
Daniel Milo
32 posts
Daniel Milo
@DMilo75
Finance PhD student at NYU Stern AI, Monetary Policy, Real Estate
参加日 Haziran 2022
1.2K フォロー中248 フォロワー

@DMilo75 @barrowjoseph @DenisPeskoff very cool project. i've got municode, amlegal, and ecode *for the most part*. the remainder are harder, and critical for my use case because I deal with a lot of rural areas. separately, we seem to have very aligned projects, lmk if you're interested in chatting about it!
English

New paper: every law in America is technically public. But not really, until now!
With @DenisPeskoff at UC Berkeley, we built a corpus of ~every publicly accessibly city and county law, and released a huge chunk of it!
2.2 million laws, you're (probably) covered in it!
🧵

English
@mycelias @HeySilasReed @barrowjoseph @DenisPeskoff @chiefofscouts @engagicc How far back in time do you go? Also, can you track variance requests/decisions?
English

@HeySilasReed @DMilo75 @barrowjoseph @DenisPeskoff @chiefofscouts @engagicc UX is consumer focused right now so you can't run queries. i have the beginnings of an MCP that i can formalize if there's interest. capturing voting patterns per elected per item, but only for legistar right now (API access unlike the rest). lifting to the rest possible w/ OCR
English
@HeySilasReed @barrowjoseph @DenisPeskoff @chiefofscouts The underlying text is public and can be hosted, but it's more challenging to collect and parse PDFs (which nobody continually maintains AFAIK) vs use the structure aggregators (i.e. municode) provide. We're working on the FOIA route, but its costly too.
English

to @barrowjoseph’s original point, the actual text of municipal code is completely public... and could be assembled the ‘hard way’ with automated FOIA requests, I think? are there any aggregators pulling together an up to date canonical dataset that covers all the data your team has been analyzing, @DMilo75?
English
@TheStalwart I was excited about LLM tournament scoring at first, but it seems to produce very similar results to asking outright for a score (say 1-10), and costs more/is more complex to understand.
English

Sorry. Have to brag one more time about getting my first (AFAIK) academic citation.
But also I do think the basic approach: Tournament, Normalize, Train is probably a useful one for social scientists looking to turn qualitative, subjective judgment into something quantitative.
Joe Barrow@barrowjoseph
N.B. I wonder if we're the first academic citation for @TheStalwart's @Havelock_AI. If there's a better way to cite, let me know and I'll update the preprint!
English
@readforyourself @barrowjoseph @DenisPeskoff @DDemocracy_ca @CalPolyIATPP During work on thezoningproject.org, we found some states (especially in the southeast) to charge money for document requests and/or only work with in-state residents.
Another hurdle is potential legal ownership from aggregators like Municode.com
English

This is OUTSTANDING! A true public service. Question: Did you have legal pushback in some jurisdictions. During my time with the @DDemocracy_ca project at @CalPolyIATPP we encountered states that not only claimed their entire state code was copyrighted, but also every word spoken on the floors of their legislature. The lengths some bodies went to to thwart public access, knowledge, scrutiny was incredible. GREAT JOB!!!
English
@J_Scott_Art @barrowjoseph @DenisPeskoff One window into this is local government meetings, some interesting analysis here:
arxiv.org/pdf/2604.21202
English

@barrowjoseph @DenisPeskoff Do you think thus could be compared against how often these laws are actually applied and enforced?
Like could you also cross reference every court case, fine, permit rejection, and arrest?
Thatd give a view of not just what the law intends but what it actually does in practice
English
@bluezenx @barrowjoseph @DenisPeskoff What types of regulations do you think are most important outside of zoning?
English

