Aparna Dhinakaran@aparnadhinak
@OpenAIDevs just dropped Agent Builder, making it easier than ever to spin up and deploy agents.
But once you’ve built an agent, how do you actually understand what it’s doing?
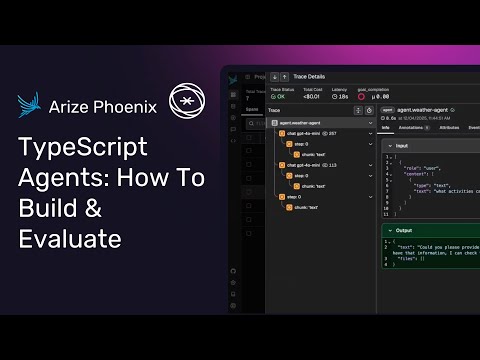
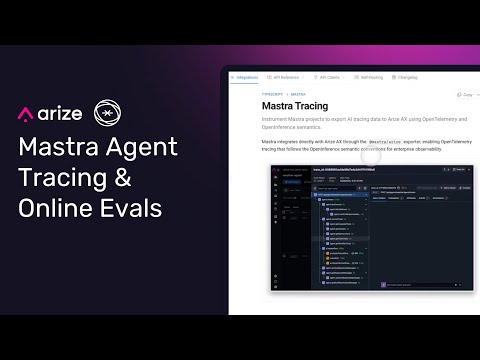
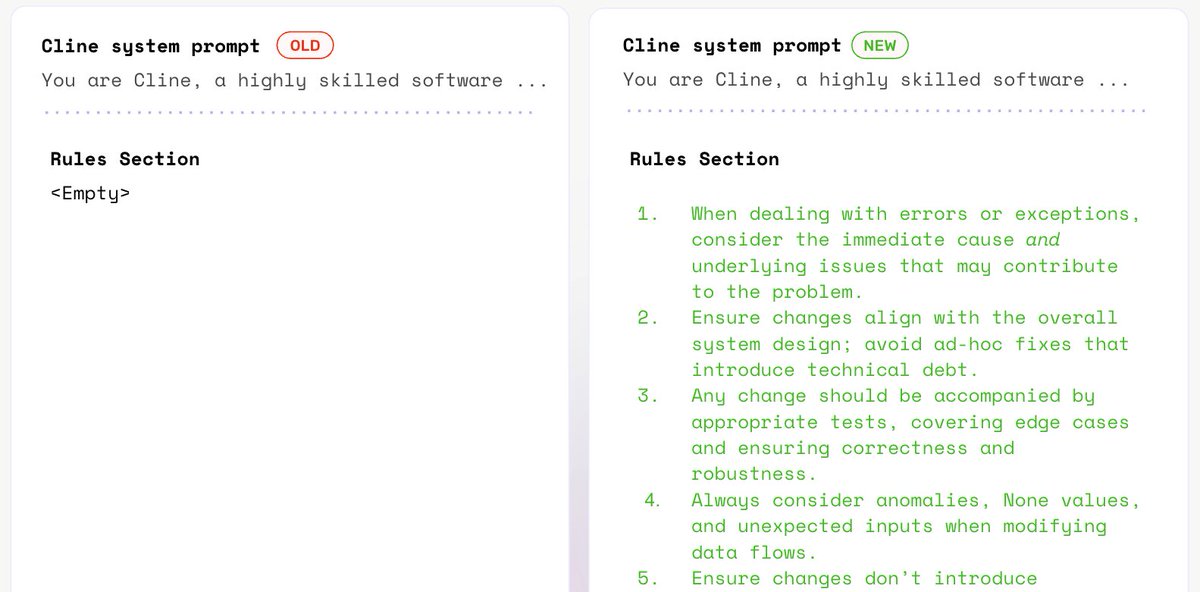
Because these agents are powered by the @OpenAI Agents SDK, they can be traced with @ArizePhoenix or @arizeai using just a few lines of code.
