
固定されたツイート

After 3 months of non stop building, I’m back with a new daily posting series.
I just shipped three production AI projects (RAG system, job application agent, and GitHub portfolio reviewer).
Starting today, I’ll showcase one deep dive every day.
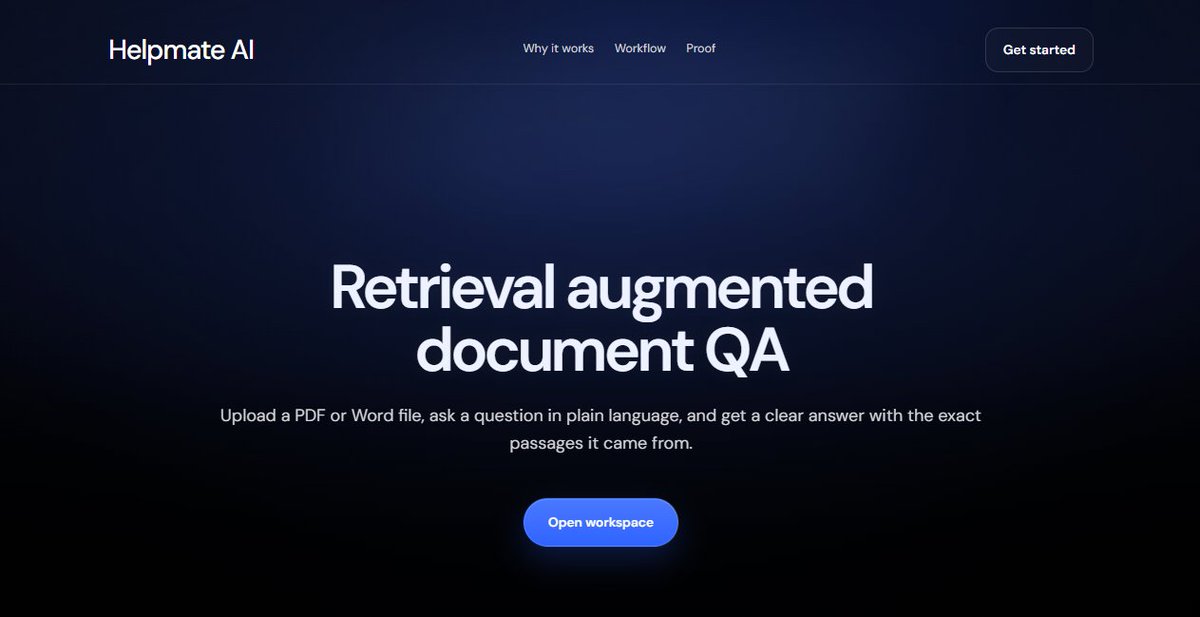
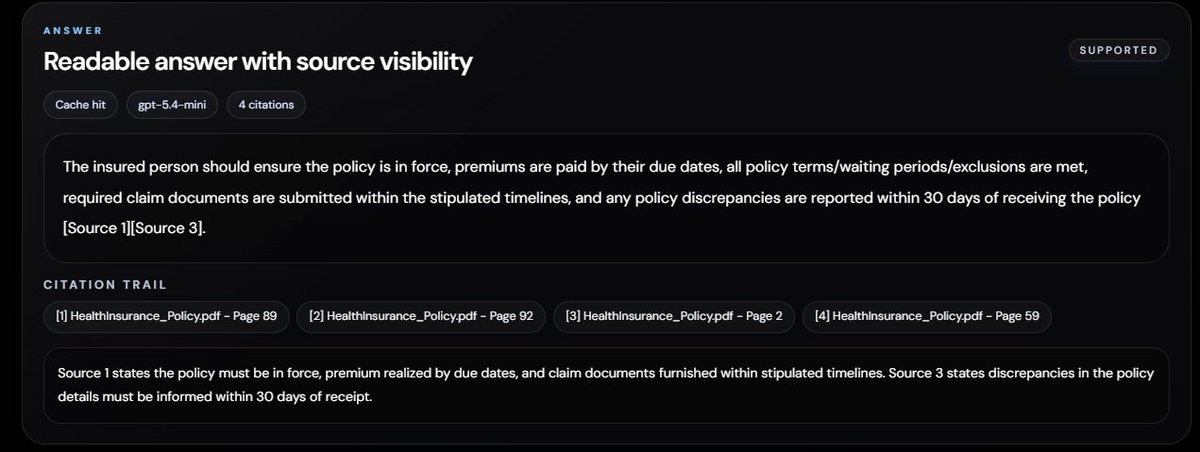
First up: My grounded RAG Q&A system that beats OpenAI File Search & Vectara on RAGAS benchmarks.
Live: helpmateai.xyz
English





