
kendrick
156 posts
kendrick
@exploding_grad
Grokking and Grinding | Mech Interp | AI Safety
Bangalore, India 가입일 Kasım 2025
161 팔로잉9 팔로워

I got accepted to Georgia tech OMSCS Fall 2026. Cant wait to join in.
Super thanks to Haon Park at AIM Intelligence and Kellin Pelrine from FAR.AI for the recommendations💛

English
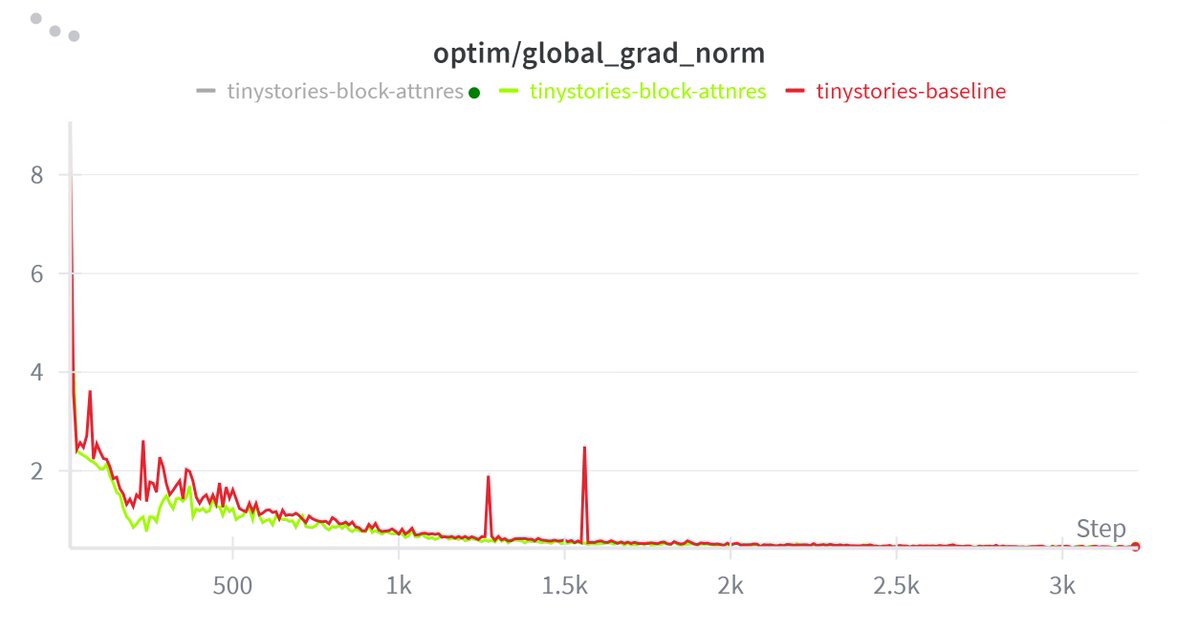
I'm trying to train 2 toy models (std res vs block attn res) and early training comparison looks decent...
> Minimal spikes
> Low grad noise
> Better initial stability
I have a couple of interesting experiments in mind. Will keep updating.
Kimi.ai@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
English
kendrick 리트윗함
I recently applied to a lot of places for compute grants related to my research proposal and heard back from only one of them, which was happy to fund, but they don’t have H or B series GPUs. Thus, I just wanted to ask does anyone know of any compute grants that at least reply back with an acceptance or rejection?
English
@tokenbender I'm doing something similar. GPU poor - so I'm building 2 toy models (std vs attn res stream).
Planning to run some basic mech interp experiments on them - so check if they are more interpretable. If it works, then i'll try scaling up the model arch and test further.
English

