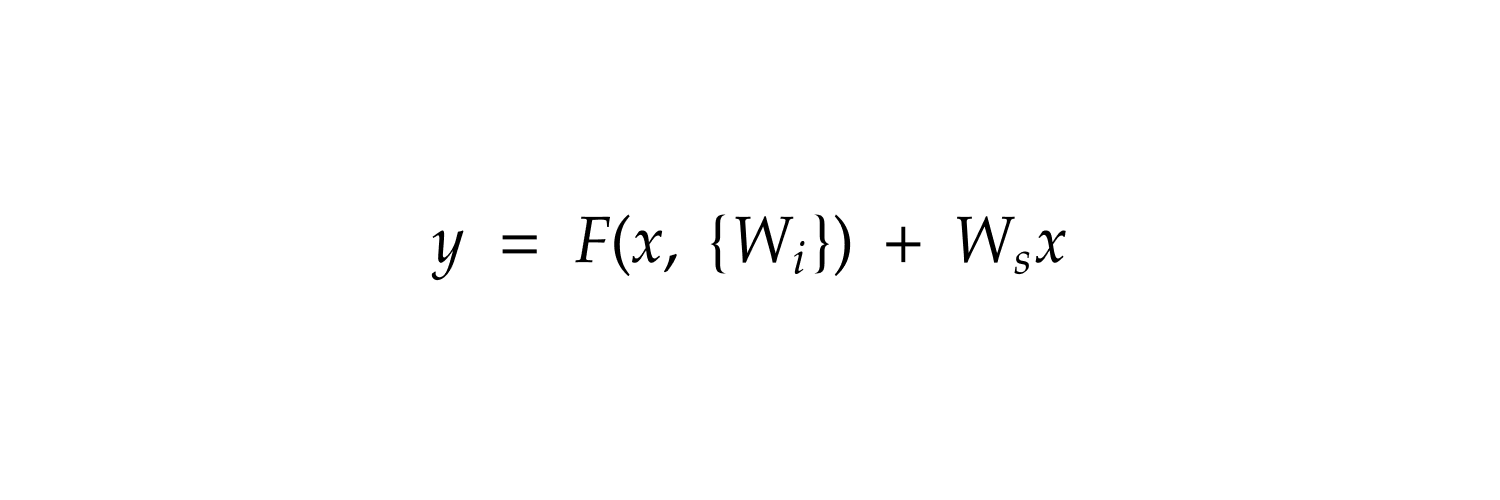Arthur Zucker@art_zucker
This is going to be a little bit long, but I want to give hope to my fellow anxious ML engineers.
We see a lot of propaganda on how this or that AI one shotted something, about how incredibly strong the models are getting and how we don't even need to review PRs and we can just ship to production.
Although this can be true for some cases, its also far from being representative of all the challenges we have to face.
I started using claude code 4 month ago, and quickly realized how it really does change the way we work. I can experiment 10x faster, fix small issues without coding and refactor code without sweating.
BUT, these tasks were "just" tedious and not hard. The challenge in my day to day work is to take a research code and integrate it into transformers using our standards. Its challenging because code beauty is abstract and subjective just like a philosophy.
By relying too much on claude, and on how seemingly good the code it produces look, I pushed the deepseekv4 integration without realizing that claude really did not understand the model.
I gave it access to `transformers`, the original paper, the original code, the different blog posts and my past chats and skills created to add a model, a b200 node node and a LOT of tokens, but it did NOT nail it. It did not understand the eager attention path, it did not understand the basics of causal attention. It was even wrong implementing the manifold constrained hyper connections.
It helped to reduce the burden of exploring implementation and debugging but it did not help reason around the model.
I am not a doomer, I think our job as Software Engineers has never been this great, I am just saying that we still have a job, and we should still be a bit careful when it looks to good to be true 😉