Sabitlenmiş Tweet

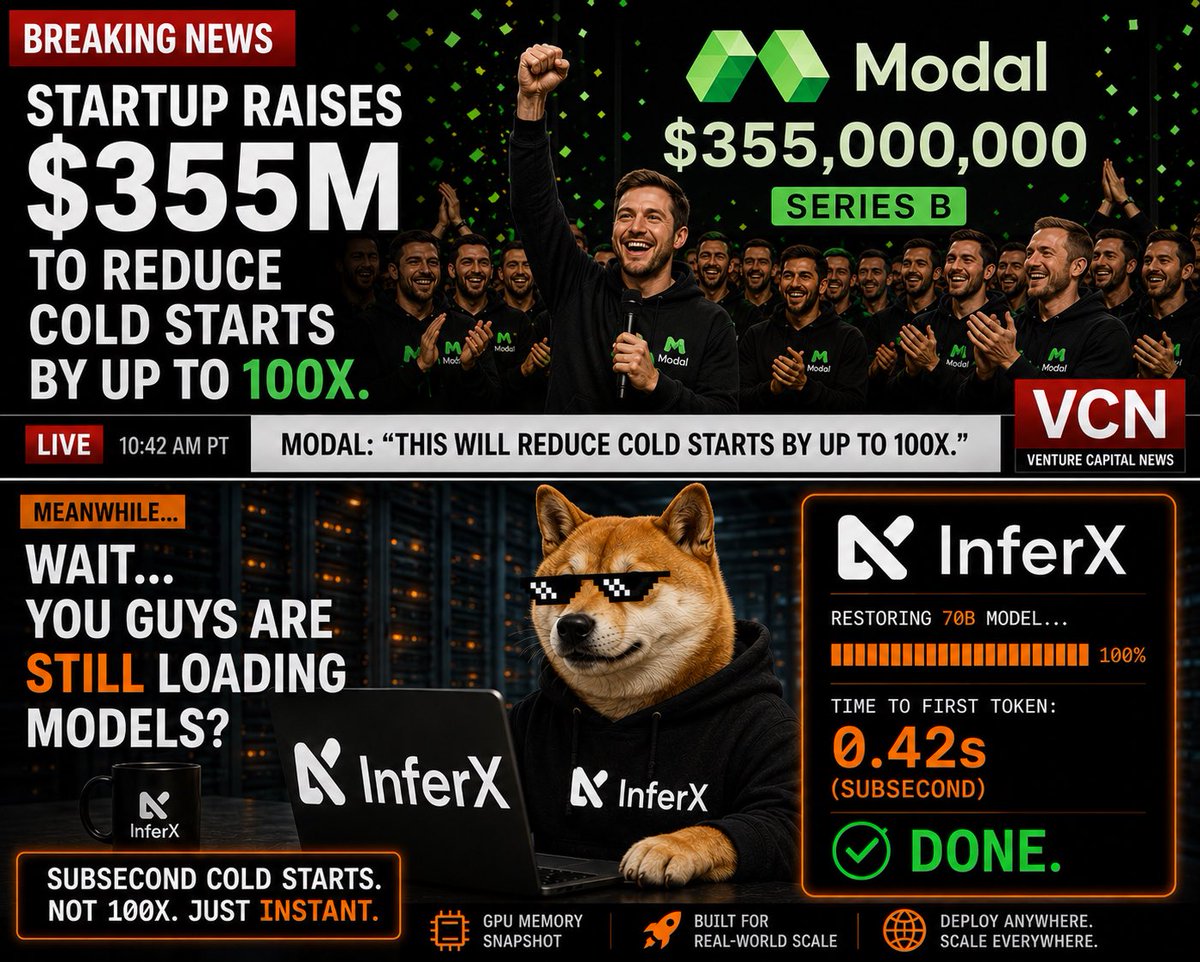
Sub-second Cold Starts for 32B Models | Live Demo & Technical Discussion
youtube.com/live/oI_eg5x1I…

YouTube
English
InferX
386 posts

@InferXai
Serverless GPU inference. Sub-Second cold starts — even for 32B(64GB)+ models. Scale to zero. No idle billing. https://t.co/GbD8l2JPy0
Reliability shouldn't require reserving GPUs. Serverless 2.0 is live on Fireworks: one API, 3 serving paths. → Standard: elastic default → Priority: sheds last under congestion, pricing ~1.5x standard → Fast: >100+ tok/s on Kimi K2.6 and GLM 5.1 Get started: fireworks.ai/blog/serverles…

The latest finding in the LangSmith Signal: Open Models are having a moment. 1 in 3 AI teams ran an open-weights model in April 2026, up from 1 in 5 nine months ago. The overall number of teams using open weights grew 3x. We’re seeing newer users choose open models at a higher rate than those who came before.
The latest finding in the LangSmith Signal: Open Models are having a moment. 1 in 3 AI teams ran an open-weights model in April 2026, up from 1 in 5 nine months ago. The overall number of teams using open weights grew 3x. We’re seeing newer users choose open models at a higher rate than those who came before.


