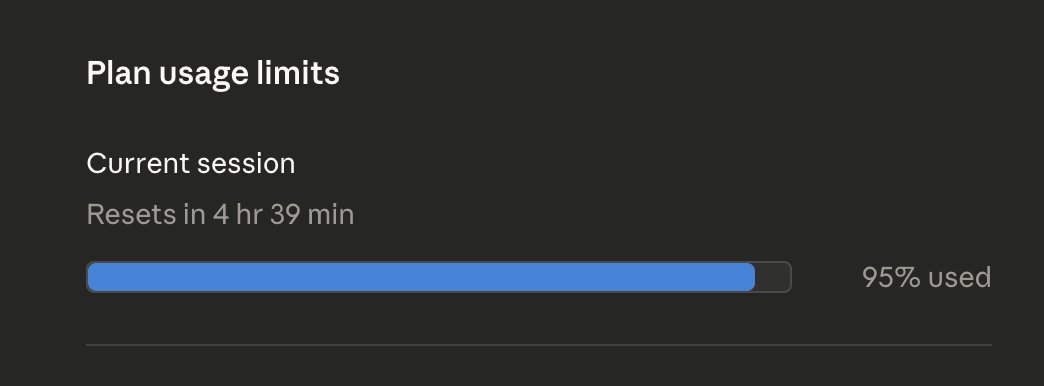
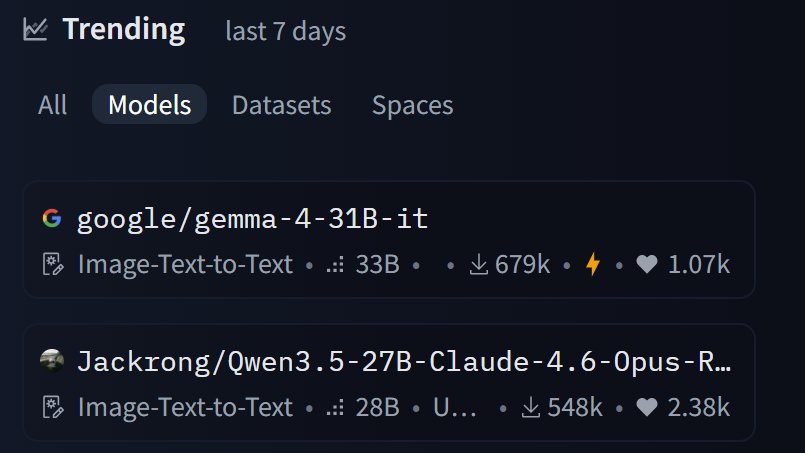
@TheAhmadOsman U can always get more on @InferXai
2 h100s 👀
English
Yashsmith shah
332 posts

@Yashsmith_dev
Just an engineer trying to turn curiosity into code | 8x hackathon winner incl NVIDIA AI hack | Tech club chair | currently in the GenAI & startup rabbit hole


@d4m1n i'm a bit confused why so many people say api tokens are sold at a loss this isn't true - these models are incredibly expensive compared to the gpu time cost there's potential for 90% margin depending on the model





If you have a Thunderbolt or USB4 eGPU and a Mac, today is the day you've been waiting for! Apple finally approved our driver for both AMD and NVIDIA. It's so easy to install now a Qwen could do it, then it can run that Qwen...