
@TheAhmadOsman @huggingface 2x RTX6000s is not the normal “running at home on your own hardware” experience… I’m just sayin’ :)
English
Axly
430 posts
@AxlysCustoms
Fantasy, Modern & Sci‑Fi AI Art | SFW + NSFW | Custom Bundles, Wallpapers & Commissions - https://t.co/uNrpROP4QL

@TheAhmadOsman He should try Hermes Agent


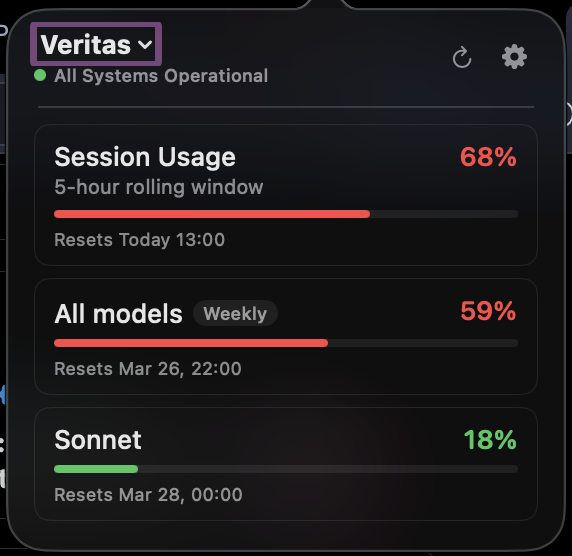
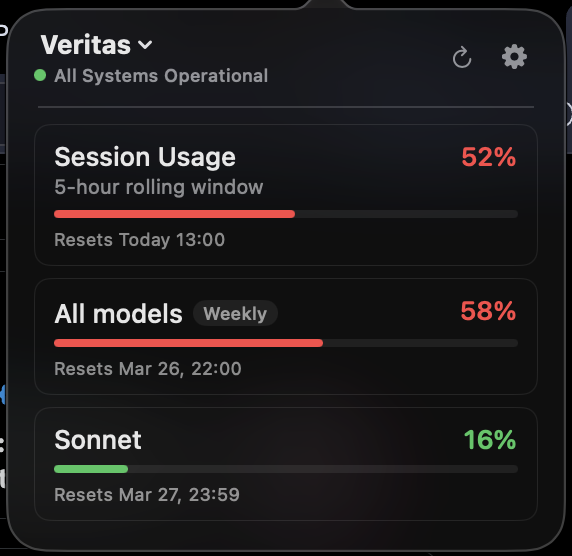
Something is up with Claude Code usage today. $200 Claude Max, 0%, 52% to 62%, then 68%, 76% and 84% in 5-hour rolling window in the time it took me to write this tweet. WTF, @AnthropicAI? I'm working on one GitHub PR for regression testing. Not folding proteins to cure cancer.

I hit my limits very quick this week - even with 20x pro plan. It makes my claude code unusable A good reason to do more stuff with Codex!





You can now train Qwen3.5 with RL in our free notebook! You just need 8GB VRAM to RL Qwen3.5-2B locally! Qwen3.5 will learn to solve math problems autonomously via vision GRPO. RL Guide: unsloth.ai/docs/get-start… GitHub: github.com/unslothai/unsl… Qwen3-4B: colab.research.google.com/github/unsloth…






Anthropic just pulled the oldest trick in SaaS pricing. I pay $200/mo for Claude Max. My limits have been noticeably worse this past week. Now they announce 2x off-peak usage for two weeks. Sounds generous. But here’s what actually happens: limits quietly drop, a temporary 2x makes the reduced limit feel normal, the promo ends, and you’re left at a baseline lower than where you started. You just didn’t notice the downgrade because the 2x absorbed the transition. These AI plans are massively subsidized. The raw compute behind a heavy user costs multiples of the subscription price. Every move like this is the subsidy quietly correcting. Very sneaky, Anthropic.








