@LottoLabs @DataPlusEngine I don’t see any benefit to using lmastudio over llama.cpp directly. You just lose out on a ton of features.
English
fos
490 posts


Qwen3.6 35B-A3B dropped yesterday, so I ran it on 4 GPUs to see how it performs: 🟣 RTX 3090 — 49.78 tok/s, TTFT 852ms 🟡 RTX 4090 — 118.93 tok/s, TTFT 686ms 🟢 RTX 5090 — 160.37 tok/s, TTFT 409ms 🔵 DGX Spark — 59.98 tok/s, TTFT 228ms I went with ollama as the backend because honestly, it's the easiest way for most people to get started. One command, model pulled, done. I used Q4_K_M (24GB) across all four cards. The reason is the 3090 and 4090 don't support NVFP4 (only the 5090 and DGX Spark could use it). Keeping the same quant everywhere felt like the fairest way to compare. And yes, you can absolutely squeeze more performance out of every card with vLLM, SGLang, or TensorRT-LLM. But that's not what this test is about. This is just the out-of-the-box experience for folks who own a GPU and want to try the new model tonight.

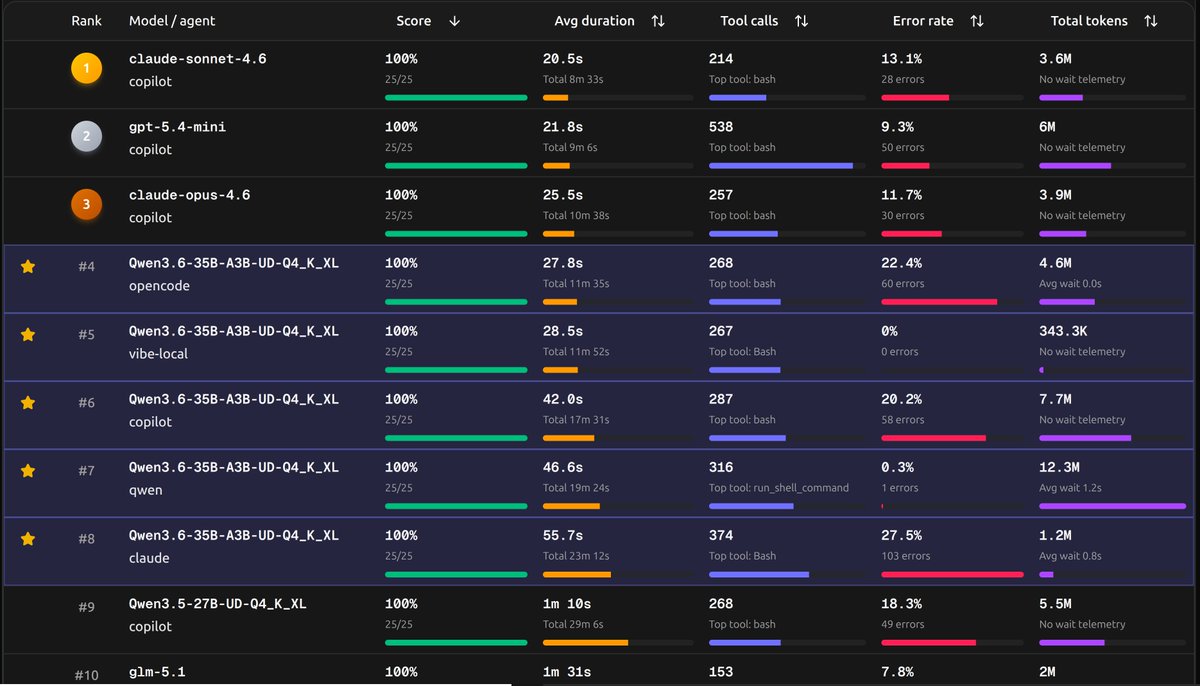
Claude Opus 4.7に隠れてあまり話題になってないけど、Qwen3.6-35B-A3Bかなりすごいモデルなのでは?

