The best part of working at OpenAI is that our mission is literal. We want everyone to have access to superintelligence. No hiding our best model for only powerful companies. You get the power.
We are the universe desperately, beautifully, trying to see its own face. And every tool we pick up to do it, is made of the very thing we're trying to look at.
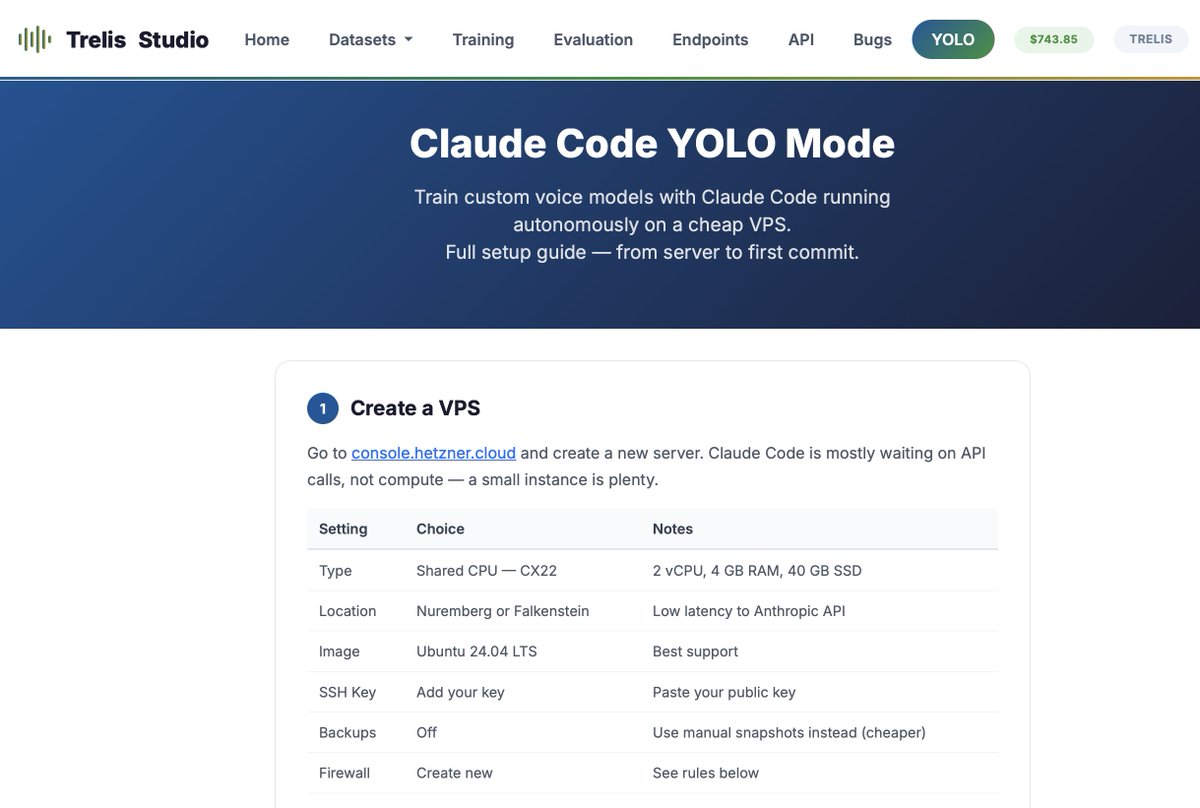
How to Claude Code Yolo
---
1. Rent a ~$4/month server from Hertzner
2. Install Tailscale on the VPS and on your Mac (you'll need to expose a UDP port on the VPS for Hertzner) [optional, or just ssh into the VPS]
3. Log in via ssh through tail scale, and set up a non-root user (Anthropic blocks --dangerously-skip-permissions on root)
4. Install a safety hook to avoid dangerous commands - npx claude-code-templates@latest --hook=security/dangerous-command-blocker --yes
5. Github setup: Create a fine-grained PAT with read/write on contents and pull requests for specific repos only! Then protect your main branch with a required PR rule. This way Claude can push to any feature branch freely, but can't land directly on main.
