Sabitlenmiş Tweet

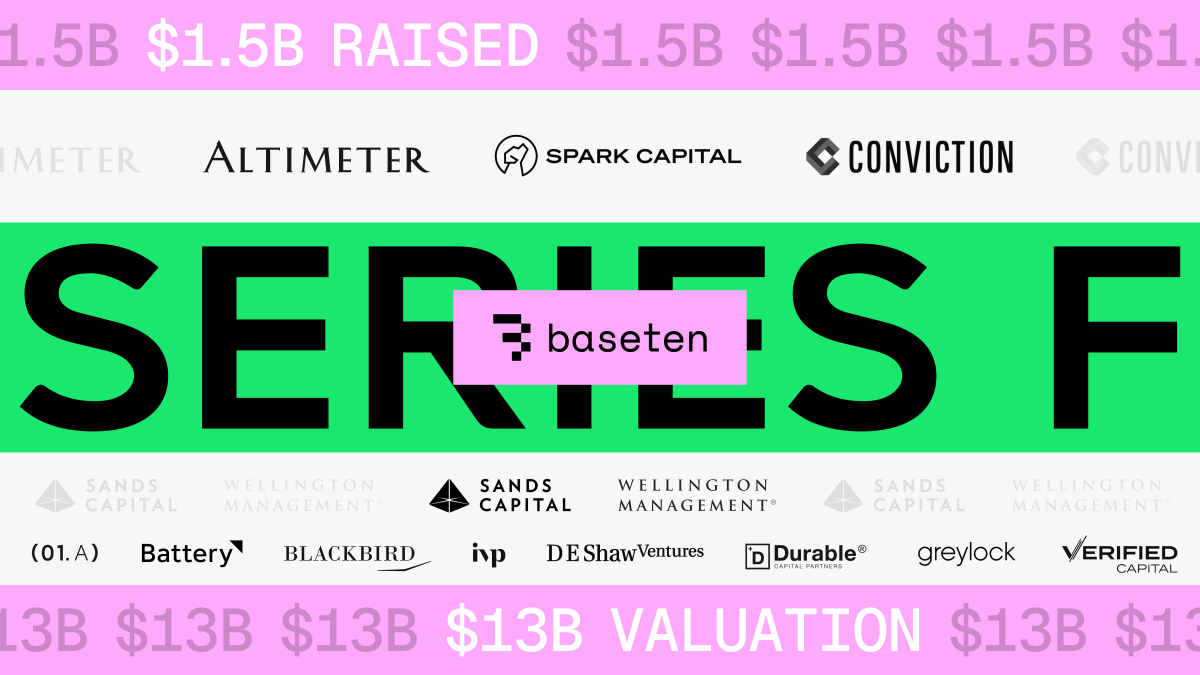
We’re excited to announce our $1.5B Series F.
Baseten exists to help companies own their intelligence and run AI products in production with speed, reliability, and control. As we enter this next chapter, three things are clear:
1. Customers like Abridge, Clay, Cursor, Decagon, HubSpot, Lovable, Notion, and OpenEvidence are proving that AI can create transformational value across industries and workflows. They have built products where intelligence is core to the customer experience and central to the value they deliver.
2. Open models - like GLM 5.2 - are now exceptionally strong, and the quality gap with leading closed models is smaller than ever. We’re seeing more companies turn to open and specialized models for better economics, performance, and ownership over their stack. Baseten provides the fast, reliable inference layer to run those models in production across every modality.
3. Post-training is giving companies a path to turn their own data, evals, feedback, and judgment into durable technical advantage. The most sophisticated teams are already using RL and domain-specific optimization to outperform closed models on important tasks and workflows. This will become a defining capability for every company building at the application layer.
We're excited to accelerate progress to this future of owned intelligence.
Thank you to our customers for your trust and partnership. We’re grateful to be building this future with you!
Tuhin Srivastava@tuhinone
English