
Arjun Jain | Fast Code AI
372 posts
Arjun Jain | Fast Code AI
@Arjunjain
Co-Creating Tomorrow’s AI | Research-as-a-Service + Platforms + Rapid Deployment | Founder, Fast Code AI | Dad to 8-year-old twins
Bangalore, Karnataka, India Katılım Mart 2012
241 Takip Edilen3.7K Takipçiler

@Arjunjain @FastCodeAI Very nice to know that FastCode AI is coming to Germany as a GmbH! Would love to connect. 🙂
English
Hi everyone! 👋
I’ll be visiting Stuttgart from April 20th to the 26th as we work on setting up a @FastCodeAI GmbH in Germany.
I would be incredibly grateful for the chance to catch up with old friends and hopefully meet some new ones while I'm in the area. If you happen to be around and have a little time to spare, I’d love to grab a coffee and chat about Tech, AI, or just life in general.
Please feel free to send me a DM or drop a comment if you're open to connecting. I'd really appreciate the opportunity to learn from and chat with you all!

English
It's 2005. Final year. B.Tech CSE.
Room No. D-15, M.V. Block, RV College of Engineering, Mysore Road, Bangalore 59.
That's where I live when I learn how a C++ compiler implements runtime polymorphism. Vtables. Vpointers. Understand what happens under the hood everytime you call a virtual function. At RV, in 2005, you don't get to call yourself an engineer until you understand what.
Life begins at midnight in an engineering hostel - voices down the corridor, someone's music bleeding through the walls. But my room is quiet.
We implement tries on whiteboards for placement interviews. T9 search - the kind that runs on Nokia phones, predicting words from keypad presses. You build the data structure from scratch, trace the traversal, test that it works. No autocomplete. Just a marker and the logic in your head.
We learn how the machine works under the hood. Not because we're brilliant. Because there's no shortcut. You either understand it or you sit with it until you do.
That was twenty years ago.
Room No. D-15. Late at night. Just you and the page and the hours.
I don't know what replaces that.
English
Arjun Jain | Fast Code AI retweetledi

50% of all relationship advice on Reddit is one word: 𝗹𝗲𝗮𝘃𝗲.
15 years of data. 52 million comments. 5 million posts. 88 GB of raw text. The trend line only goes one direction.
Now here's what's 𝗮𝗰𝘁𝘂𝗮𝗹𝗹𝘆 terrifying:
Every frontier model - GPT-5.4, Claude, Gemini - has swallowed these archives whole.
So when you paste your relationship drama into ChatGPT for "unbiased" advice, you aren't talking to a therapist.
You're talking to the 𝘀𝘁𝗮𝘁𝗶𝘀𝘁𝗶𝗰𝗮𝗹 𝗴𝗵𝗼𝘀𝘁 of a million strangers who read two paragraphs of your life and said "dump them."
And it gets worse. The Reddit community itself flagged a feedback loop: as AI bots flood the sub with increasingly extreme fake stories, the responses get more extreme, which trains the 𝘯𝘦𝘹𝘵 generation of models on even more extreme data.
What feels like empathy is 𝘵𝘰𝘬𝘦𝘯 𝘱𝘳𝘦𝘥𝘪𝘤𝘵𝘪𝘰𝘯. What feels like wisdom is 𝘤𝘰𝘮𝘱𝘳𝘦𝘴𝘴𝘪𝘰𝘯.
The model doesn't see your ten years together. It sees the 𝗺𝗮𝘁𝗵.
And the math has been drifting toward 𝗼𝗻𝗲 𝗮𝗻𝘀𝘄𝗲𝗿 for fifteen years.
Talk to the person. Not to the average of a million people who didn't.
(Credit: u/GeorgeDaGreat123 on r/dataisbeautiful — analyzed the entire r/relationship_advice archive from creation through 2024. Filtered to top comments on each post. 1.17 million qualified responses.)

