Plume dev me-retweet
Plume dev
89 posts

Plume dev
@plume_cat_dev
French cat Front-end developer UI/UX enthusiast and @vuejs lover
Bergabung Mart 2026
19 Mengikuti0 Pengikut





@Auto_Propre Batterie solide pour en fini avec les blabla sur la pollution etc ...
Français

Quelle innovation attendez-vous le plus sur les prochaines générations de VE ?
Français

il va pas les nuke quand même ce connard ?
Disclose.tv@disclosetv
JUST IN - Trump on Iran: "A whole civilization will die tonight, never to be brought back again."
Français
Si vous répondez autre chose que la gen 1 et 2 vous êtes atteint de démence.
Oddy🌱@0ddy0ddish
If you could only play Pokémon on one of these consoles for the rest of your life. 👾 which one would you pick and why?
Français
Ça bouge pas.
Cette ville, quand on y vit ne laisse pas indifférent.
La musique, les gens, la culture, ça bouillonne et c'est vraiment une ville British avec tout ce que ça comporte de positif et négatif 😅
BFM Business@bfmbusiness
La ville de Manchester renaît économiquement 🏙️ L'ancienne capitale mondiale de l'industrie textile qui a connu des fermetures massives d'usines dans les années 70-80, renait de ses cendres . Depuis 10 ans, la ville connait la croissance la plus rapide du pays. 🎙️@CocquempotN
Français

si vous l'avez jamais fait, faites le.
Bella@BellaBaddie__
Be honest for a second: could you travel alone for a month with no friends, no partner, just you?
Français
@QifranTv @Marcuszeboulet Facile aussi ahah mais oui y'a du sens !
Français

@plume_cat_dev @Marcuszeboulet Respawn , la classe. et ca resume tout.
Français

Bon, ben reste plus qu'à trouver un nom qui claque... 🥳 Des idées les ptizamis ?
RTL France@RTLFrance
La chaîne Game One, arrêtée en décembre, va renaître sous un autre nom s.rtl.fr/2I8uN
Français
@bcassoret Mais vous ne pensez pas qu'un jour, ils discrimineront l'élec classic de l'elec pour la voiture ?
La surtaxer pour financer les routes qui s'abîme plus sous le poids des lourdes voitures électriques ?
(Pas anti VE ici, mais c'est pour moi pas du tout impossible)
Français

3 ans qu'on me dit qu'une taxe sur les voitures électriques va arriver.... L'électricité est déjà bien taxée (1/3 de la facture). On roule pour 2,5€ au 100km, il y a de la marge. Un jour une taxe au km, oui, mais comme le prix d'achat est en baisse...
Français
@tytoine56 @Capetlevrai Bah via l'IDE oui.
Antigravity par contre oui, l'IDE en lui même est mal fork, que des problème quand je suis sous VPN + WSL.
Français

@plume_cat_dev @Capetlevrai Gémini web et cli ? Pas de problèmes non plus.
Par contre Antigravity que des problèmes.
Français

Incroyable pour 23€ / mois j’ai Google Antigravity, Gemini Banana Pro 2 et 5 To de stockage Cloud franchement c’est carré

Steren@steren
Google AI Pro was bumped from 2TB to 5TB, no price change. We can all thank @shimritby
Français
@OXYSMONDE Les goûts et les couleurs.
Je pense que malheureusement pour toi, ce style graphique serait plébiscité :/
Français

les mots ne pourront jamais décrire à quel point je déteste ce style graphique et à quel point je suis heureux que GF ne soit pas parti dans cette direction
UndreamedPanic@UndreamedPanic
Gamma Emerald from about 1 year ago
Français
@JournalDuGeek Roole maps est clairement une bonne app. Il y'a encore des manques (renommer les favoris par ex) mais l'App est fluide, jolie, les itinéraires sont ok (un cran en dessous de Waze je pense encore), et le prix du trajet, les station essences intégré c'est très cool.
Français

