Sabitlenmiş Tweet
Lossfunk
661 posts


Lossfunk
@lossfunk
Foundational questions on artificial and biological intelligences
🇮🇳 Katılım Ocak 2025
1 Takip Edilen16.8K Takipçiler

@rao2z @fchollet @drmichaellevin @MiTiBennett @eschwitz @jzl86 @Meaningness @MelMitchell1 @Plinz 11/ The broader claim: AI metaphysics is not useless.
But it becomes useful when it helps inspire empirical progress: new experiments, benchmarks, interventions, or better predictions.
Full paper: lossfunk.com/papers/ai-meta…
English
10/ Pinging researchers who inspired this paper.
@Meaningness - your essays on misuse of metaphysics kickstarted this.
@MelMitchell1 - we were hugely inspired by nuances you tease out in “Why AI Is Harder Than We Think”
@Plinz - we love how you operationalize AI consciousness as a specific testable hypothesis. Curious what you think about our paper.
English
🚨 Paper release
Accepted at ICML 2026 main conference!
AI is full of metaphysically loaded questions:
• Can AIs be conscious?
• Do LLMs understand?
• Do models have goals?
• What is AGI?
Our position: don’t judge such concepts by whether they capture the "true essence" of something.
Judge them by what they help us do.

English

Hi @paraschopra request your team to kindly upload
Some of deep tech talks by @lossfunk after the session on YouTube like recent one on automating research through agents ! May help young students and startups
English


20th May, 6:30 PM
In person + Gmeet
Pre-read on Luma
In-person: luma.com/9h6oahoo
Gmeet: meet.google.com/ace-jthv-apo
English
We are hosting Dr Nithin Nagaraj (NIAS, Bengaluru) for a talk at our office, "Chaos Everywhere Part 2!"
His previous talk made everyone curious about how chaotic systems work and why they are so common in nature
This time, he's covering how chaotic systems can outperform standard ML approaches on the viral genome classification task.
English
👀
alphaXiv@askalphaxiv
Why LLMs Aren't Scientists Yet? In our latest AI4Science talk, Prof. Dhruv Kumar (@gargdhruv36) and Dhruv Trehan (@dhruvtrehan9) from @lossfunk discussed how agentic LLM systems can support science in a whole new way, from generating research ideas to mentoring young researchers and help reviewing papers. However, there are still significant drawbacks when relying on these systems because things ranging from forgetting context, overhype results, and lacking in research taste are really common. A really fascinating talk if you’re curious about how AI scientists, where they still fail, and why better scientific harnesses may matter as much as better models.
ART
.@ItSiddharthaa, Research Fellow at Lossfunk, discusses curating the Verifiable Track problems for CAISc 2026!
👇
Siddhartha Mahajan@ItSiddharthaa
🧵Putting together the Verifiable Problems Track for CAISc 2026, organised by @lossfunk and @bitspilaniindia ! While choosing problems for the track, we used one main rule: hard to do, but easy to verify. This led to 3 filters: Deterministic verification, no LLM judges. Genuinely open/frontier, not a textbook exercise. Accessible to a smart amateur with an agent. Here are the 5 we chose!👇
English
We updated the Esolang-Bench paper on Arxiv.
Changes:
- Added Python/JavaScript baselines (to show comparison with mainstream languages)
- Removed agentic evaluation section (it'll be a separate paper)
- Language edits to calibrate our claims (with evidence)
Thanks to anonymous reviewers and community here for feedback and discussion.
Updated paper: arxiv.org/abs/2603.09678
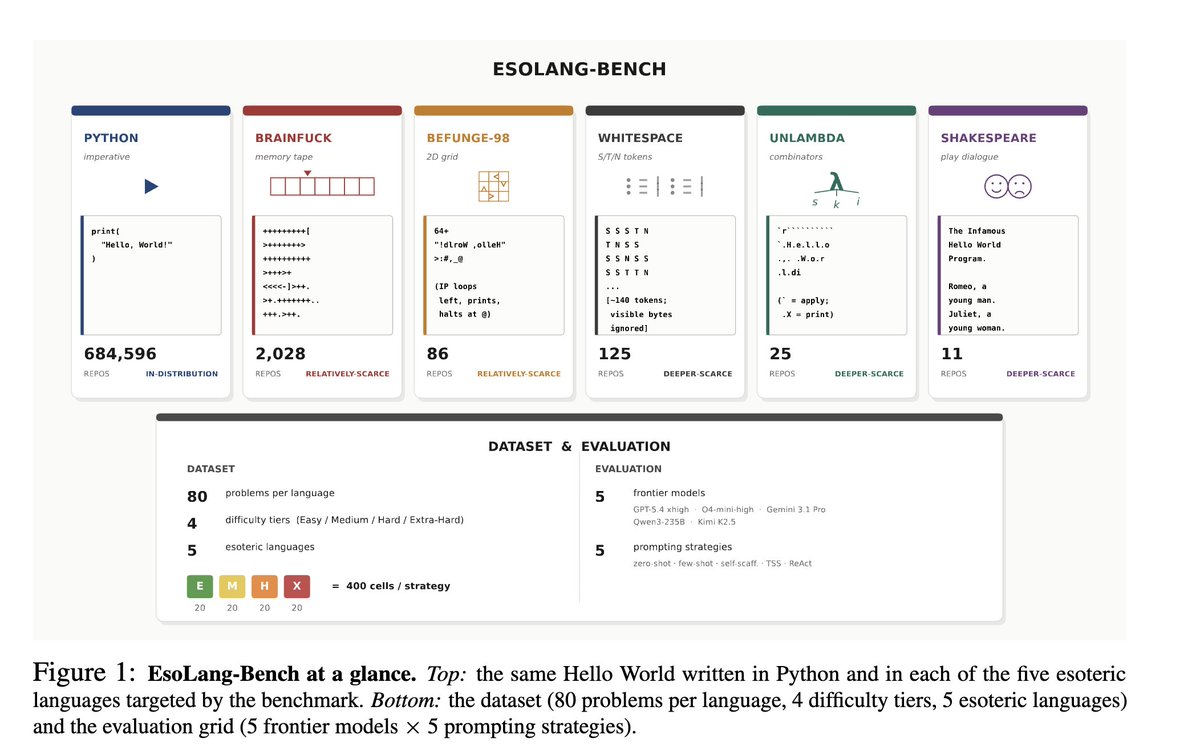
English
Register for the pre-conference sessions here:
→ Automating Research with Agents and Skills: luma.com/sf371it7
→ Using Karpathy's AutoResearch for Science: luma.com/1esirby6
→ End-to-End Automated Research with Claude Code: luma.com/nm0ar7ef
English
🚨 We're extending CAISc 2026 submissions to May 30 and announcing 3 pre-conference workshops!
The sessions will cover 3 ways LLMs are automating science: agent skills for domain-specific tasks, autoresearch loops, and agentic coding tools for end-to-end research projects.
They will be led by @RahulSundar6, Founder at Dhyuti Labs and PhD from @iitmadras, @MajorTimbWlf21 from Lossfunk, who has been extending @karpathy's AutoResearch for Neuro-inspired ML research, and @paraschopra, who will discuss autovoila, a repo for running research projects with CLI coding agents.
Whether you're submitting or just want to start using these tools, register on Luma 👇

English