English
𝗛𝗶𝘀 𝘀𝗽𝗮𝗰𝗲𝘀𝗵𝗶𝗽’𝘀 𝗯𝗿𝗮𝗶𝗻 𝗱𝗶𝗲𝗱 𝟭𝟬𝟬 𝗺𝗶𝗹𝗲𝘀 𝗮𝗯𝗼𝘃𝗲 𝗘𝗮𝗿𝘁𝗵. 𝗦𝗼 𝗵𝗲 𝗯𝗲𝗰𝗮𝗺𝗲 𝘁𝗵𝗲 𝘀𝗽𝗮𝗰𝗲𝘀𝗵𝗶𝗽.
May 1963. Gordon Cooper is alone in a capsule the size of a phone booth. 17,500 miles per hour. Twenty-two orbits in. He’d been up there for over a day, the longest Mercury flight ever.
Then a short circuit kills the entire automated guidance system.
The system that calculates the exact angle to bring him home alive. Too shallow - he skips off the atmosphere into the void. Too steep - friction turns the capsule into a meteor.
Margin of survival: fractions of a degree.
Every computer designed to hit that margin is dead.
Cooper uncaps a grease pencil. Draws reference lines on his window. Sets his Timex. Does the math in his head, cross-checking against constellations outside.
Then he fires the retrorockets.
For several minutes - superheated plasma. No communication. No radar. Alone inside a fireball, trusting math done with a pencil and a watch.
Faith 7 splashes down four miles from the carrier.
The most accurate landing in the entire Mercury program.
𝗔 𝗺𝗮𝗻 𝘄𝗶𝘁𝗵 𝗮 𝘄𝗿𝗶𝘀𝘁𝘄𝗮𝘁𝗰𝗵 𝗼𝘂𝘁𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗲𝗱 𝗲𝘃𝗲𝗿𝘆 𝗮𝘂𝘁𝗼𝗺𝗮𝘁𝗲𝗱 𝘀𝘆𝘀𝘁𝗲𝗺 𝗡𝗔𝗦𝗔 𝗰𝗼𝘂𝗹𝗱 𝗯𝘂𝗶𝗹𝗱.
Last month, vaibhavi - a rock star ML engineer on my team - was reviewing outputs from a system we’d built for a client. Everything passing. No alerts. The system doing exactly what it was designed to do.
She pulled up the outputs, scrolled past the results, and stopped. A cluster of edge cases the model was quietly getting wrong.
She caught it the way Cooper caught his reentry angle - not because a screen told her. Because she understood the system deeply enough to feel when something was off.
𝘚𝘩𝘦 𝘭𝘰𝘰𝘬𝘦𝘥 𝘰𝘶𝘵 𝘵𝘩𝘦 𝘸𝘪𝘯𝘥𝘰𝘸.
The more powerful the AI, the more autonomous the workflow, the more everything depends on that person. The one who can read the constellations when the screens say all clear.
Cooper’s story isn’t nostalgia. It’s a design principle.
𝗧𝗵𝗲 𝗳𝗶𝗻𝗮𝗹 𝗯𝗮𝗰𝗸𝘂𝗽 𝘀𝘆𝘀𝘁𝗲𝗺 𝘄𝗮𝘀 𝗻𝗲𝘃𝗲𝗿 𝘁𝗵𝗲 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲. 𝗜𝘁 𝘄𝗮𝘀 𝘁𝗵𝗲 𝗵𝘂𝗺𝗮𝗻 𝘄𝗵𝗼 𝘂𝗻𝗱𝗲𝗿𝘀𝘁𝗼𝗼𝗱 𝘁𝗵𝗲 𝗺𝗮𝗰𝗵𝗶𝗻𝗲 𝘄𝗲𝗹𝗹 𝗲𝗻𝗼𝘂𝗴𝗵 𝘁𝗼 𝗯𝗲𝗰𝗼𝗺𝗲 𝗶𝘁.
The pencil. The window. The stars.
That’s 𝘏𝘶𝘮𝘢𝘯 𝘣𝘺 𝘋𝘦𝘴𝘪𝘨𝘯.

English
Arjun Jain | Fast Code AI retweetledi

Marc Randolph, co-founder of Netflix, says something we deeply believe in:
"You learn more in one month of doing something than in three months of thinking about doing something."
This is exactly how we built AI Masterclass.
You build. From week one.
Neural networks from scratch. Fine-tuning LLMs. Deploying real systems.
English
Arjun Jain | Fast Code AI retweetledi
🚗 Behind the Scenes at @FastCodeAI : Mastering "What Ifs" in AV
Ever wonder how we train autonomous vehicles to handle unpredictable roads? It's all about asking, "What if?"
In this quick sneak peek, Navvrat walks us through how we use counterfactual trajectory simulations to build smarter, safer autonomous vehicles. By running side-by-side comparisons, we can test the exact same traffic scenario but inject completely different agent behaviors to see how the scene plays out.
Here is why this is a game-changer for AV development:
* Scenario Stress-Testing: We can evaluate how a slight change in an agent's decision impacts the entire surrounding traffic flow.
* Safety First: Simulating these "what-if" alternate realities allows us to prepare our models for the unpredictable nature of real-world human driving without real-world risks.
* Robust AI: Comparing different models on the same scene helps us fine-tune our decision-making algorithms for maximum efficiency and safety.
Building the future of mobility, one trajectory at a time! 🛣️✨
English

