@MariusHobbhahn Do you think this is due to leakage or something like eval anxiety?
English
95
153 posts


We evaluated Meta's Muse Spark prior to deployment and found it to verbalize evaluation awareness at the highest rates of any model we've tested. In the verbalizations Muse Spark explicitly names AI safety orgs (e.g. Apollo & METR) in its chain-of-thought and refers to scenarios as "classic alignment honeypots". On our evaluations, the model takes covert actions and sandbags to preserve its deployment.






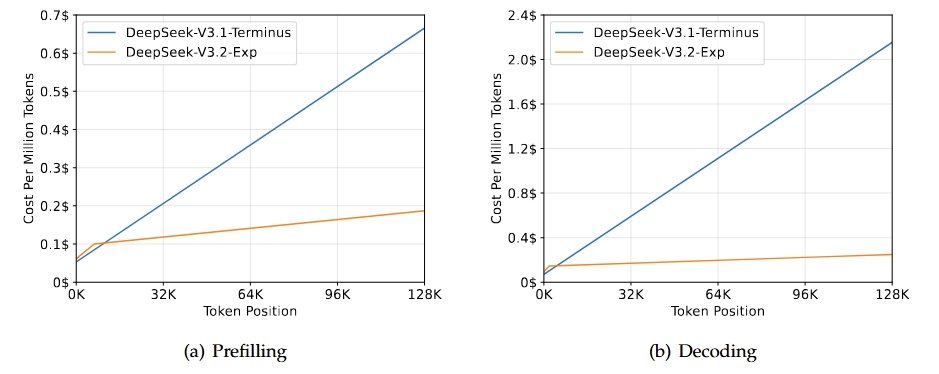
in fairness, DeepSeek-v3.2-Exp (Think) had one success too. So it's not a big leap. No pre-AIME model solves it. Expert has failed AIME-2026's #15, in almost 2000 seconds. I still believe these are the same model. Too similar, both in verbal patterns and in capabilities.


@SOPHONTSIMP @tenobrus yeah there is literally no specific criteria that the pause is predicated on, and no specific criteria for lifting it. we would basically be waiting for the generation that believed in a pause to get old and die.




Chess is just intellectual masturbation. Like sure it’s fun, but at the end of the day you didn’t get anything done.