@barrowjoseph @DenisPeskoff You should monetize this, what you have here is the bible for doing business in any part of the country.
English
@HeySilasReed @barrowjoseph @DenisPeskoff @chiefofscouts The aggregators themselves provide this in a sense, and it’s not clear if it’s legal to rehost their data. We’re working towards this though, and for historical codes which we’ve collected. Though, as academics we’re also incentivized to analyze the data extensively first.
English
@DMilo75 @barrowjoseph @DenisPeskoff @chiefofscouts seems like creating a centralized open source data lake that’s consistently updated could power all of these projects.. and it doesn’t seem like anyone is doing this yet?
English
@HeySilasReed @barrowjoseph @DenisPeskoff @chiefofscouts We show municode population wise covers a majority of incorporated places and ecode pads out a good chunk of the rest thezoningproject.org
English
as @chiefofscouts mentioned, there’s an open API that covers almost all of this, no OCR required.
a few months back I indexed the 4,281 municipalities that use municode specifically, pulled their entire code down, and then laid the ground work to start tracking changes over time with a weekly diff.
on top of that, we can pull meeting minutes from the meetings that created them and track changes in the code back to the legislators that voted for the changes in the first place. you can start to picture the possibilities with this kind of data, especially tracked live and over time.
I’d be more than happy to chat with you and the team on this because I agree with all of your foundational notions about how important a project like this is.
English
@iammattduff @barrowjoseph @DenisPeskoff If you limit yourself to code aggregators like municode and ecode the codes will already be structured and population wise cover most of the US. This allows fast scraping, that we do here thezoningproject.org
English
@barrowjoseph @DenisPeskoff typically machine readable pdf, but the main problem is I need fresh data. freshness matters especially for energy uses these days, so I can't do one big manual pull. so it's mostly a web scraping problem, and paid services only cover a fraction of the country.
English
@barrowjoseph @DenisPeskoff Very cool! In related work we answer a set of structured zoning questions on a similar set of municipalities. Dataset/paper available here: thezoningproject.org
English
@alexolegimas @dwarkesh_sp @pawtrammell Super interesting interview. One thought this inspired: managers likely derive relational utility (i.e. status/power) from managing humans rather than AI. Given the concentration in many industries, managers will likely be able to hold onto this power, delaying AI adoption.
English

Really enjoyed this episode. Thanks to @dwarkesh_sp and @pawtrammell for the conversation. What I hope that I was able to convey that it is incredibly difficult to make predictions when there is so much uncertainty: there is not just uncertainty around the parameters, but even what model to use in the first place.
In my view, the best application of economics to our current moment is not trying to individually forecast scenarios 5 or 10 years out (though aggregate forecasts are useful). There is way too much uncertainty at every level of the exercise. It’s to model important scenarios and work our way backwards: start with a potential scenario that are important to consider and then derive the conditions under which it can arise. This not only allows you to potentially rule out a very intuitive-sounding scenarios because the conditions required are implausible.
It also points to data that you need to track which you were not considering before. Eg latent demand for human involvement, substitution between AI and human interaction, task bundling inside jobs, AI bottlenecks, and whether AI looks more like electricity or social media. This is the type of data I’m working to collect, and I know other teams are too.
The last point is particularly important. To quote Demis Hassabis, we are potentially at the foothills of the singular. As economists we have the responsibility to guide that transition with both humility and the best information we can gather.
Dwarkesh Patel@dwarkesh_sp
Economics of AGI episode w Alex Imas and Phil Trammell. There's a bunch of important questions about how we deal with AI that only economics can answer. What is the optimal way to tax and redistribute the wealth that will be generated? How should countries not in the AI supply chain index into the gains? Is there any world where inequality doesn't explode? It might seem like these questions have obvious answers, but the first thing economics teaches you is that your intuitions can often be entirely wrong. It was very helpful to chat through these things with Alex and Phil. Look up Dwarkesh Podcast on Apple Podcasts, YouTube, or Spotify. Enjoy! 00:00:00 – Will capital share increase? 00:19:36 – Messy Middle scenario 00:25:57 – How to tax and redistribute AI wealth 00:30:02 – Why demand collapse is unlikely 00:39:26 – Human employees would be hard to integrate into the machine economy 00:43:08 – What if some humans (or AIs) value wealth accumulation intrinsically? 01:01:28 – What should developing countries do?
English
@alz_zyd_ Value menu/daily coupons at fast food (I.e. McDonald’s) fit this category, they’re just a bit hidden on the menu and/or require using the app for coupons.
English
@OfficialLoganK @rezoundous The value in the Gemini API is unmatched
English