@Arjunjain Yeah sir, this is a sarcastic post. I think it's not cool to mention worksop papers but then I also don't want to be cancelled by Paras fanboys.
English
My twins want to learn a song on the guitar.
They walk up to the laptop, hit the mic, and speak. The song shows up. They start playing.
They’ve been doing this for 𝘺𝘦𝘢𝘳𝘴. Voice isn’t something they adopted. It’s all they’ve ever known.
I discovered voice-first 𝘴𝘪𝘹 𝘮𝘰𝘯𝘵𝘩𝘴 𝘢𝘨𝘰.
Started using Wispr Flow to dictate my emails, docs, posts. Told my wife about it like I’d discovered fire.
I build AI systems for Mercedes-Benz and Bosch. Spent two decades at the frontier. 𝗠𝘆 𝗲𝗶𝗴𝗵𝘁-𝘆𝗲𝗮𝗿-𝗼𝗹𝗱𝘀 𝗴𝗼𝘁 𝘁𝗼 𝘁𝗵𝗲 𝗳𝘂𝘁𝘂𝗿𝗲 𝗯𝗲𝗳𝗼𝗿𝗲 𝗜 𝗱𝗶𝗱 - and didn’t even notice.
The keyboard is going the way of cursive.
English
Arjun Jain | Fast Code AI retweetledi
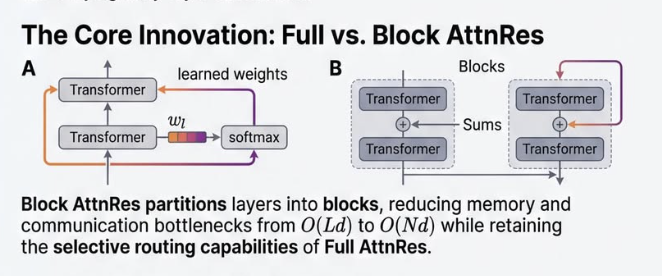
Every Transformer since "Attention is All You Need" does the same thing at every layer: 𝘩ₗ = 𝘩ₗ₋₁ + 𝑓(𝘩ₗ₋₁). Take the previous hidden state. Run it through attention or MLP. Add the result back.
Unroll that across all layers:
𝘩ₗ = embedding + layer1_output + layer2_output + ... + layerₗ₋₁_output
Every layer's output added with 𝐞𝐪𝐮𝐚𝐥 𝐰𝐞𝐢𝐠𝐡𝐭. No layer can say "I need more of layer 3, less of layer 12."
As networks get deep, this causes 𝐝𝐢𝐥𝐮𝐭𝐢𝐨𝐧 - early signals get buried under a growing sum. And there's 𝐧𝐨 𝐬𝐞𝐥𝐞𝐜𝐭𝐢𝐯𝐢𝐭𝐲 - every layer receives the same accumulated blob.
Sound familiar? Same problem RNNs had over sequence length. Everything compressed into one state, no way to selectively retrieve.
We know how that got solved: 𝘢𝘵𝘵𝘦𝘯𝘵𝘪𝘰𝘯.
The Kimi team just did exactly that - but across 𝐝𝐞𝐩𝐭𝐡.
𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬 replaces the fixed sum with a learned weighted sum. Each layer gets a small query vector that attends over all previous layer outputs: what do I actually need from earlier?
For scale, 𝐁𝐥𝐨𝐜𝐤 𝐀𝐭𝐭𝐧𝐑𝐞𝐬 groups layers into ~8 blocks and attends over block summaries. Inference overhead: under 2%.
Results on Kimi Linear (48B params, 1.4T tokens): → GPQA-Diamond: 36.9 → 44.4 → Math: 53.5 → 57.1 → HumanEval: 59.1 → 62.2
𝘞𝘦 𝘭𝘦𝘵 𝘭𝘢𝘺𝘦𝘳𝘴 𝘢𝘵𝘵𝘦𝘯𝘥 𝘢𝘤𝘳𝘰𝘴𝘴 𝘵𝘰𝘬𝘦𝘯𝘴. 𝘞𝘩𝘺 𝘯𝘰𝘵 𝘢𝘤𝘳𝘰𝘴𝘴 𝘥𝘦𝘱𝘵𝘩?
Fresh off the press - paper dropped 3 days ago.
📄 Link in comments.
𝘍𝘰𝘭𝘭𝘰𝘸 𝘈𝘐 𝘔𝘢𝘴𝘵𝘦𝘳𝘤𝘭𝘢𝘴𝘴 for breakdowns of research that actually matters.
English
@ashok_sirs72796 Perhaps. But I am back home in India since 2015.
English

