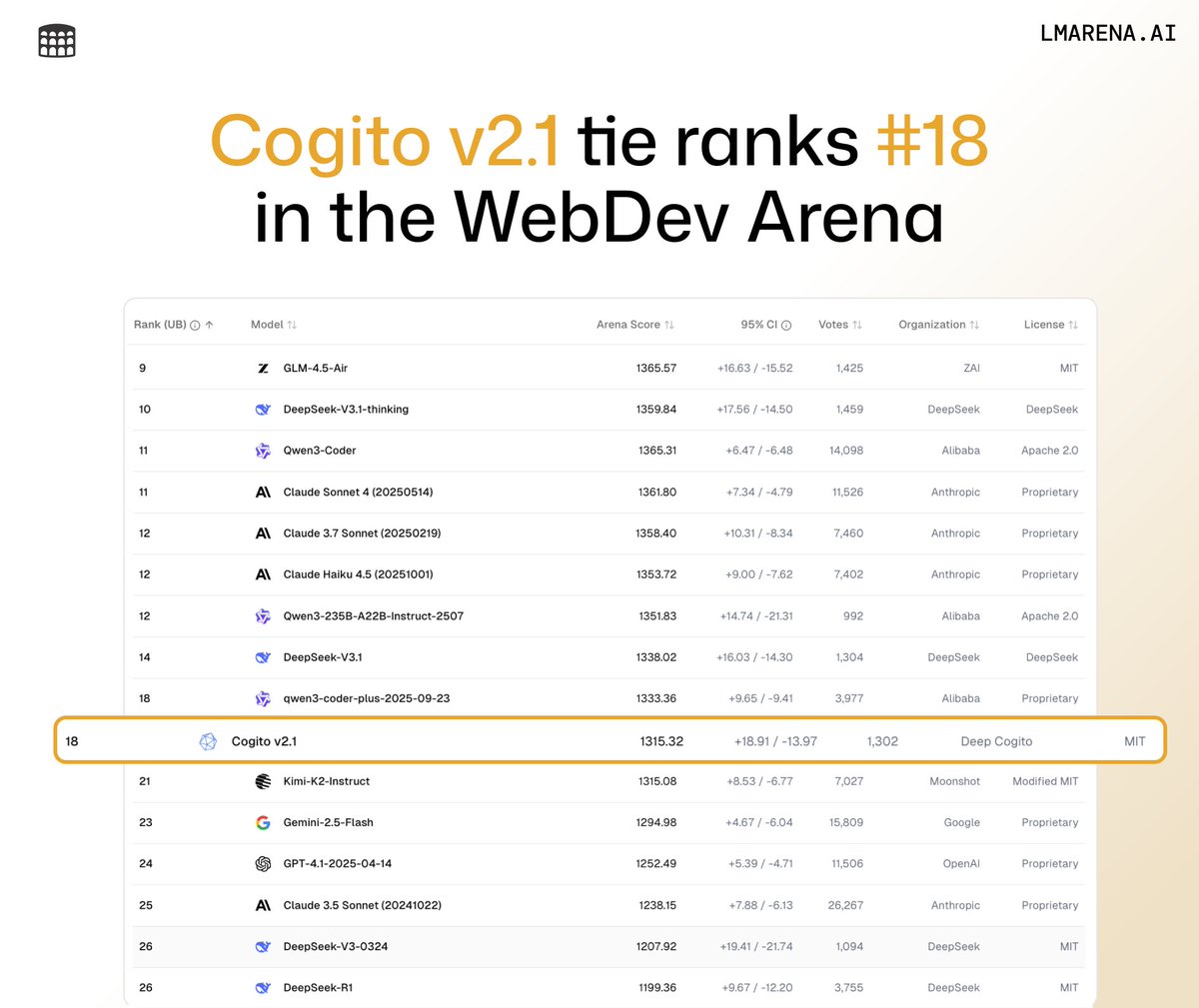
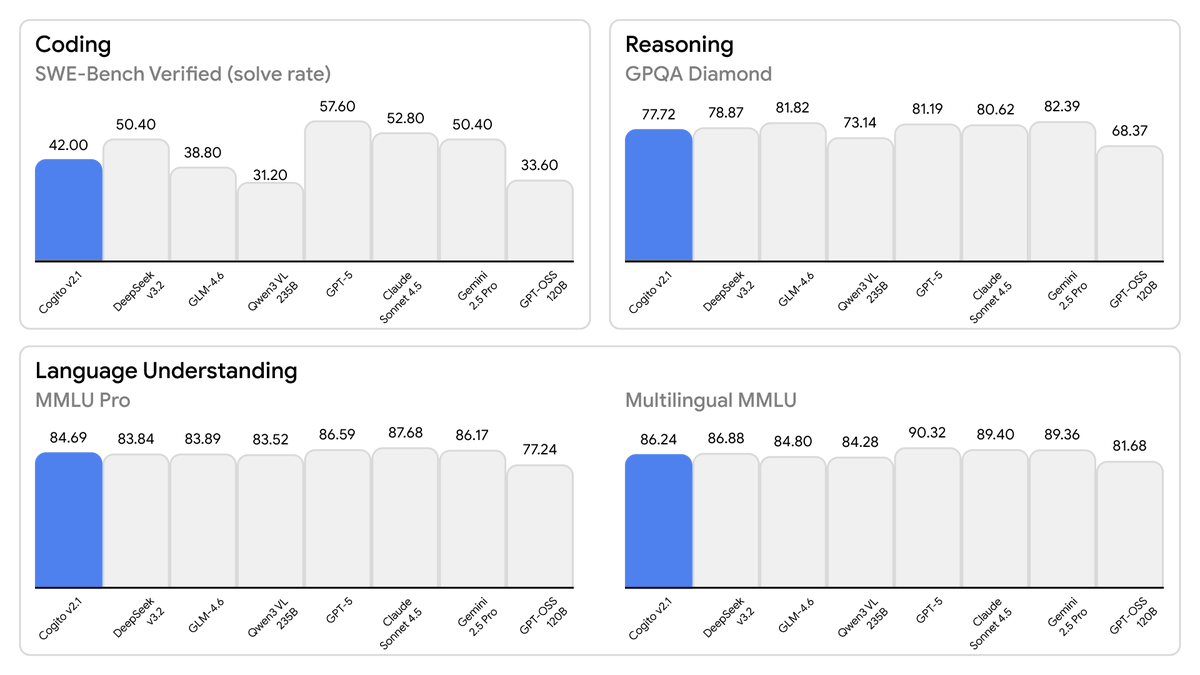
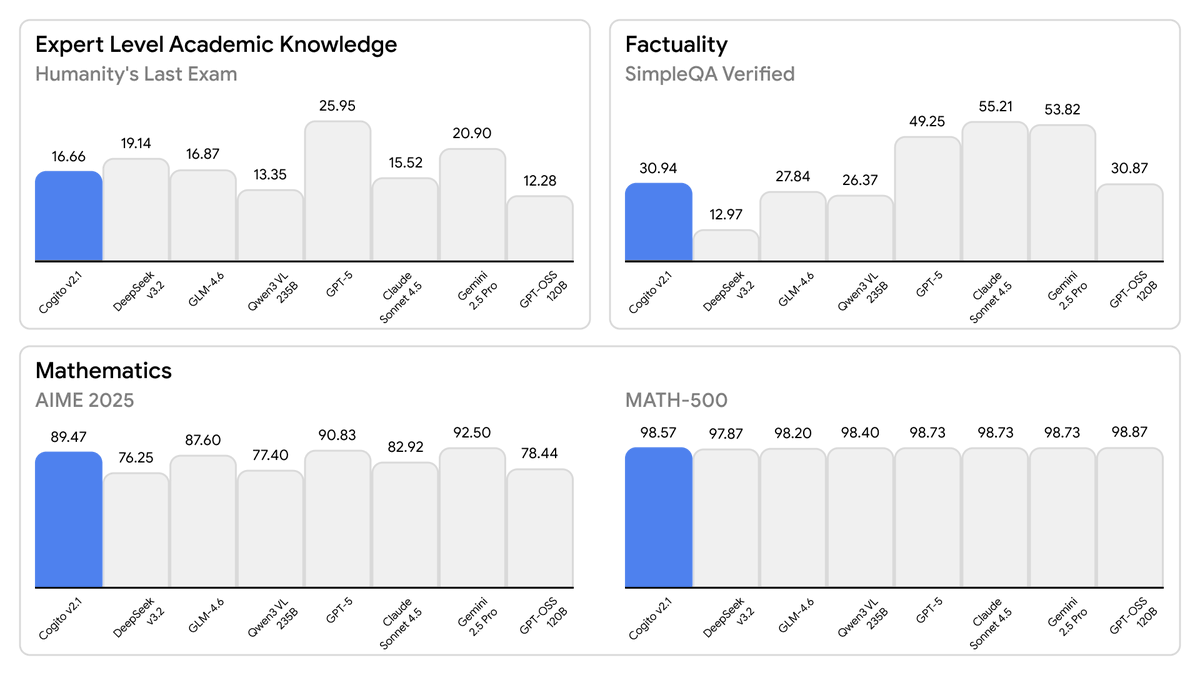
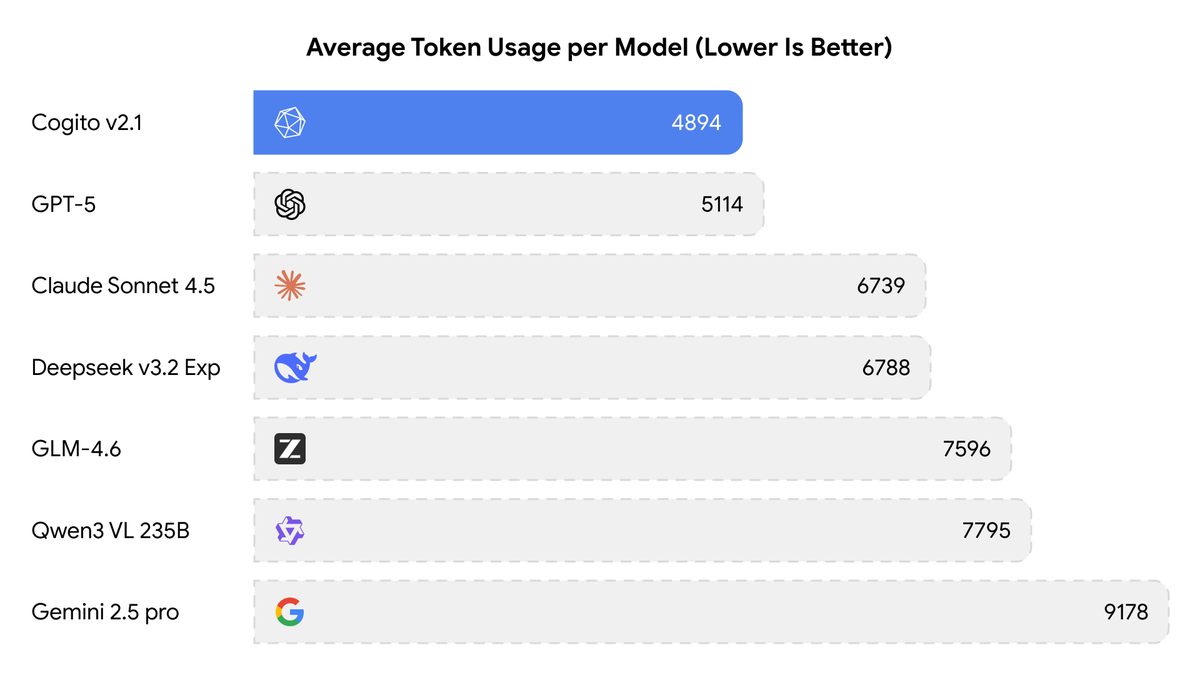
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B. On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of OpenAI’s GPT-OSS, Nvidia’s Nemotron and Meta’s Llama). We also built an interface where you can try the model (it’s free and we don’t store any chats): chat.deepcogito.com Additionally, you can download the model on @huggingface, or try it out on @openrouter, @togethercompute, @FireworksAI_HQ , @ollama cloud, @runpod, @baseten, or run it locally using @ollama or @UnslothAI. This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. You will also notice improvements across instruction following, coding, longer queries, multi-turn and creativity. 📌 Model Weights: huggingface.co/collections/de… 📌Openrouter: openrouter.ai/deepcogito/cog… 📌 HF Blog: huggingface.co/blog/deepcogit… Some notes on our approach + design choices below 👇