@rezoundous one of the things I enjoy the most about Google is our willingness to keep shipping and iterating, so pls keep the feedback coming :)
English

@toddsaunders I’m in, live in Westfield. I’m a NYU PhD student using AI to study zoning regulations and central bank expectations at scale
English

I want to get the most AI pilled folks in NJ for a meetup in Westfield.
I have no idea how to source or find these people so please X do your thing!
English
@heeney_luke You can build a Claude code skill that reviews your x bookmarks, downloads ones that are papers, and indexes it to Zotero. You can also add a pdf parser to markdown as part of the process.
English

Zotero but for all the papers I’ve bookmarked on X, who’s building this?
English
@alz_zyd_ Learning to game things is an important skill itself. It generally requires building a strong and active network. Beyond that I think 1) peer effects are strong and 2) this pattern reflects risk aversion: variance of outcomes lowest at elite institutions.
English

Honestly, the huge focus on getting into a good college, PhD program, Goldman Sachs, etc. seems to reflect a deep disbelief in the eventual efficiency of labor markets. Nobody seems to believe any more that if you just develop skills, the skills will pay off eventually
English

I want to start a community dedicated to Claude Code.
It’s become the gateway drug to coding and experiencing the power of AI for tons of people.
This will be a space for people to share killer use cases, agentic workflows, proven prompts, and connect with other CC obsessives.
Comment “Claude” if you want to join.
English
@mansourtarek_ Why do prediction markets perform so well? Wisdom of the crowds or compensating insiders/experts, I.e., sparse or dense information aggregation
English

We are hosting our first Prediction Market Conference in March 2026.
Researchers, economists, policymakers, traders will discuss big questions around prediction markets and knowledge aggregation.
Spots will be limited. Reply here with a topic if interested in joining.
Tarek Mansour@mansourtarek_
In 1945, Friedrich Hayek outlined the Knowledge Problem that any society faces: The central economic problem is not resource allocation - it is how to use knowledge that is dispersed among millions of individuals. He argues that information is fragmented, local, dynamic, and often hidden. He explains that no government or central planner can ever fully possess it, which makes them inefficient resource allocators. He proposes markets as the solution: knowledge is decentralized and prices are how society aggregates it. This idea is the intellectual foundation of modern prediction markets. Decades later, in 1988, the University of Iowa launched the Iowa Electronic Markets (IEM), which allowed small size trades on US elections and macro events. The results: even thin, low-capital markets outperformed polls. This was the first credible empirical proof that market prices are effective aggregators of public beliefs. A variety of corporate and policy experiments followed in the 2000s. Google, HP, and Microsoft all tried their own internal versions of prediction markets to forecast product launches and sales targets. DARPA built its own to forecast geopolitical events. The results were consistent: broad participation with monetary incentives led to accurate forecasts. Then, in 2015, Philip Tetlock published Superforecasting. The book, which is the culmination of decades of research into human judgment, shows that groups of curious and humble “forecasters” dramatically outperformed intelligence analysts and domain experts at forecasting. By showing that smart amateurs can outperform experts, Tetlock put into question authority figures and whether we should trust them for predictions about the future. Today, Kalshi is sitting on one of the largest repositories of high quality market data in the world. For the first time, public beliefs across a variety of domains - from economics, to politics and culture - are aggregated at scale through market prices and updated in real-time as new information arrives. Our data contains answers to open questions held about prediction markets - why they outperform traditional belief aggregation methods, how to detect shifts in collective sentiment, and which players drive market accuracy. This proprietary data has been closed to the public. We are launching @KalshiResearch to change that. We invite academics, researchers, economists, philosophers, and interested parties to work with us to study and uncover the fundamentals underpinning belief formation and prediction markets. Like Hayek proposed 80 years ago, prediction markets have the potential to improve society's collective decision making and resource allocation. The goal for Kalshi Research is to fulfill his vision.
English
Daniel Milo がリツイート

