Nice event by "Vienna AI Engineering". at T-Mobile where I had the privilege to talk about best practives for CLI creation: youtube.com/watch?v=OxlST7…

YouTube
English
petersson.eth
590 posts
@yellowhatcoder
Goals: Power to individuals. Improve my surroundings. Means: Blockchain. Bitcoin. Strong typing. Community.

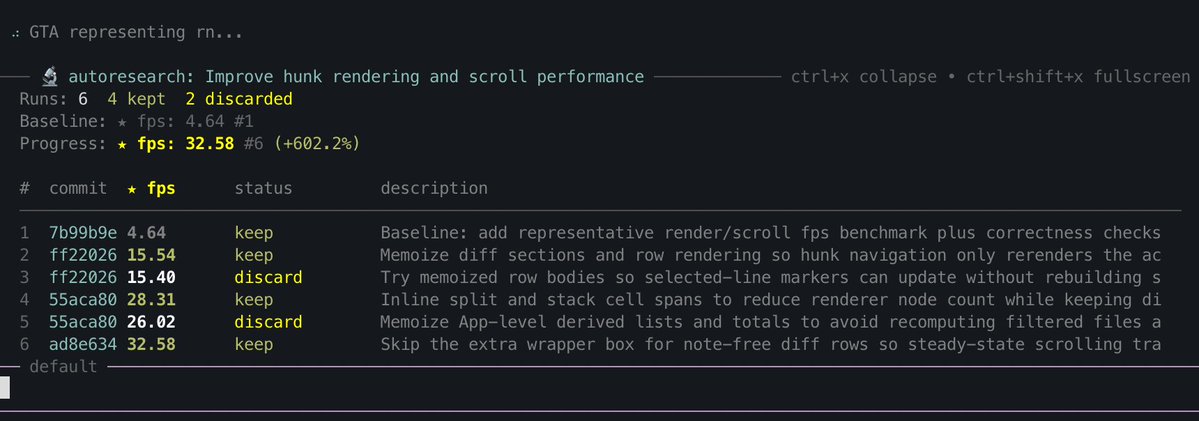


im fully convinced that LLMs are not an actual net productivity boost (today) they remove the barrier to get started, but they create increasingly complex software which does not appear to be maintainable so far, in my situations, they appear to slow down long term velocity


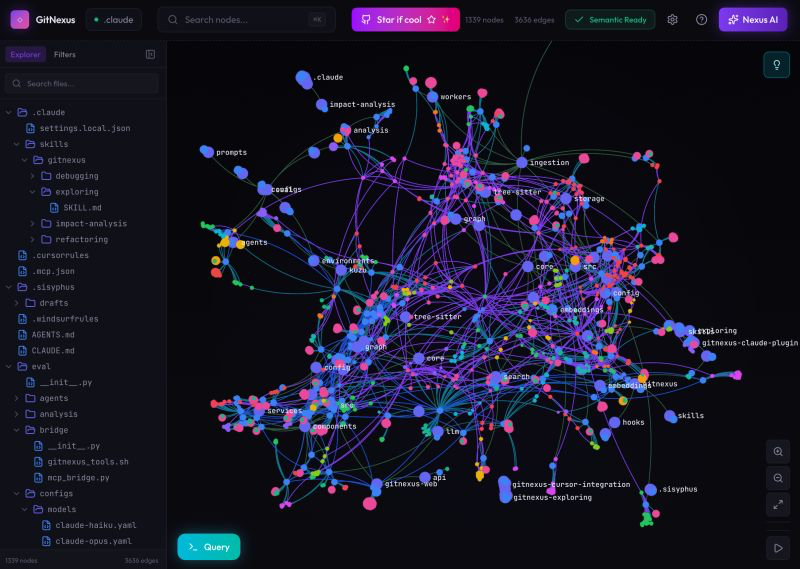
2/ Cheddr Payment Channels x402 by @yellowhatcoder Making 100 requests a minute shouldn’t mean sending 100 transactions. This uses payment channels for x402 to enable efficient recurring and streaming micropayments. x.com/yellowhatcoder… github.com/CPC-Developmen…