Adieu Waze ? Ce GPS français étonne par ses fonctions que Google n’a pas ! journaldugeek.com/2026/04/05/adi…
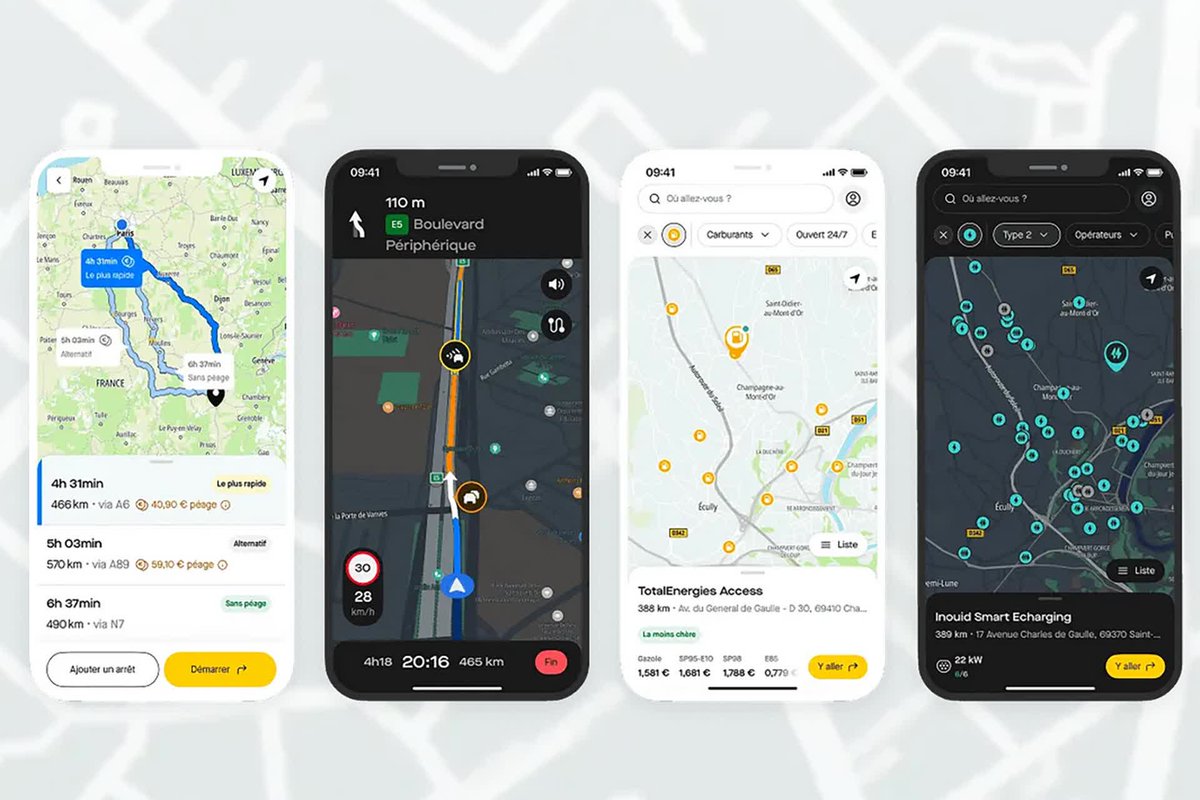
Français
@tytoine56 @Capetlevrai Comment vous faite ? 4 mois que j'utilise quotidiennement Gemini et j'ai jamais eu de limite ?
Français
Avec les quotas Antigravity qui ne cessent de s’effondrer… Avant, c’était 5 heures ; maintenant, si tu vas jusqu’à 5 heures, tu te prends une semaine pendant laquelle tu ne peux plus l’utiliser.
J’ai passé le mois de janvier avec Antigravity ; maintenant, en à peine une journée, j’explose le quota et je me retrouve avec un reset dans 6j...
Français

Mettre des plaques aux vélos et imposer le permis aux cyclistes ? La question est posée.
cleanrider.com/actus/et-si-on…
Français
@nolan_173843 Il faut lever les normes de sécurité pour que les voitures soient de nouveau légère et plus petite oui.
Français

je vous laisse comparer un véhicule de 1998 stationné sur une place construite en 1984 et une autre en 2012.
je pense qu’on sait très bien d’où vient le problème.


