Sabitlenmiş Tweet
Ian Wu
54 posts


@eliebakouch We studied something similar here: arxiv.org/pdf/2602.03773
Even the 4B Qwen model is good enough to self-summarize with just prompting. So yeah doesn’t surprise me that you can just do RL directly on a bigger/better models like Composer
English

i like this kind of trick that is intuitive and works well, i'm wondering if they started with a sft/cold start on traces with self summary or directly learned in RL? if 2) i'd be curious to see how long it takes for the model to learn this by themselves
Sasha Rush@srush_nlp
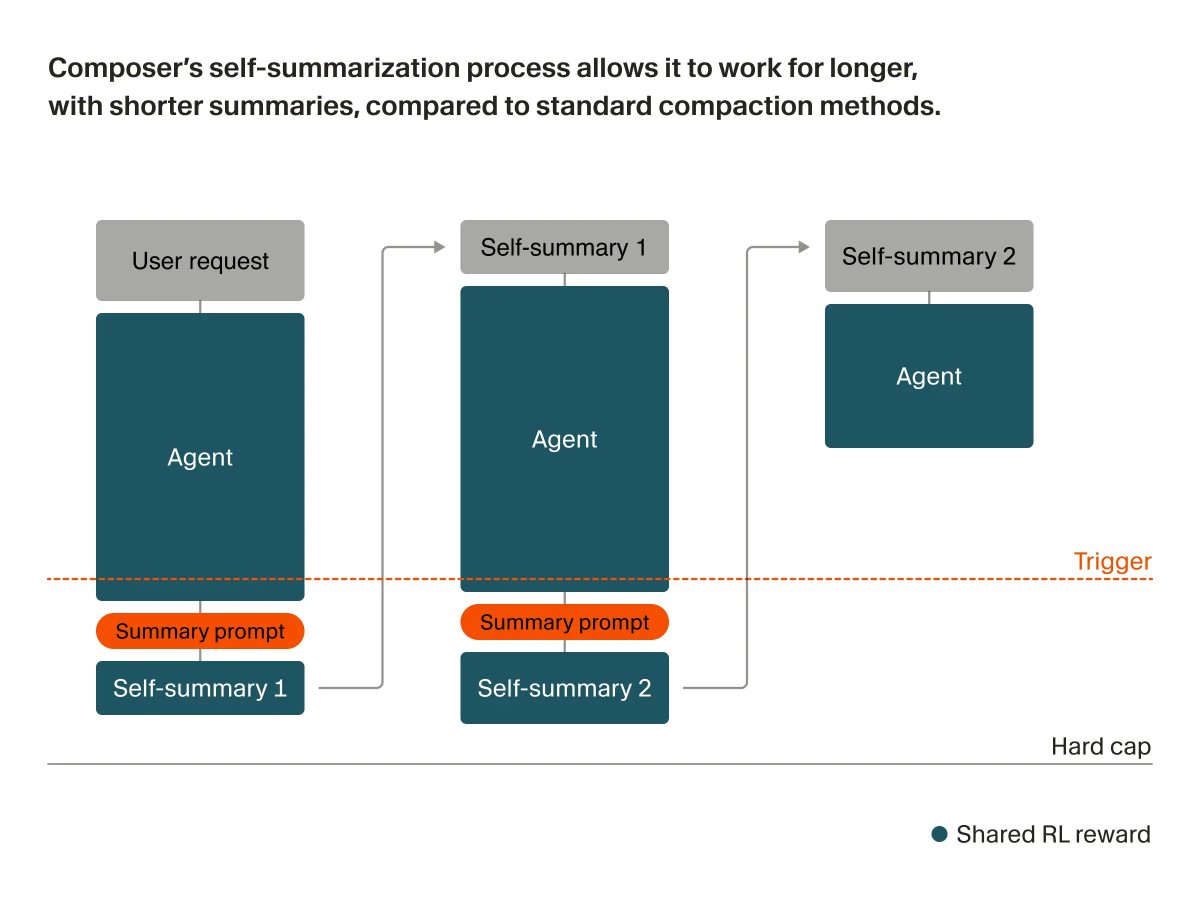
New blog on how we train Composer to work on hard problems. With the maestro himself Federico Cassano @ellev3n11
English