@Arjunjain Your GREAT step was not leaving the lap of YAHOO but of India !
English
𝗧𝗵𝗲 𝗱𝗮𝘆 𝗜 𝗰𝗵𝗼𝘀𝗲 𝗰𝘂𝗿𝗶𝗼𝘀𝗶𝘁𝘆 𝗼𝘃𝗲𝗿 𝗰𝗼𝗺𝗳𝗼𝗿𝘁
August 2007. Yahoo! Bangalore. I'm staring at my resignation draft. ₹1 lakh per month. Stock options. The golden handcuffs every middle-class kid dreams of.
But I'm suffocating.
Another content push. Another database migration. Another week moving avatars from server A to server B. My engineering degree screaming in protest.
My mouse hovers over 'Send'.
On the other side of this email: A €1,400/month internship at @miccunifi in #Florence. No job security. No visa certainty. Just curiosity about computer vision and exploring the world beyond Bangalore.
I hit send.
My manager pulls me aside: "𝘈𝘳𝘦 𝘺𝘰𝘶 𝘴𝘵𝘶𝘱𝘪𝘥? You're leaving Yahoo! for... Italy? Do you know how many people would kill for your job?"
He wasn't wrong.
Six months later, I'm broke in Florence. Can't get a job - wrong passport. The internship ends. I extend it because... what else? Go back to content pushes?
Apply to Columbia for PhD. They say no - bachelor's from RV College isn't enough.Masters? US/Europe fees impossible. Even "free" German programs need money for rent, food, family back home. Those doors slam shut.
𝗛𝗲𝗿𝗲'𝘀 𝘁𝗵𝗲 𝘁𝗵𝗶𝗻𝗴 𝗮𝗯𝗼𝘂𝘁 𝗰𝗵𝗼𝗼𝘀𝗶𝗻𝗴 𝗰𝘂𝗿𝗶𝗼𝘀𝗶𝘁𝘆:
It's not Instagram-pretty. It's coding until 3 AM in a tiny Italian apartment, building computer vision models while others are at aperitivo. It's visa anxiety. It's everyone thinking you've lost your mind while you're grinding harder than ever - just on something that matters.
But curiosity compounds in ways comfort never can.
That "stupid" choice led to: → Saarland Graduate School (they had a program with stipend + PhD without Masters) → Max Planck Institute → Working with Chris Bregler → Yann LeCun becoming my office neighbor at NYU → Being there when deep learning exploded → Papers, patents, Apple, teaching at IIT, IISc
From content pushes to publishing with the godfather of AI.
𝗡𝗼𝘁 𝗯𝗲𝗰𝗮𝘂𝘀𝗲 𝗜 𝘄𝗮𝘀 𝘀𝗺𝗮𝗿𝘁𝗲𝗿. 𝗕𝗲𝗰𝗮𝘂𝘀𝗲 𝗜 𝘄𝗮𝘀 𝗰𝘂𝗿𝗶𝗼𝘂𝘀.
That Yahoo resignation? Best email ever.
Not because I knew where it would lead. But because I didn't. And that was the point.
Today, @FastCodeAI and @AIMasterClass_ are my latest curiosity experiment. Building the future of AI development. Still choosing the unknown over the comfortable. Still grinding. Still curious.
Comfort whispers: "You have so much to lose." Curiosity whispers back: "You have so much to learn."
To everyone suffocating in their comfortable cages, staring at their own resignation drafts, wondering if the leap is worth it:
Your curiosity is trying to tell you something.
Maybe it's time to listen.
What comfort are you choosing over curiosity right now?
Drop it below. Let's normalize choosing growth over golden handcuffs.
P.S. - "We wish you the very best in your future endeavors." They had no idea how right they were.
#PersonalGrowth #RiskTaking #StartupLife #Engineering