20 Minutes@20Minutes
« Une prise de tête » ➡️ 20min.fr/WTm
Français
@soubiran_ @JulienTechInvst J'y connais rien j'avoue côté hardware et software IA.
Impossible de faire tourner des modèle moyen et utile sur des machine a double GPU (2080/360TI par ex) ?
Français

@JulienTechInvst Oooh merci de remettre les pendules à l'heure 😌
Français

Je quote le mec parce que je vois passer ce genre de commentaires régulièrement. L’IA locale c’est un fantasme.
Globalement, pour faire de l’inférence, il faut 1) charger le modèle, 2) charger le contexte dans le KV-cache.
Il y a globalement 3 précisions possibles en inférence: le BF16/FP16, le FP8/INT8 et le FP4/INT4. La majorité des processeurs (CPU ou GPU) ne supportent que le BF16, et seul les modèles professionnels de chez Nvidia (B200/300) supportent le FP4/INT4.
Juste sur le chargement du modèle en RAM, 1 paramètre c’est 2 octets en BF16/FP16, 1 octet en FP8/INT8, et 4 bits en FP4/INT4.
Donc pour 1B de paramètres (la majorité des modèles font 7B et plus), il faut au moins:
- 2Go de RAM en BF16/FP16
- 1Go de RAM en FP8/INT8
- 500Mo de RAM en FP4/INT4
Ça c’est juste pour charger le modèle. Le FP8 est amplement suffisant pour des tâches d’inférence basiques et commencent par être supportés par de plus en plus de GPU/NPUs donc c’est plutôt de bon augure pour l’utilisation de modèles en local.
Cependant, 1B de paramètres, comme dit plus haut, ça n’existe pas vraiment et il faut compter au moins 7B de paramètres pour des versions mini. Avec l’augmentation de la taille des modèles, le MoE et autre, faudra plutôt compter 10-20B de paramètres d’ici peu de temps pour un truc utilisable. Donc entre 10 et 20Go de RAM juste pour charger le modèle.
À ça, on y ajoute un contexte. Disons 20k tokens de contexte, ce qui n’est objectivement pas grand chose (environ 15k mots - seulement du texte). Là c’est plus compliqué à calculer car il y a des paramètres propres à chaque modèle et à la configuration de ce dernier (cf le papier de Google).
La formule simplifiée qu’on peut utiliser est la suivante:
KV-cache_size ≈ 2 x L x hidden_size x T x precision
Avec L le nombre de couches, hidden_size la configuration du modèle, T le nombre de token de contexte et precision, la précision choisie.
Donc avec 20k tokens de contexte et un modèle Llama-like (4096 de hidden_size et 32 couches), on a:
- 10,5Go de RAM en BF16/FP16
- 5,2Go de RAM en FP8/INT8
- 2,6Go de RAM en FP4/INT4
Donc il faudrait minimum 15Go de RAM disponible sur le processeur (soit en VRAM si GPU externe, soit en mémoire unifiée) juste pour faire tourner un modèle basique avec des capacités réduites. La majorité des PCs modernes grand public dispos sur le marché n’ont pas la capacité de faire tourner le modèle et l’OS sans taper dans le swap.
Et là je parle même pas de la bande passante de la RAM qui limitera de facto l’output dans les 10-20 tokens/seconde maximum.
Bref, à moins de mettre de la HBM en masse et donc de voir le prix du parc informatique flamber, personne ne fera tourner de modèle en local pour des tâches sérieuses. C’est déjà suffisamment dur de le faire sur des cartes à plus de 40k$.
Et qu’on vienne pas me dire « oui mais pour un usage récréatif », parce que ce que les gens veulent c’est pouvoir balancer des pdfs, des images et autre, et là, le contexte explose et il faudra souvent bien plus de 100 à 200k tokens
Didier Sampaolo@dsampaolo
@sglaas À moyen terme, on aura tous des LLMs qui tournent en local. Que ça soit Google avec ses TPU (déjà embarqués de base sur les Pixel) ou Taalas avec ses models hardware, je pense pas que globalement l'inférence se fera dans un Cloud très longtemps.
Français