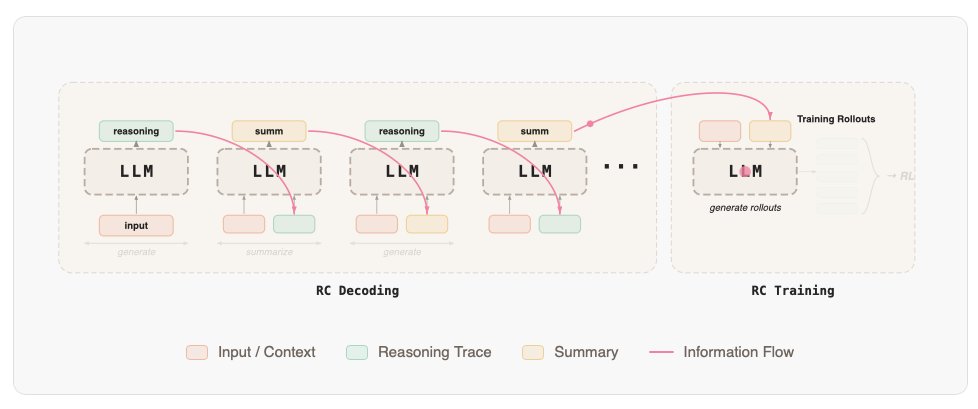
Neat, reminds me of the reasoning cache by @ianwu97 that we used to train QED-Nano huggingface.co/spaces/lm-prov…
Cursor@cursor_ai
We trained Composer to self-summarize through RL instead of a prompt. This reduces the error from compaction by 50% and allows Composer to succeed on challenging coding tasks requiring hundreds of actions.
English
Ian Wu retweetledi

😈 Today, Microsoft open-sources WebGym: the task set, code, a bunch of visualization tools, and guiding documentations. WebGym is an RL environment with the *first* open-source implementation of the fully asynchronous rollout system designed for multi-step vision-supported web agentic trajectory collection, which speeds up *4x-5x* compared to existing synchronous implementations. This release comes with *300k* realistic web agentic tasks with comprehensive evaluation rubrics and pipeline, together with annotations on difficulty and domains.
🧵 1/6
English
@jburnmurdoch Horrifying. This problem also predates 08/09, which from what I can tell is when Britain began lagging behind its peers.
Curious to hear your explanation for this.
English

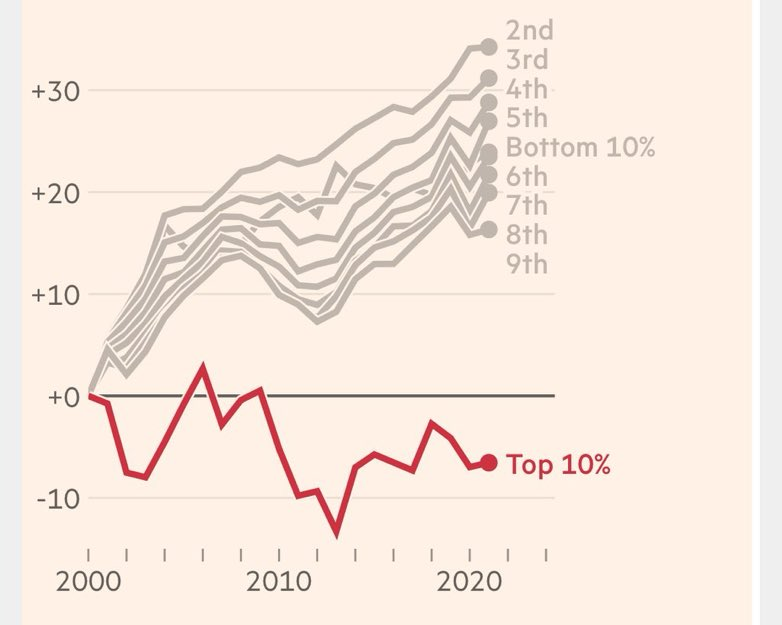
I’ve shown another lens on this same thing previously: the UK’s top income decile has had a very rough couple of decades (and the top half as a whole has done much worse than the bottom half).
Who works in top-paying jobs? Graduates. That’s the erosion of the premium right there
English
The real sign British education has failed is the number of people responding to this chart with "that’s what happens when too many people go to university"
HE has expanded in all of these countries, and in every one apart from UK that didn’t erode the graduate earnings premium.
Stefan Schubert@StefanFSchubert
Whereas the graduate premium has increased in most rich countries, it has plummeted in Britain since 1997. Earnings for British graduates have shrunk (next pic). ->
English
@barrowjoseph A lot of untapped potential with these smaller models.
I guess most teams with the resources + motivation + expertise stick with training bigger models since they are more likely to get eye-catching results that way.
English