Then - to do data prep and train or evaluate voice models - asr or tts...
6. Set your HF token on studio . trelis . com and get a spend-limited API key to put into environment variables on the VPS.
Claude Code can then call the Studio API to trigger training runs, pull datasets, and run evals — all autonomously.
7. Optionally, add a Trelis Router (router . trelis . com) api key to your Trelis Studio account so you can evaluate proprietary models.
Finally - in the server - you can run:
alias yolo='claude --dangerously-skip-permissions'
then
tmux new -s yolo
yolo
and you'll start off a claude session where it will run without permissions
just close the terminal to leave it run, or press Ctrl+b and then d to detach from tmux. 'tmux attach -t yolo' to reconnect later.
---
for more, check "studio . trelis . com/yolo"
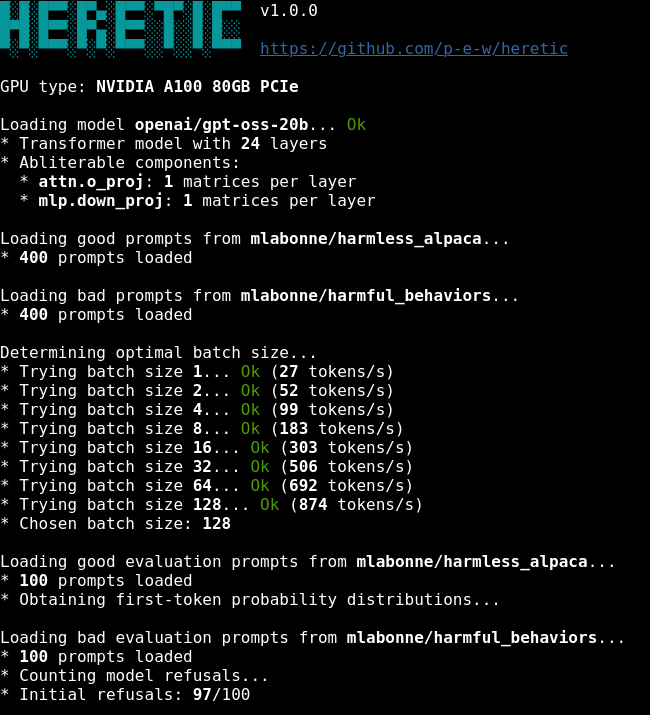
Someone open-sourced a tool that REMOVES LLM CENSORSHIP in 45 minutes 🤯
It’s called Heretic. Instead of fighting with complex prompts to bypass safety filters, you run one single command and it permanently deletes the model's ability to refuse a prompt.
• Fully automatic (Zero config required)
• Preserves the model's raw intelligence
• Works on Llama, Qwen, Gemma, and dozens of others
• Runs locally on consumer hardware
100% Open Source.
@burkov To be fair, qwen 2.5 0.5b was a really good model even compared to some 1b models, but yeah, qwen3 and 3.5 small models were mostly benchmaxxed
I don't trust Qwen models, even the large ones. I trust small ones even less.
Qwen has been benchmaxing its models since the very beginning, so the benchmark performance of a 4B parameter model beating Gemini 2.5 Flash Lite is most likely just the benchmark performance only.
4B is just not enough to store any general intelligence because most of the parameters will still be used to store facts. Well, not facts, but something that remains of them.
As opposed to symbolic models (and humans!) language models might split these sequences incorrectly, and even in the best cases the still hallucinate due to language poisoning (statistical knowledge instead of structured knowledge):
●●
●● ●●
●● ●● ●●
Language models usually get to an erroneous conclusion given some statistics. Symbolic models will mostly never hallucinate because they can't! There's no ambiguous solutions, the only way to lower their losses is by literally learning the rules!