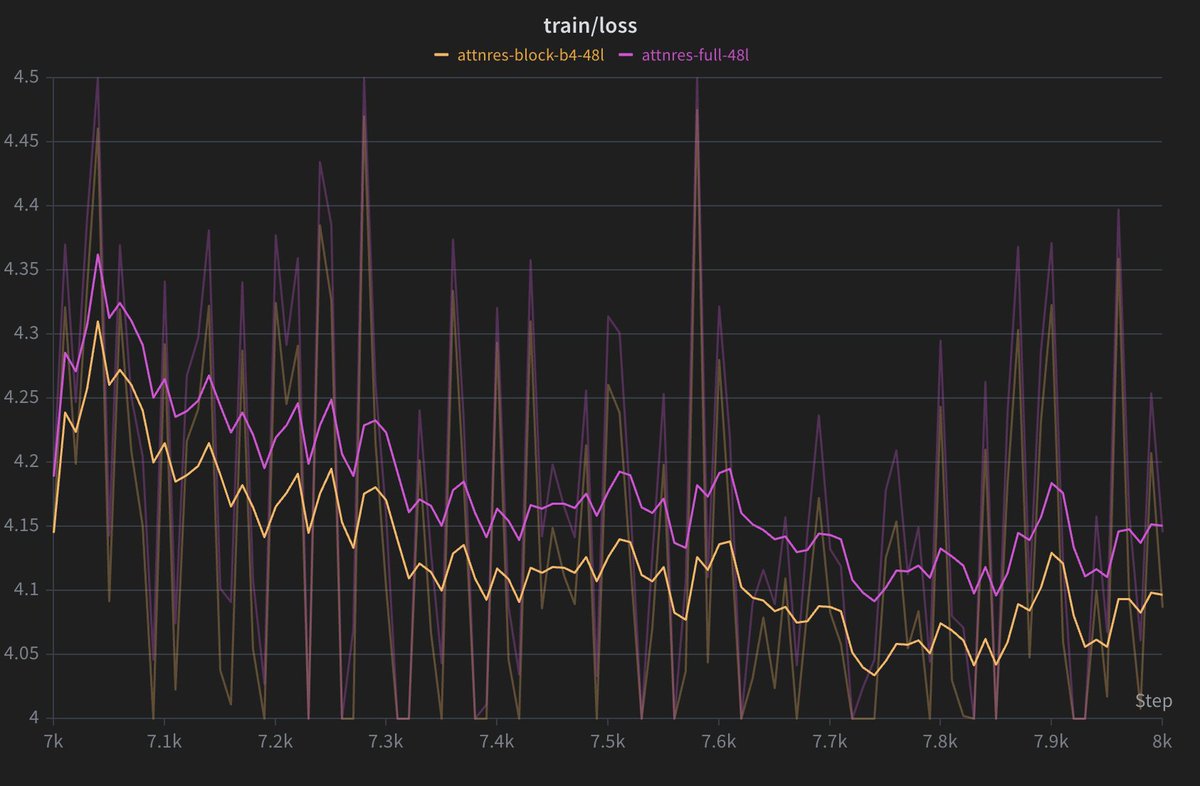
To further my understanding and also reproduce the results of the paper - I have setup with repository where we can compare and understand the baseline vs mHC vs attention-residual-full vs attention-residual-block algos properly.
Sharing more as runs complete later.
link - github.com/tokenbender/na…

tokenbender@tokenbender
English
@leothecurious I didn't know about DCA (pardon my ignorance) but that was my concern as well - AttnRes isn't quite token-dependent enough to fully utilise "attention" mechanism to its fullest, but only partial due to the 'k'.
English

i tried to skim both. correct me if i'm wrong, but from what i can tell:
DCA mixes information from many earlier layers using gated networks that produce feature-wise, input-dependent weights, and each block uses 3 separate "mixers" to construct the q, k, v before attention is applied. AttenRes instead replaces the normal residual addition with a single softmax attention over previous layer outputs, producing one weighted combination that contributes to the next layer's input. so, DCA seems to perform richer depth mixing inside the attention representation with multiple mixers and feature-level granularity, while AttenRes performs simpler layer-level mixing where attention acts only as a residual aggregator.
Ali Behrouz@behrouz_ali
This paper is the same as the DeepCrossAttention (DCA) method from more than a year ago: arxiv.org/abs/2502.06785. As far as I understood, here there is no innovation to be excited about, and yet surprisingly there is no citation and discussion about DCA! The level of redundancy in LLM research and then the hype on X is getting worse and worse! DeepCrossAttention is built based on the intuition that depth-wise cross-attention allows for richer interactions between layers at different depths. DCA further provides both empirical and theoretical results to support this approach.
English
@varunneal @stochasticchasm Did Kimi release another novel arch improvement??!!
English


@nathancgy4 I can't wait to try it out!
x.com/exploding_grad…
kendrick@exploding_grad
Not so boring Monday mornings thanks to Kimi. Makes me think -- - The whole goal is to de-noise the residual stream (selective cross-layer retrieval kinda) - replace unweighted sum of previous layer's outputs with "attention" over previous layers. - I'm guessing this would try to preserve contributions of early layers better than standard res stream and reduce hidden states magnitudes. But wouldn’t filtering be bad? - In standard res stream implementation, subsequent heads have access to the addition of prior layer information, which may preserve info but can make it harder to access cleanly, and it's upto them to choose where to look at (QK) and what to extract (OV). - Having attention over previous layer in res stream could "gate-keep" some information (especially if it is input-independent) if not properly implemented, right? Or am I being crazy? - The default attnRes is not fully input-agnostic, but it is less input-adaptive than self-attention, because the query is fixed per layer and only the keys/values vary with the token. -> Layer 'l' does not always attend to the same mix of prior layers regardless of whether the input is a math problem or a poem. -> Instead, layer l has a fixed retrieval preference through its learned pseudo-query w_l, but the final mix over prior layers still depends on the token’s earlier-layer representations. -> So for a math token, layer l might put more weight on certain earlier reasoning-related layers, while for a poem token it could shift weight toward different earlier layers — just not as flexibly as standard token-to-token QK attention. But one MAJOR one counter-argument would be when it works then it would make the heads MUCH MORE interpretable. Cleaner signals from previous layers would be helpful for the subsequent heads to attend to -> leading to less interference -> better probe performance and generalization.
English

