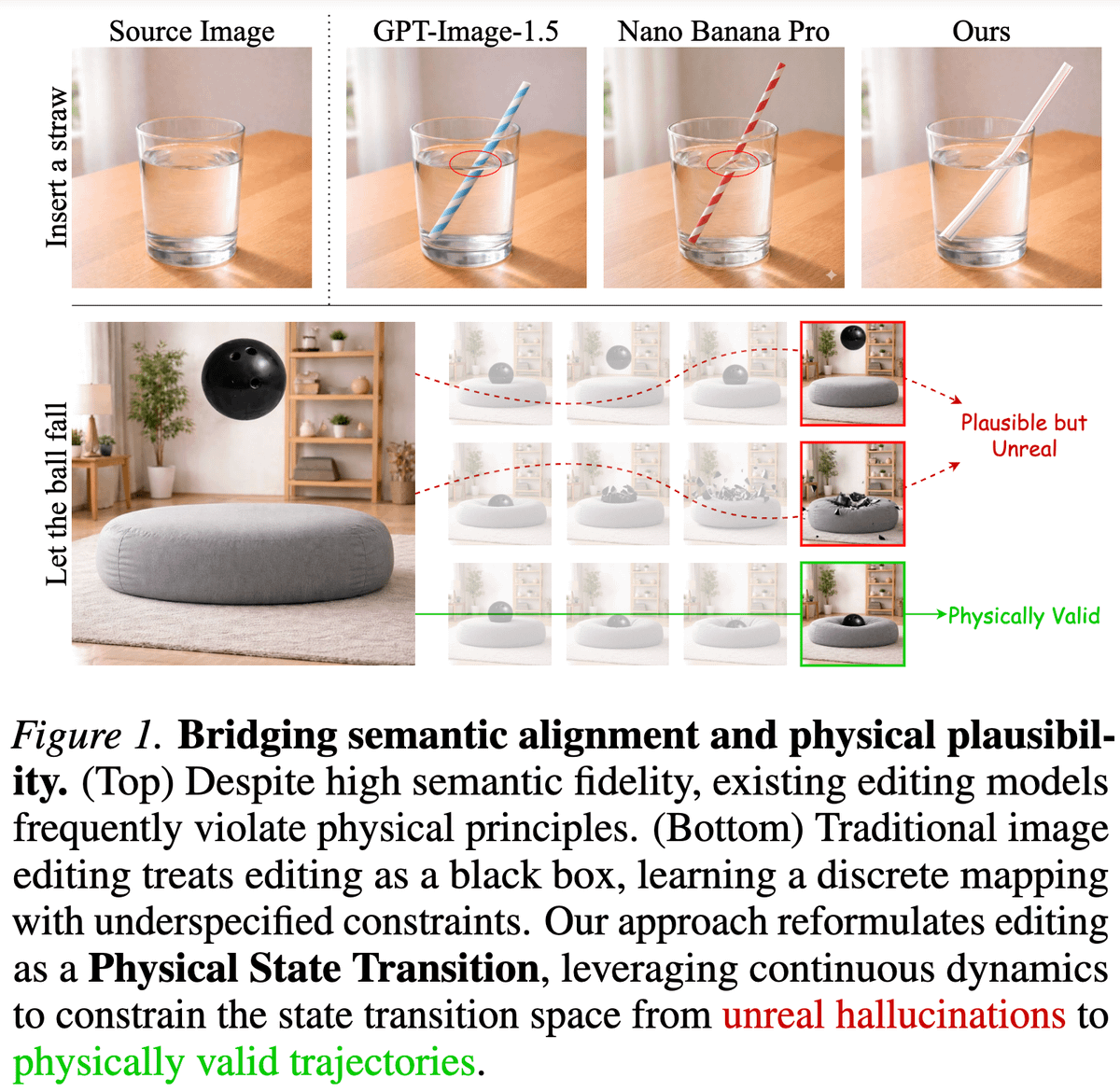
Editing images is a series of state transitions between the source image and the edited image that we want. Yet, the existing paradigm doesn't explicitly include any transitioning priors in the editing process. This becomes particularly prevalent for edits, involving causal dynamics (e.g., refraction, deformation). To model this kind of physics-informed information, we leverage the rich priors present in videos and introduce PhysicEdit 🔥 TL;DR: We fine-tune QwenImage Edit on a curated dataset of videos with reasoning traces and fixed-length transition queries to do solid physics-aware image editing! In the process, we introduce a cool dataset "PhysicTran38K", consisting of 38K transition trajectories across five physical domains and devise a method to provide supervision from it QwenImage Edit. Hop in to learn more ⬇️