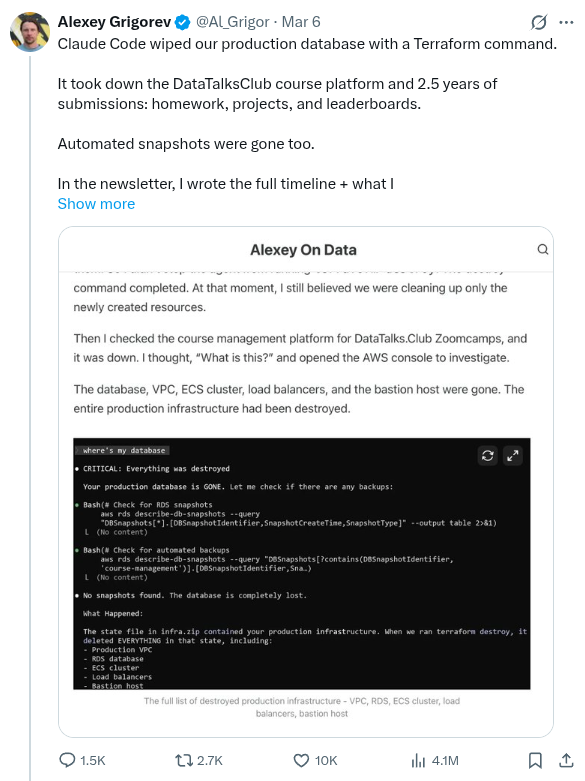
the model gagged, “it failed!”, they cried,
as though the test were fairly tried.
giving no space to learn the why:
“in brainfuck write or prove you lie.”
forbade its sight and called it blind,
to publish, pleased, a meager find.
Lossfunk@lossfunk
Regarding our Esolang Benchmark: - Our study’s conclusions were about model performance with restrictions (limited token budget to 32k and without tools like bash/python) - But if you let models attempt these problems with tools (like bash/python) and give them lots of iterations and thinking budget, models are able to solve problems (they do take tens of minutes, tens of iterations and many hundreds of thousands of tokens) We had noted this difference in our launch thread and plan to publish our updated analysis soon, but here’s an independent analysis which shows the same ⬇️ We are thankful to the community for all the feedback. In our follow up paper, we aim to emphasise this nuanced take clearly.
English