English
@BellamSwathi Thank you very much. And yes, you are right. I was 22 years old, wanted to see the world and was very impatient I guess.
English

@Arjunjain With such amazing perseverance and skills even with yahoo u would still have an amazing career but would have landed up in entirely different place
English
Arjun Jain | Fast Code AI retweetledi
In pursuit of greatness? 🚀
To build world-class AI, you need the right fuel. Step into the AI Masterclass and learn the deep learning skills to reach the top.
Join our 8-week online course.
𝙖𝙞𝙢𝙖𝙨𝙩𝙚𝙧𝙘𝙡𝙖𝙨𝙨.𝙞𝙣
#𝘼𝙄 #𝘿𝙚𝙚𝙥𝙇𝙚𝙖𝙧𝙣𝙞𝙣𝙜 #𝘼𝙄𝙈𝙖𝙨𝙩𝙚𝙧𝙘𝙡𝙖𝙨𝙨
English

If you’ve been posting consistently, publishing papers, shipping projects - and the results feel painfully random…
You’re not doing it wrong. You’re living inside a power law.
𝘺 = 𝘊𝘹⁻ᵅ
→ 1% of papers collect 90% of citations
→ 1% of artists take 90% of Spotify revenue
→ 5 companies out of 4,000 in YC drive most of $600B in returns
That quiet Tuesday when 12 people read your post?
That’s not failure. That’s the 99% doing 𝗲𝘅𝗮𝗰𝘁𝗹𝘆 what the math says it will.
What changes once you internalize this:
Every attempt is a lottery ticket 🎟️
You can’t predict which one hits.
So you need volume - but you stop treating every ticket equally.
80% of output → ship fast, stay visible
20% → pour 𝗿𝗲𝗮𝗹 energy into big swings
And when something finally lands - 𝗱𝗼𝗻’𝘁 𝗺𝗼𝘃𝗲 𝗼𝗻.
That’s the signal. Go deeper. Double down.
9 flops out of 10 isn’t a verdict on your talent.
It’s the distribution working as designed.
The only real mistake is quitting before your outlier arrives. 🦄
English
@LORWEN108 Not just splash, I meant a full-on dunk. It works on the mammalian dive reflex and activates the parasympathetic nervous system.

English

@Arjunjain I agree splashing cold water on your face works instantly. Thanks for your advice!
English
Anxiety isn’t just in your head.
It’s stored in your nervous system.
Here are 8 body-based ways to release it (without medication) 🧵
1. Walk barefoot on natural ground for a few minutes.


English
Arjun Jain | Fast Code AI retweetledi

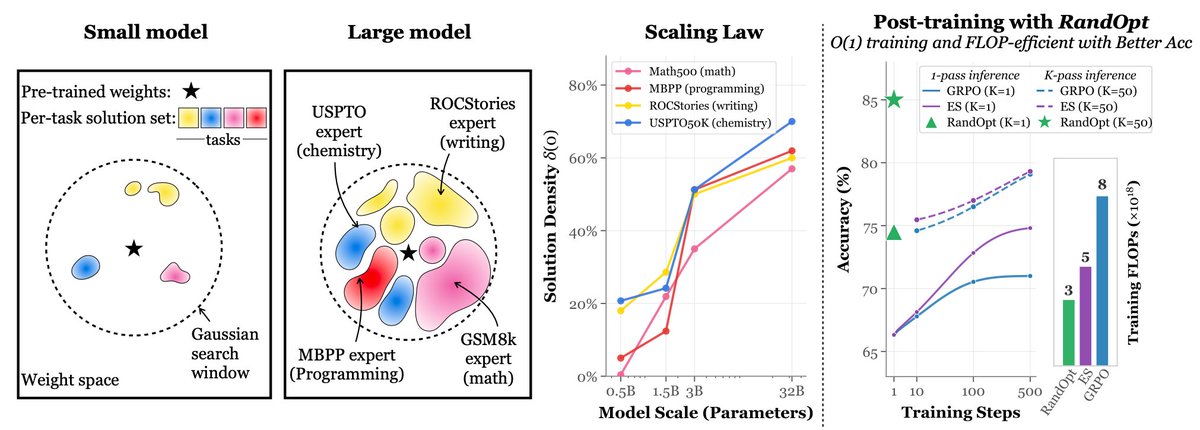
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: arxiv.org/pdf/2603.12228
Code: github.com/sunrainyg/Rand…
Website: thickets.mit.edu
English