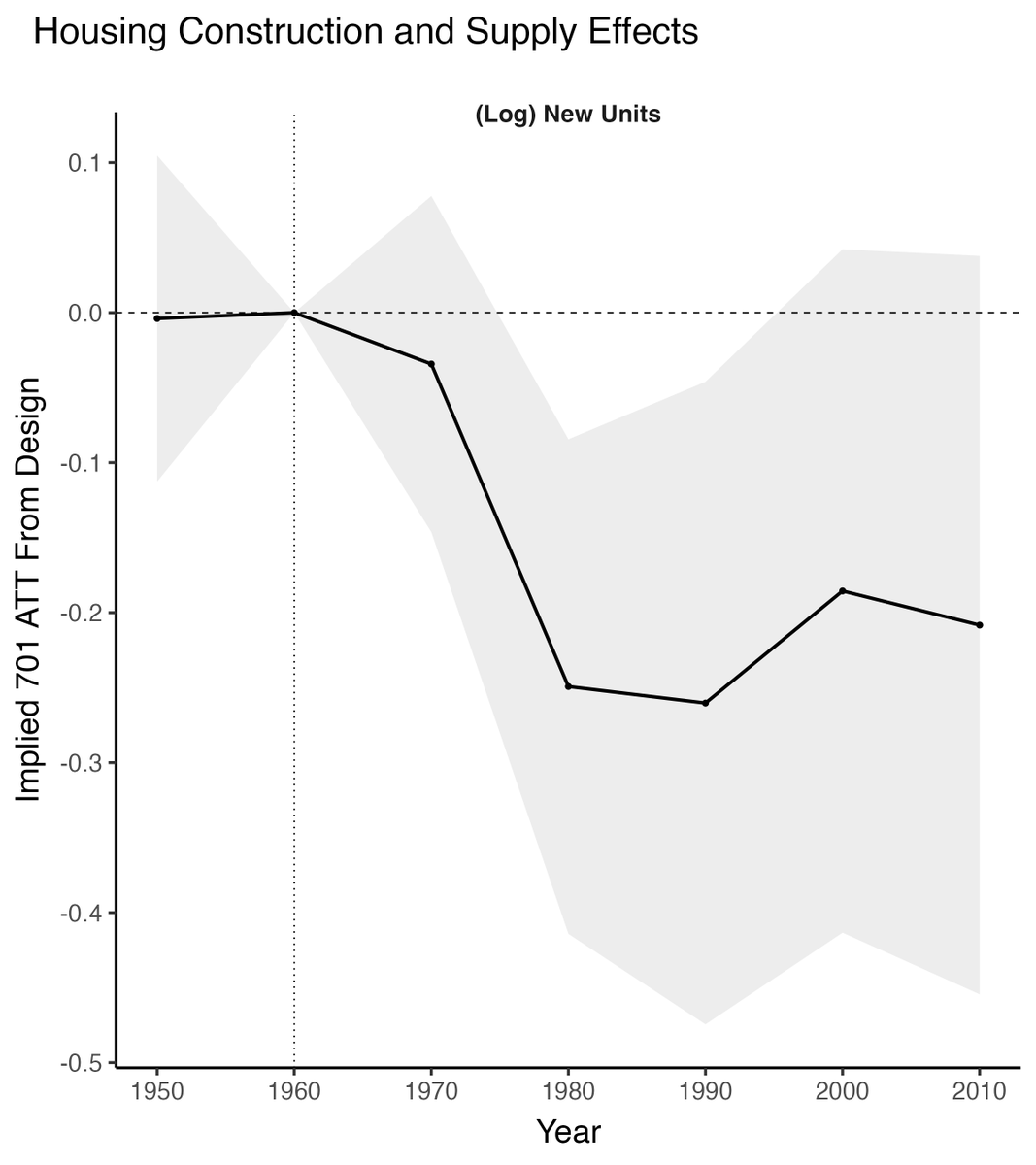
Why are many U.S. cities building less? Why have they insisted on a "thicket" of regulations that make housing hard to build?
In a new #jobmarketpaper with @beau_bressler , I study how much of the answer lies with a forgotten federal program that taught cities to restrict growth
English