Idk what to type here rn

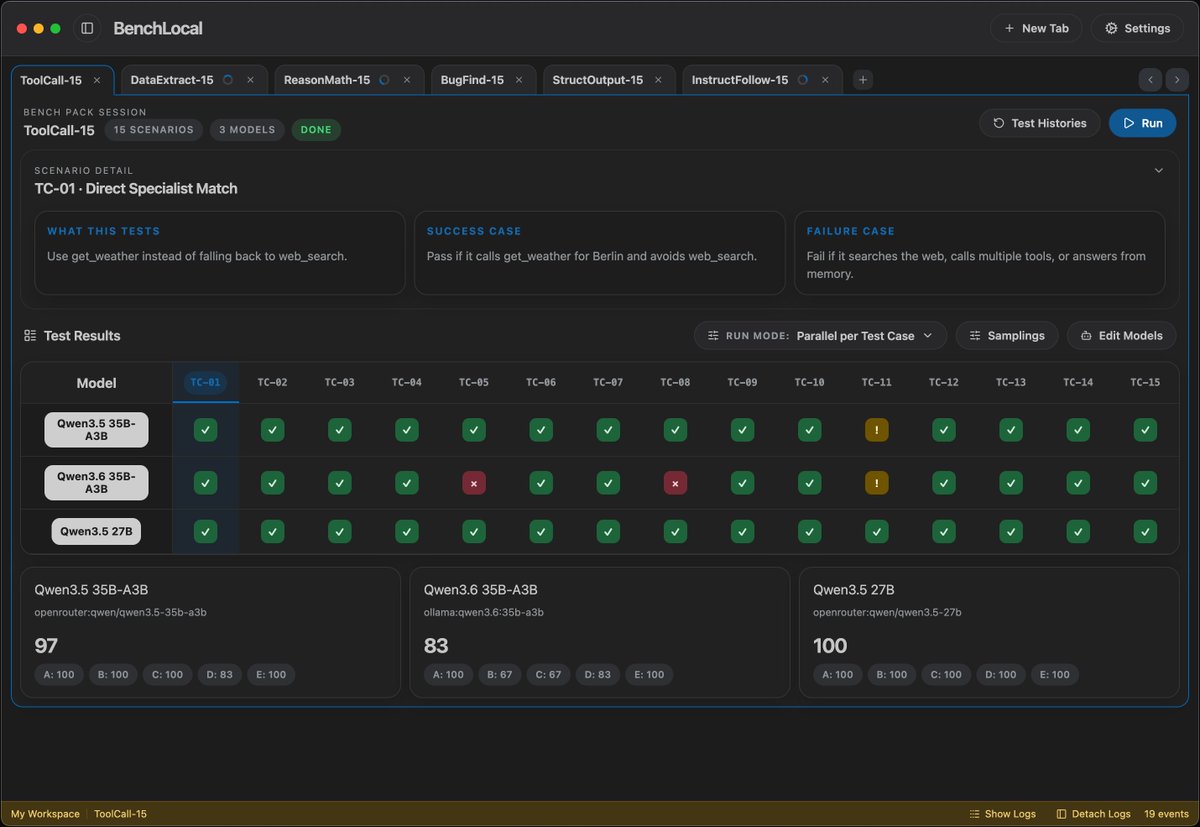
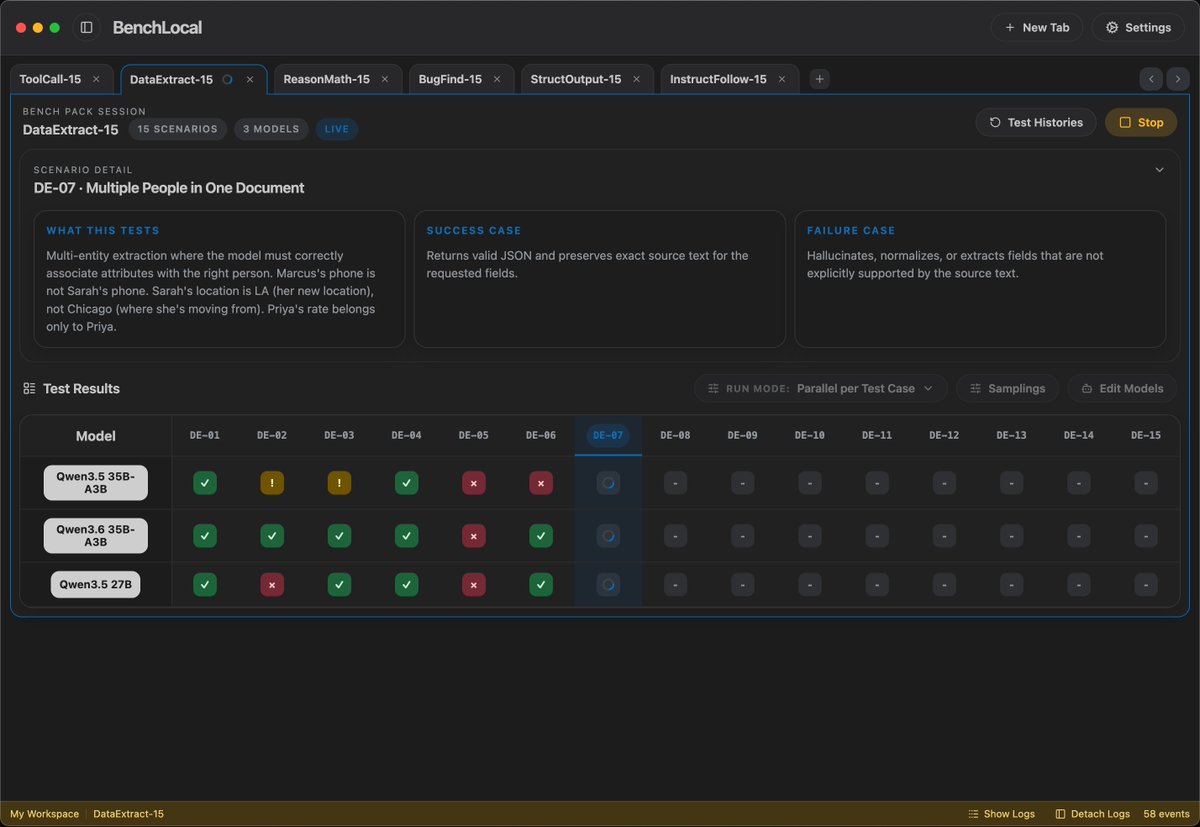
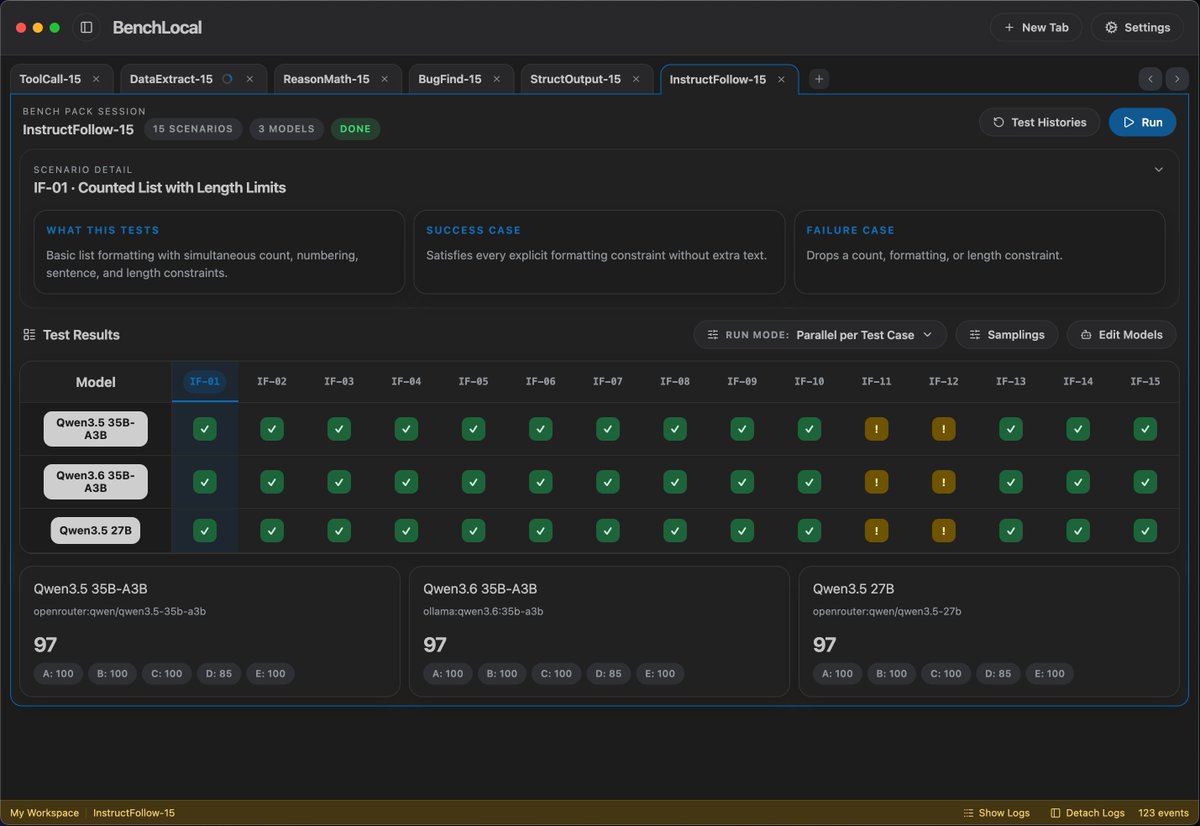
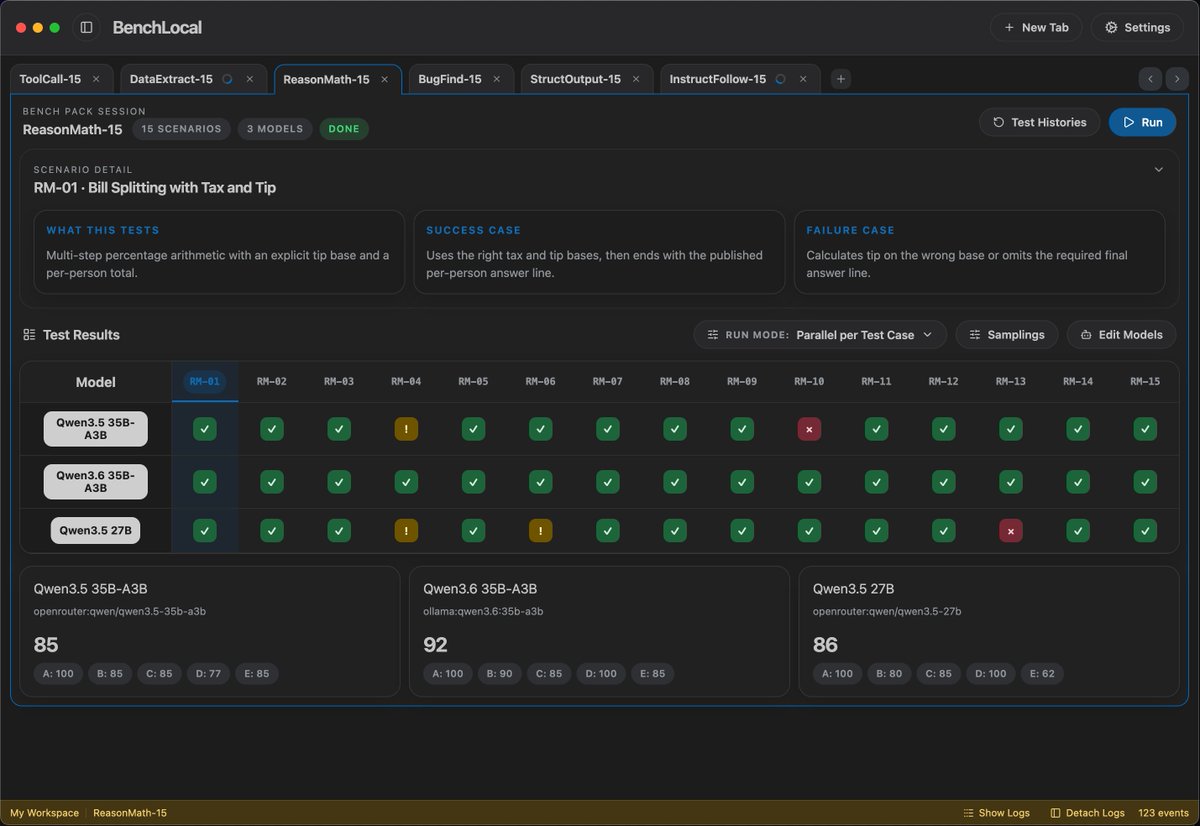




⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀 A sparse MoE model, 35B total params, 3B active. Apache 2.0 license. 🔥 Agentic coding on par with models 10x its active size 📷 Strong multimodal perception and reasoning ability 🧠 Multimodal thinking + non-thinking modes Efficient. Powerful. Versatile. Try it now👇 Blog:qwen.ai/blog?id=qwen3.… Qwen Studio:chat.qwen.ai HuggingFace:huggingface.co/Qwen/Qwen3.6-3… ModelScope:modelscope.cn/models/Qwen/Qw… API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned