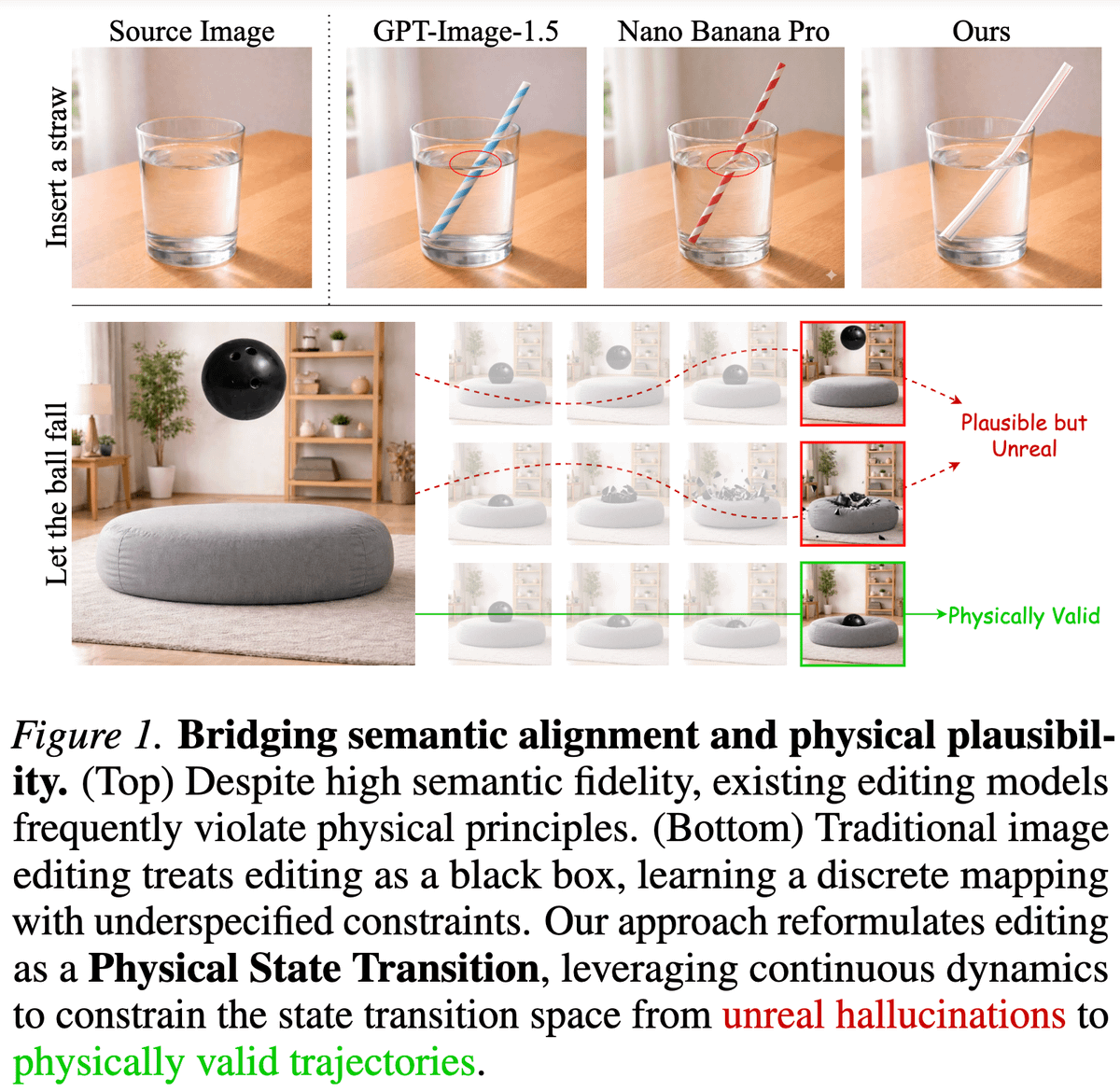
@RisingSayak @ben_nebulous Surprisingly Nano Banana 2 is doing quite well but love the work done to have physically correct. Ground work for world models!

English
Florian Soudan
74 posts

@FSoudan
AI team lead, I manage cross functional teams delivering industrial AI solutions.


Introducing Bolmo, a new family of byte-level language models built by "byteifying" our open Olmo 3—and to our knowledge, the first fully open byte-level LM to match or surpass SOTA subword models across a wide range of tasks. 🧵






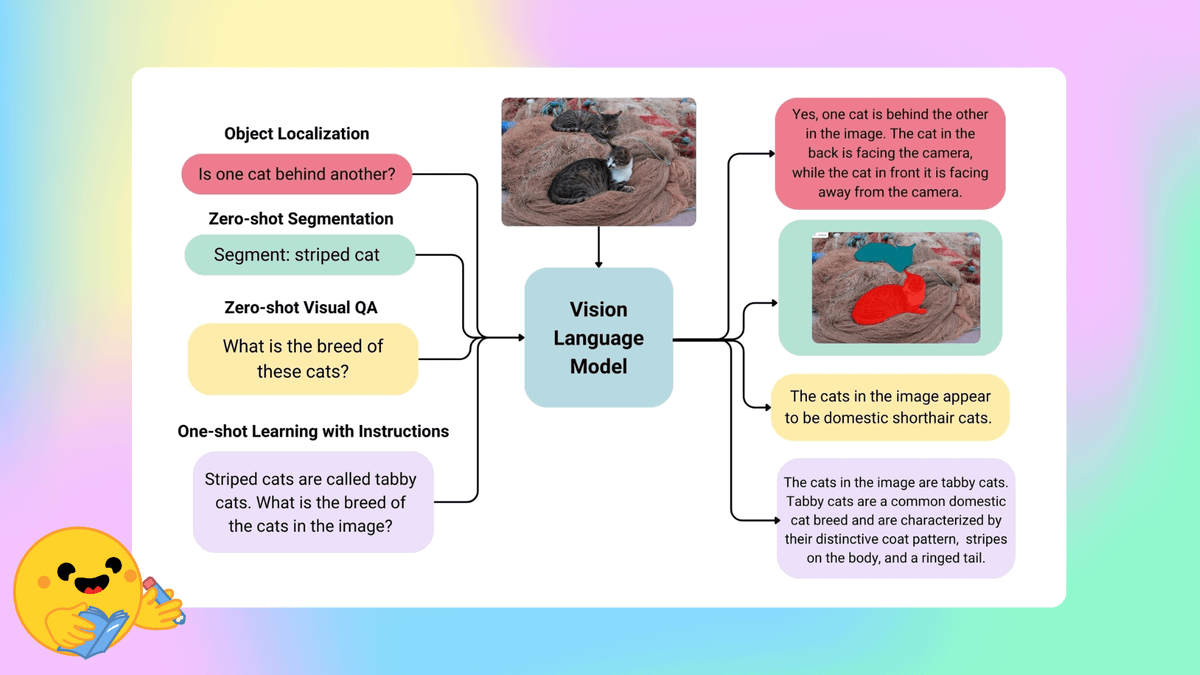
Collection of Llama-3 based VLMs: huggingface.co/collections/xt… Collection of Phi-3 based VLMs: huggingface.co/collections/xt…