固定されたツイート

"The model will converge anyway" - a compelling argument, and a costly misconception.
Two models. Same everything.
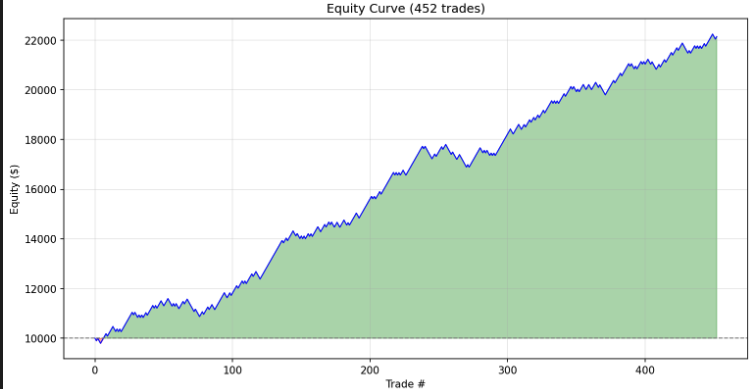
Model A, step 0: loss = 3.29 → starts learning immediately.
Model B, step 0: loss = 27 → spends the first 9,000 steps just getting back to where A started.
Model B didn't train for 10k steps. It trained for ~800.
The rest was debt repayment.
A bad initialization doesn't slow you down. It steals your training budget — silently, one "optimization" step at a time.
🧵

English