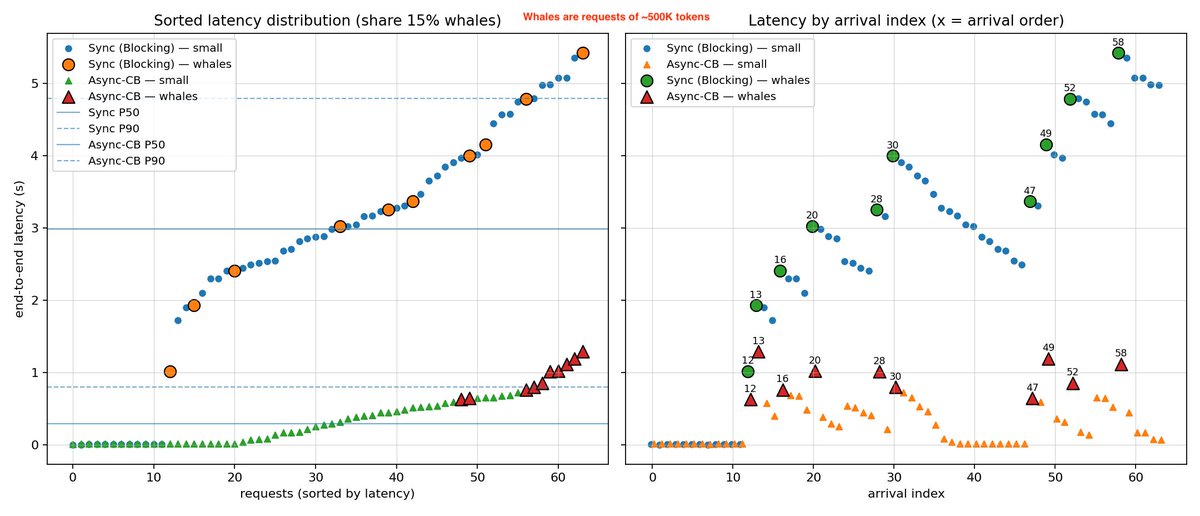
The last eighteen months have been a whirlwind; as the AI application layer has taken off, we've been proud to play a small part supporting world class companies run their production workloads. Thanks to all our customers including Abridge, Bland, Clay, Gamma, Mirage, OpenEvidence, Sourcegraph, WRITER, and Zed Industries.
We’re just getting started. If you’re building the next generation of AI products, we’d love to work with you.