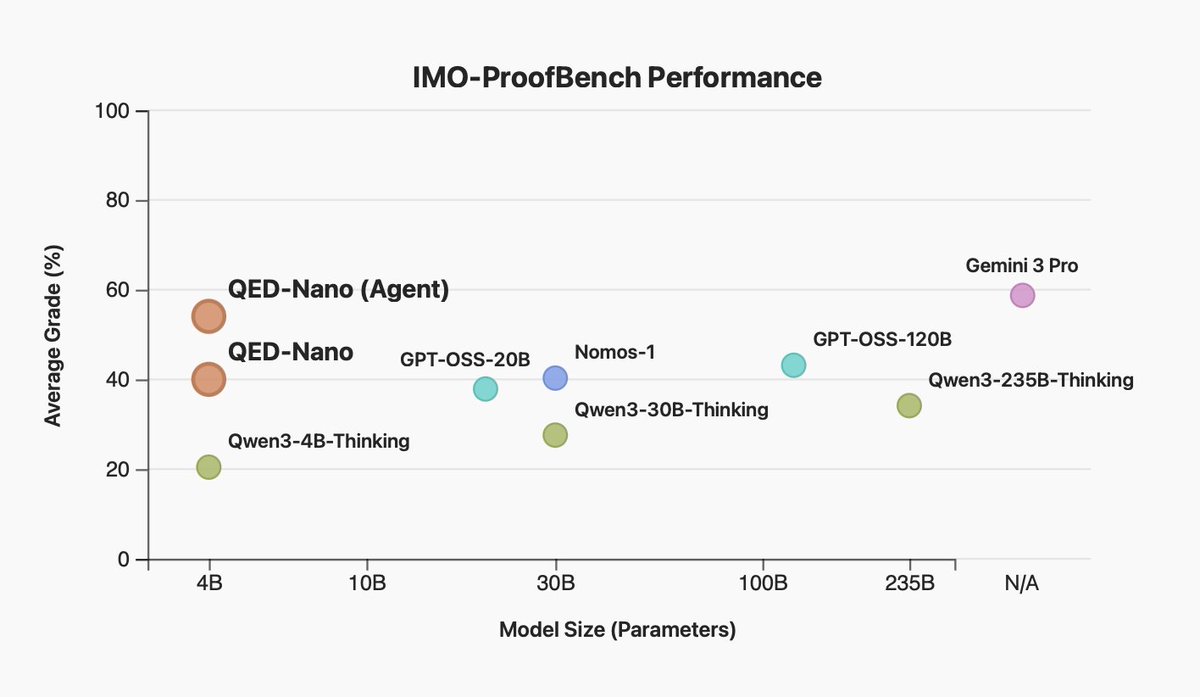
고정된 트윗

Almost nobody does proper credit assignment in RL-on-LLMs 💀
Learning only from the final outcome
→ punishes good steps 😭
→ rewards bad steps 😭😭
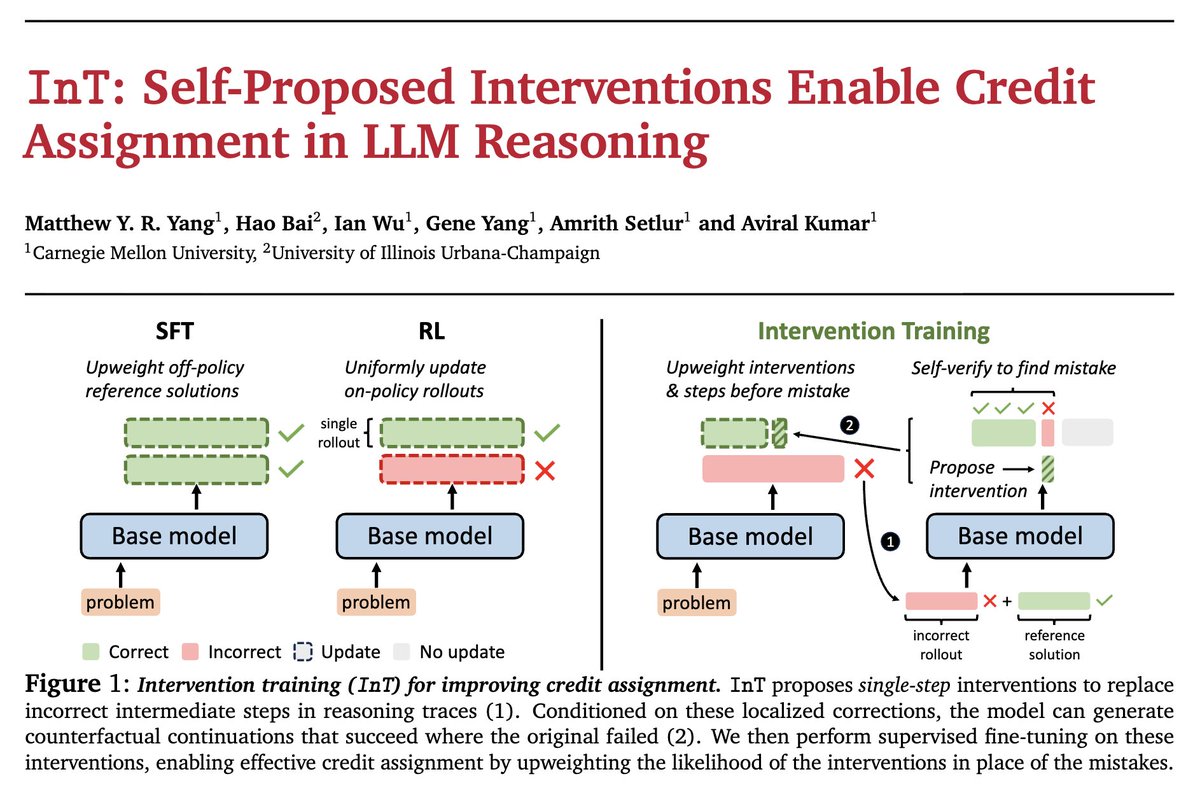
🚨New Paper🚨
A new paradigm for credit assignment:
LLMs identify their own mistakes ❌ and propose targeted fixes 🎯
🧵[1/n]
English