Sabitlenmiş Tweet

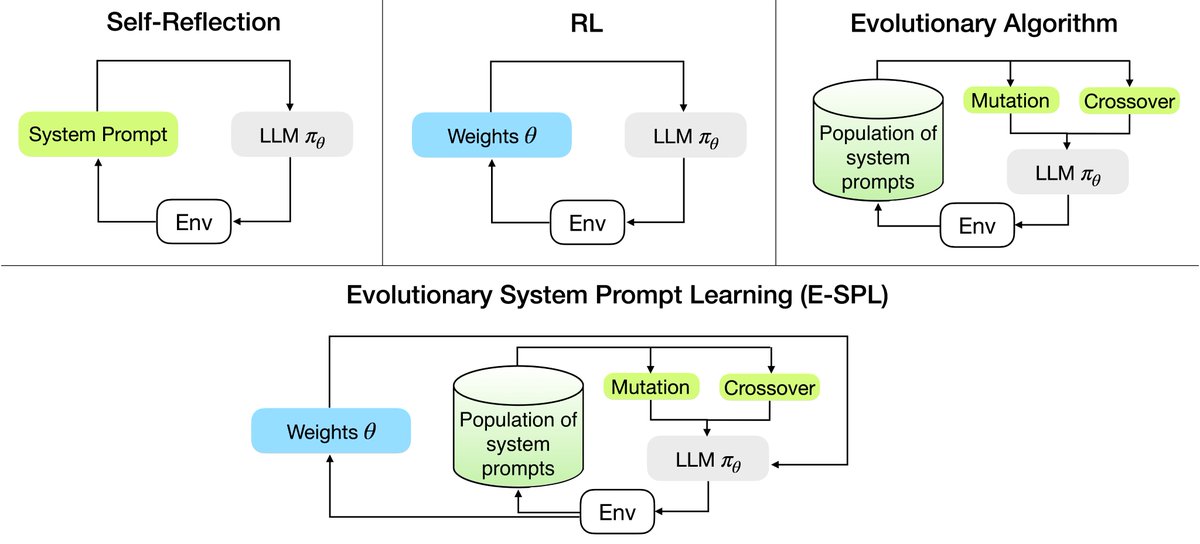
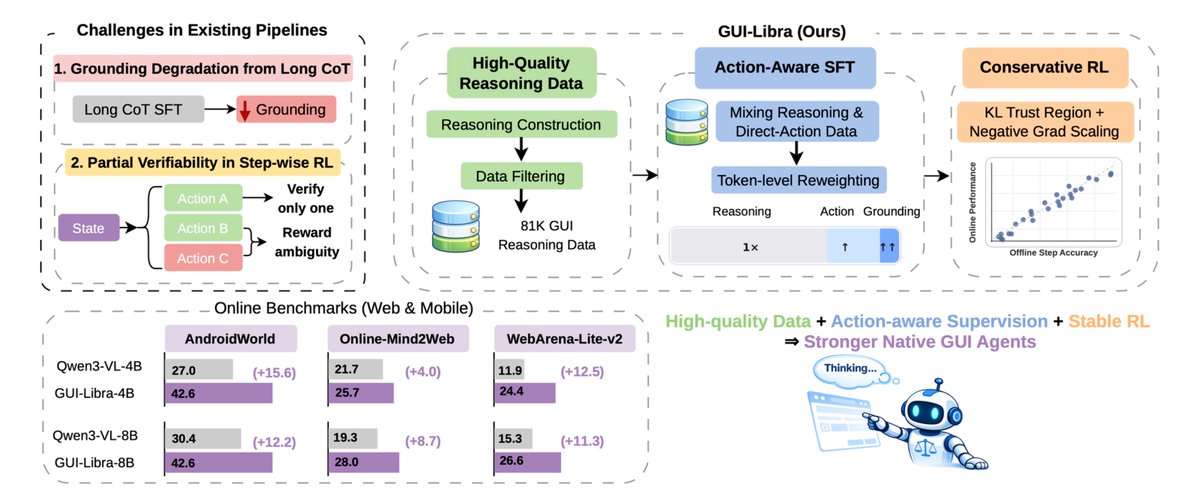
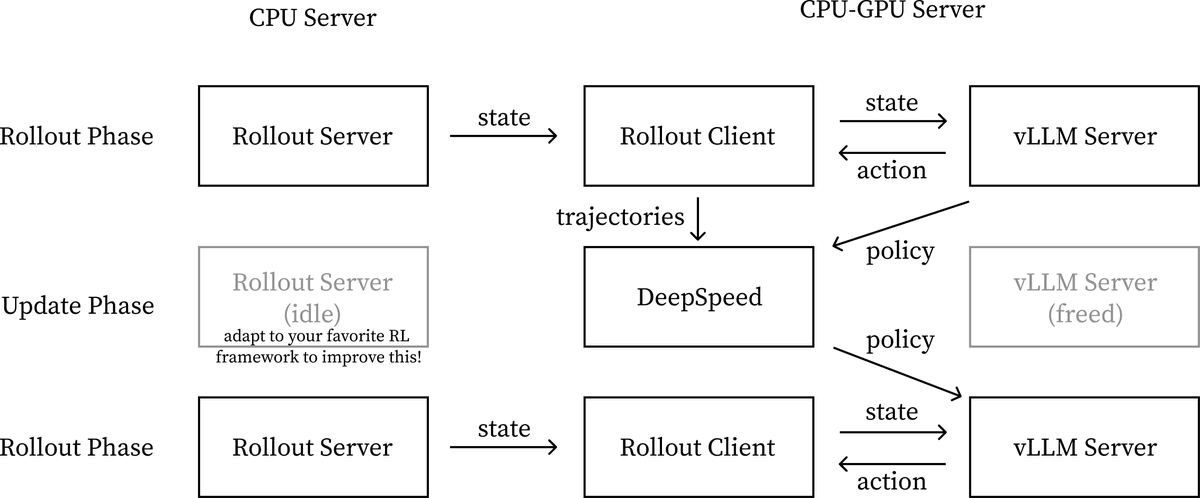
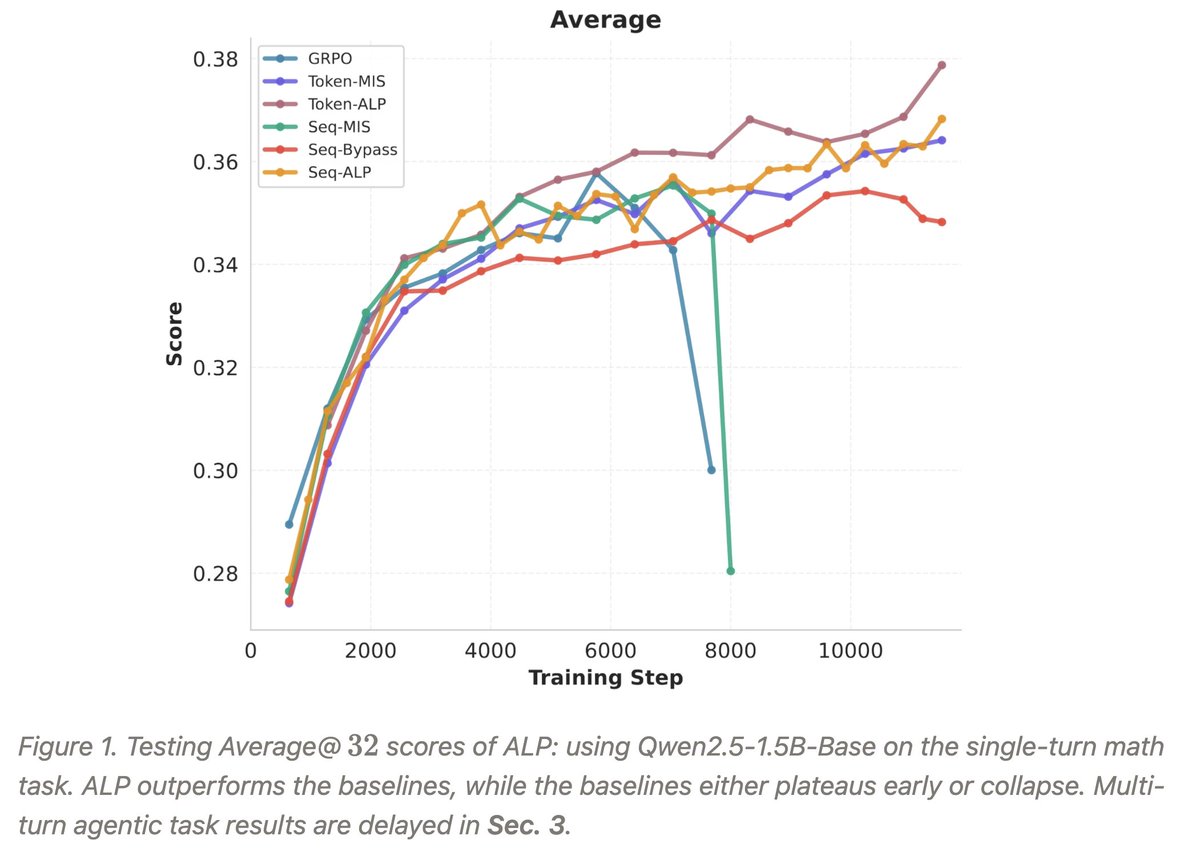
😈 Today, we introduce WebGym, the largest-to-date open-source RL environment for web agent training that contains 300k tasks and a rollout framework optimized specifically for web environments' rollout speed. We reveal the effects of essential scaling directions we observe with WebGym.
1/n
English