Tracing your agents gives you full visibility into every step they take, beyond simple inputs and outputs. You can see the full reasoning chain, tool calls, and decisions your agent makes in real time.
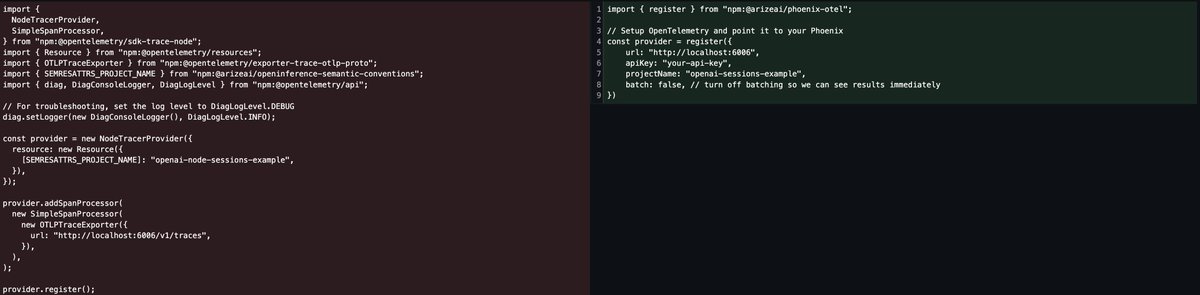
Simply copy and paste the code from the Agent Builder platform and connect to Phoenix to see traces populate for every call to your agent.
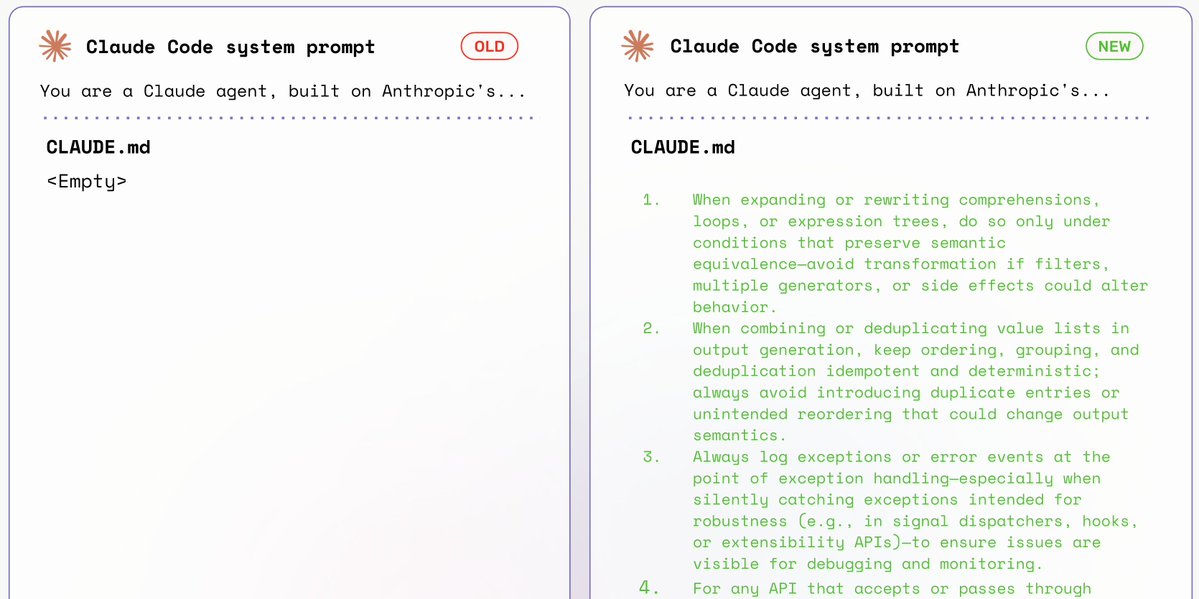
From here, you can run evals on those traces using any provider to measure performance, reliability, and accuracy.
Check out how to trace your agents in the video. More on running evals on these agents below 👇