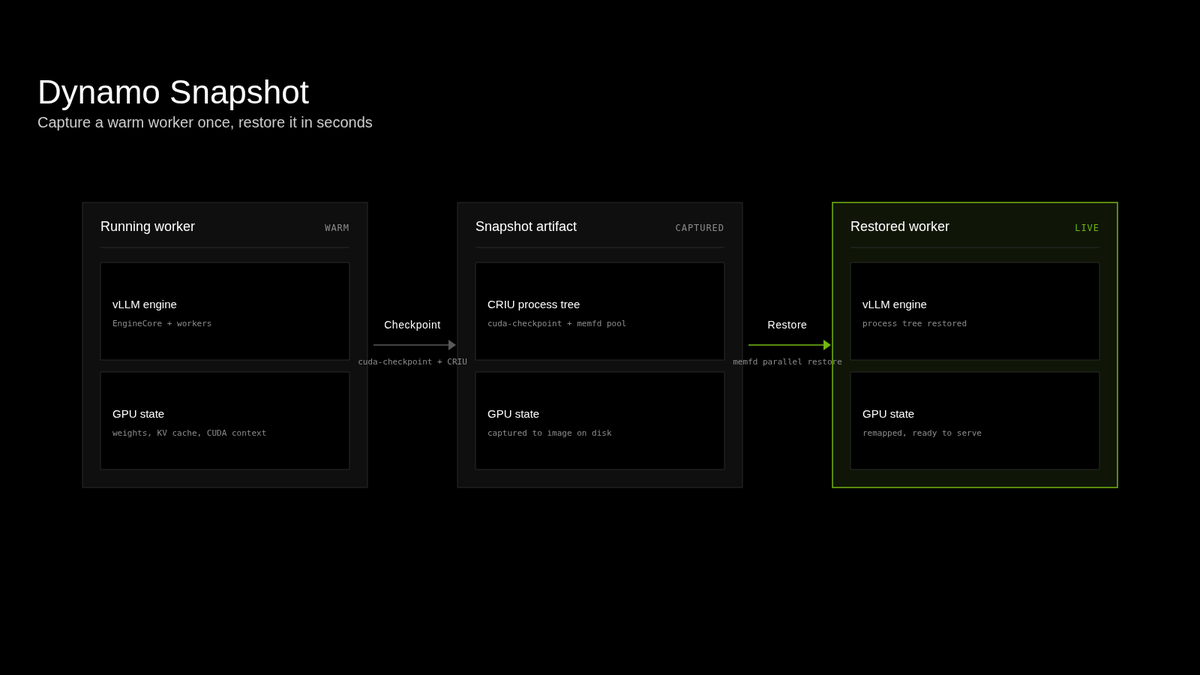
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds. In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests. Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.

It’s pronounced “Hermes”, not “Hermes”
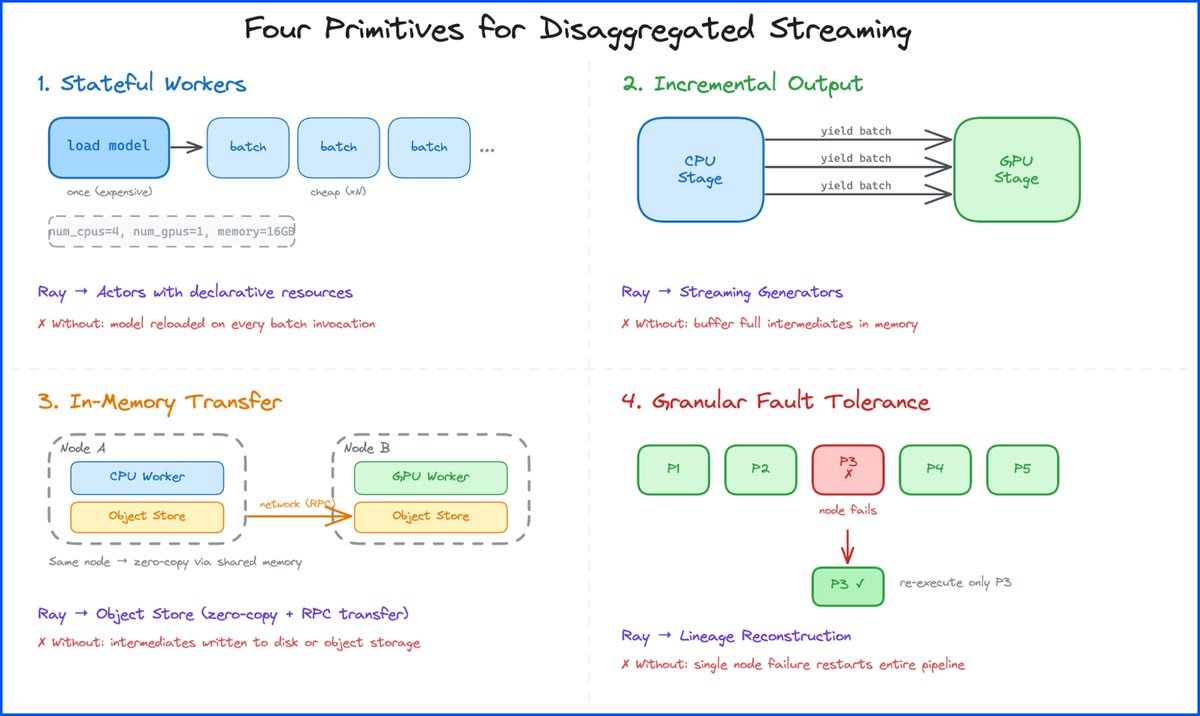
GPU utilization can drop below 50% in batch AI pipelines. Not because the model is slow, but because pipeline can’t feed GPUs fast enough. Learn how a unified CPU+GPU pipeline changes that. na2.hubs.ly/H05Dffy0

Live from Code with Claude London: we're launching self-hosted sandboxes (public beta) and MCP tunnels (research preview) in Claude Managed Agents. Run agents inside your own perimeter, with your security controls applied by default.