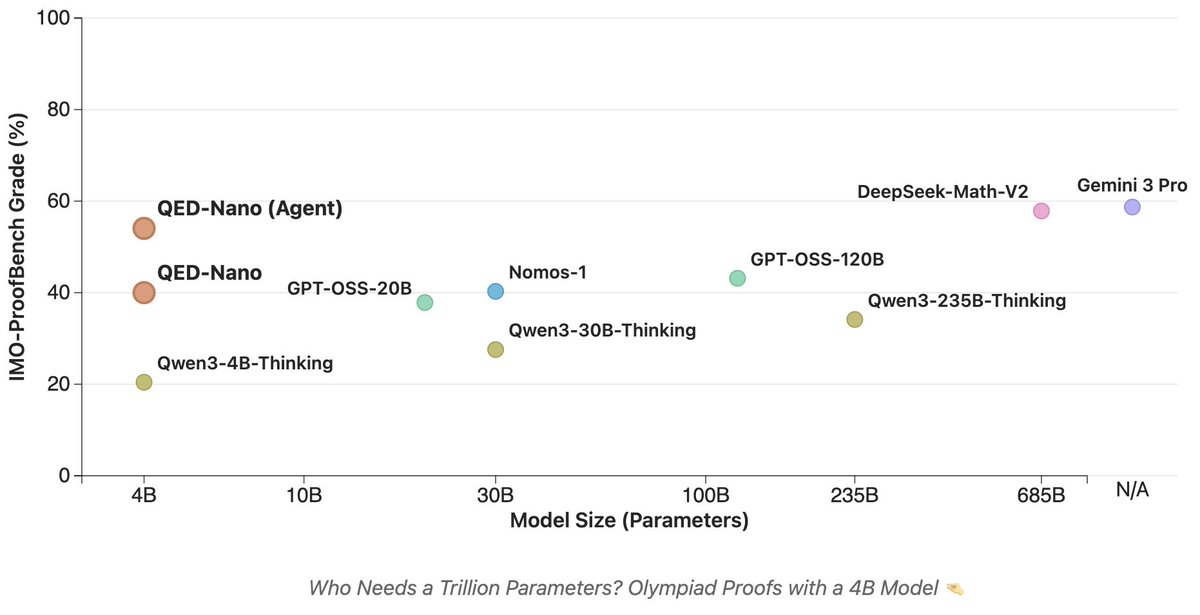
QED-Nano is crazy to me. The idea that you can post-train a 4B parameter model to do well at *real, challenging* tasks violates my prior assumptions.
My coworkers may be tired of me sharing it already.
Ian Wu@ianwu97
We post-trained a 4B parameter model to write Olympiad-level math proofs! Our tiny model, *QED-Nano*, outperforms gpt-oss-120b, and approaches the performance of Gemini 3 Pro when paired with test-time scaffolding. Check out the blogpost: huggingface.co/spaces/lm-prov…
English
A huge thank you to my amazing collaborators from CMU @aviral_kumar2 @QuYuxiao @setlur_amrith, Hugging Face @edwardbeeching @_lewtun, ETH Zurich @j_dekoninck and Project Numina @JiaLi52524397.
English
6/ Our code, datasets, models etc. are all publicly available!
github.com/CMU-AIRe/QED-N…
huggingface.co/lm-provers/QED…
English
We post-trained a 4B parameter model to write Olympiad-level math proofs!
Our tiny model, *QED-Nano*, outperforms gpt-oss-120b, and approaches the performance of Gemini 3 Pro when paired with test-time scaffolding.
Check out the blogpost: huggingface.co/spaces/lm-prov…
English
@siddarthv66 @_lewtun Yep! We discuss this for verifiable rewards in the original RC paper as well btw.
RC trained model + RSA at test time to scale parallel compute -> big gains.
RC trained model + RC decoding + RSA at test time -> even bigger gains.
arxiv.org/pdf/2602.03773
English

RSA is the best performing scaffold for inference time compute! Allows a 4B model to match Gemini 3 Pro on IMO-ProofBench
Lewis Tunstall@_lewtun
The final piece of the puzzle is to pair our model with an agentic scaffold that can effectively scale inference-time compute to very long horizons. We experimented with many scaffolds and DeepSeek's to provide the best tradeoff in compute vs performance. However, if you're willing to go the full mile and generate >2M tokens per proof, Recursive Self-Aggregation is the best scaffold and allows our 4B model to match Gemini 3 Pro on IMO-ProofBench!
English
12/Check out the paper here: arxiv.org/pdf/2602.03773
A huge thank you to my fantastic collaborators @aviral_kumar2 @QuYuxiao @setlur_amrith, and a great start to my PhD!
English
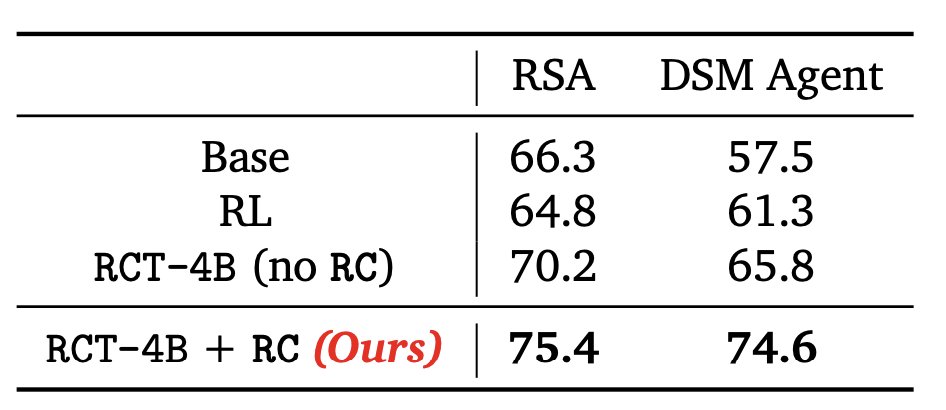
11/Does RC training teach a generalizable skill for using guidance?
To test this, we use RCT-4B within two existing time-time scaffolds that utilize other forms of guidance (aggregation, verification feedback etc.). RCT-4B achieves large gains, even without specific adaptations.
English