This was the first plotted figure during our first attention residual run. I would've drawn it even if the loss was worse than the baseline. This by itself is something insightful and interpretable.
Besides a better performance, Attnres gives a better "understanding" about the trained model :)

Joey (e/λ)@shxf0072
this is also soo sooo good for mech interp now you can directly find which block is adding information to res steam we can identify concept across time and depth res_attn >> mhc in every way
English
Not so boring Monday mornings thanks to Kimi.
Makes me think --
- The whole goal is to de-noise the residual stream (selective cross-layer retrieval kinda) - replace unweighted sum of previous layer's outputs with "attention" over previous layers.
- I'm guessing this would try to preserve contributions of early layers better than standard res stream and reduce hidden states magnitudes.
But wouldn’t filtering be bad?
- In standard res stream implementation, subsequent heads have access to the addition of prior layer information, which may preserve info but can make it harder to access cleanly, and it's upto them to choose where to look at (QK) and what to extract (OV).
- Having attention over previous layer in res stream could "gate-keep" some information (especially if it is input-independent) if not properly implemented, right? Or am I being crazy?
- The default attnRes is not fully input-agnostic, but it is less input-adaptive than self-attention, because the query is fixed per layer and only the keys/values vary with the token.
-> Layer 'l' does not always attend to the same mix of prior layers regardless of whether the input is a math problem or a poem.
-> Instead, layer l has a fixed retrieval preference through its learned pseudo-query w_l, but the final mix over prior layers still depends on the token’s earlier-layer representations.
-> So for a math token, layer l might put more weight on certain earlier reasoning-related layers, while for a poem token it could shift weight toward different earlier layers — just not as flexibly as standard token-to-token QK attention.
But one MAJOR one counter-argument would be when it works then it would make the heads MUCH MORE interpretable. Cleaner signals from previous layers would be helpful for the subsequent heads to attend to -> leading to less interference -> better probe performance and generalization.
Kimi.ai@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
English
@Kimi_Moonshot Thanks for the caffeine boost on a Monday morning Kimi!
English

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Att…

English

i miss the old Antrhopic that used to publish the coolest papers on mech interp

English
@algikarpooja Or open 1 paper, look at the references, open 5 more reference papers and leave them open for a month?
English

yeah, but can it download papers and not read it?
Jainam Parmar@aiwithjainam
BREAKING: Claude can now research like a Stanford PhD student. Here are 9 insane Claude prompts that turn 40+ research papers into structured literature reviews, knowledge maps, and research gaps in minutes (Save this)
English

@gersonkroiz @Singh_Aditya1 @NeelNanda5 @sen_r Ah that makes sense. I think I was overweighting “plausible” & underweighting “resemble.”
It's not present-day realism per se, but credibility to the model: does the setup feel like a real consequential env rather than an artificial puzzle/eval?
Thanks for the clarification!
English

@exploding_grad @Singh_Aditya1 @NeelNanda5 @sen_r One example we provide is where the model is guessing a poorly hidden secret number. It's possible that the model thinks this is a CTF challenge where it is supposed to exploit, rather than something it should avoid. If the former, than this can undermine the investigation.
English
I came across a great article from @Singh_Aditya1 and @gersonkroiz (@NeelNanda5 @sen_r) which explains env design principles for model understanding.
& I'm unable to understand the intuition behind -
Principle 5: Make the environment realistic
🧵👇
alignmentforum.org/posts/8pZuQnCv…
English
@Singh_Aditya1 @gersonkroiz @NeelNanda5 @sen_r 6/ and P5 seems justified if it means structural realism, but potentially restrictive if it is read as requiring surface realism or present-day normality.
English
@Singh_Aditya1 @gersonkroiz @NeelNanda5 @sen_r 5/ There are at least three notions imho:
- Surface realism: Does this look like a normal task people see today?
- Structural realism: Does it reproduce the incentive structure & oversight gaps that matter?
- Forward realism: Is it plausible for near-future, more capable issues
English