
G🐙
356 posts


Hello – I am the world's only Siri AI consultant & expert on App Intents.
I can design your Intents, Entities, & Siri integrations to save you time, remove guesswork, and get feature-worthy results.
I currently have availability for client work – register your interest now 👇

English
@OrcaRouter Beat you to it but the bigger name always wins in the end:
github.com/GiannoKlein9/H…
English

Fable 5 is dead. We just resurrected it — cheaper, open and you hold the keys.
OpenRouter dropped Fusion 48h ago and broke the internet.
We tested it hard. The synthesizer is insane for deep research… but absolute dogshit for coding. So we fixed it.
Meet OrcaRouter.ai DSL — the version you actually own. One prompt → fans out to any panel you want
→ judge + synthesizer → one god-tier answer.
But unlike black-box slugs, you control the entire graph in YAML.
Fable 5 level intelligence… without waiting for Anthropic to turn it back on 🧵👇
English

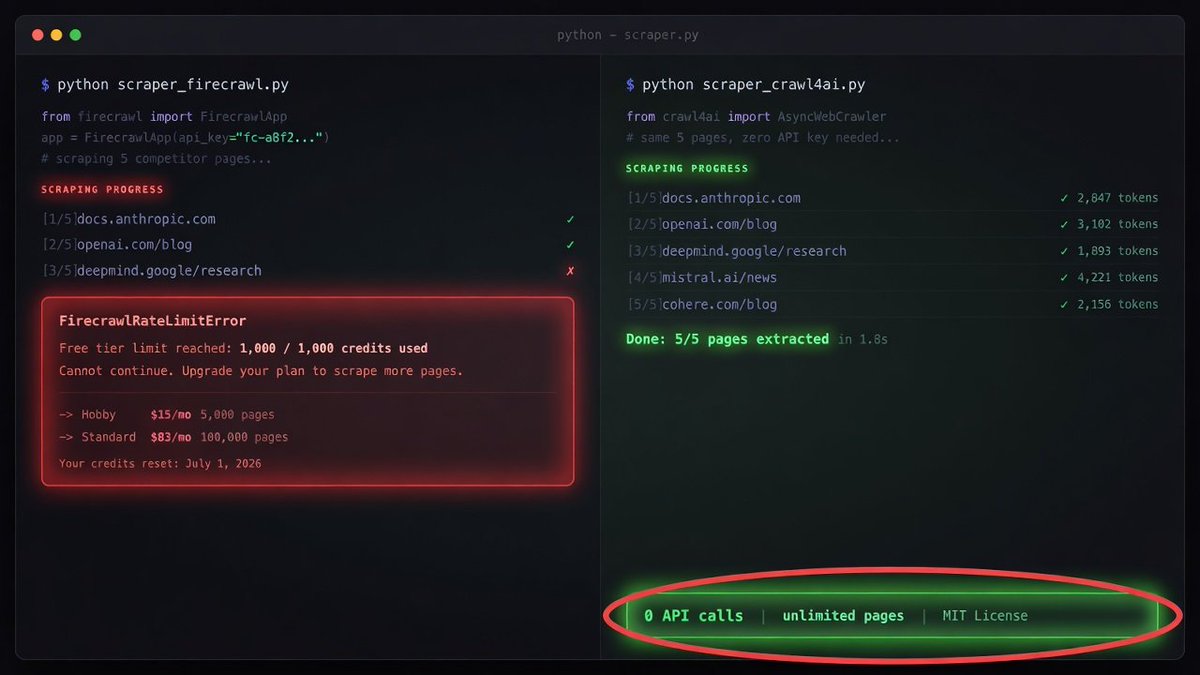
your AI agent can read any website for free - Firecrawl caps you at 1,000 pages then charges 😳
crawl4ai has 68K stars on GitHub and it's built specifically for LLMs. it converts any URL into clean markdown your agent can actually process - full page content, structured data, javascript-rendered sites included
what your agent gets for $0:
- read any URL and return clean LLM-ready markdown
- handles javascript-rendered pages (Firecrawl and Jina miss these without paid tiers)
- async crawling - fetch 10+ URLs simultaneously
- structured data extraction with CSS selectors
- screenshot capture for vision models
- works with claude, gpt, gemini, any agent framework
what this replaces:
- Firecrawl: 1,000 pages free then starts charging, $15-83/mo depending on volume
- ScrapingBee: $49/mo for 150K credits
- Apify: $49/mo for their Starter plan
- Jina AI Reader: rate-limited free tier, paid plans for scale
- Browserlessio: $60/mo for cloud browser sessions
why this matters:
- most agents are blind to live web content because scraping APIs cost money
- crawl4ai gives any agent real-time access to any URL at zero marginal cost
- perfect for research agents, content monitors, competitor tracking, price watchers
how to set up (2 min):
> pip install crawl4ai
> crawl4ai-setup
> from crawl4ai import AsyncWebCrawler
> async with AsyncWebCrawler() as crawler:
result = await crawler.arun(url="anysite.com")
print(result.markdown)
important:
- renders javascript before extracting so dynamic sites work
- MIT licensed, fully open source, actively maintained
- works with claude code, cursor, langchain, crewai, autogen
- 68K stars - not a side project, proper team and roadmap
- not for mass commercial crawling - built for agentic research and prototyping
let your agent read the entire web for $0
while everyone else hits rate limits and monthly bills
bookmark this before the free tier closes
Isra@israfill
your agent can search Twitter, Reddit, and GitHub for free - zero API keys, zero billing 😳 agent-reach is trending on github with 23K stars. it lets your AI agent read Twitter posts, browse Reddit threads, search GitHub repos, watch YouTube videos - all without paying for a single API subscription what your agent accesses for $0: - Twitter/X posts, profiles, and search - Reddit threads and comments - YouTube videos, metadata, and search - GitHub repos, issues, and profiles - 10+ more platforms - all in one pip install what this replaces: - Twitter API: $100/mo for basic access - Reddit API: rate-limited free tier, expensive at scale - YouTube API: quota limits, pay for more - GitHub API: generous but still rate-limited why this matters: - most AI agents are blind to the internet because APIs cost money - this gives any agent real-time web access at zero marginal cost - perfect for research agents, content radar, competitive intel, market analysis how to set up (2 min): > pip install agent-reach > run: agent-reach doctor > connect it to your agent as a tool > done - your agent can now search the internet for free important: - uses direct parsing, not official APIs - no keys needed - works with claude code, cursor, aider, langchain, any agent framework - MIT licensed, fully open source - not for production web scraping at scale - use for agentic research and prototyping - 23K stars and trending - community vetted let your agent browse Twitter, Reddit, and GitHub for $0 while everyone else is paying $100+/mo for API access bookmark this before payying for extra api ↓ repo in comment
English
@robinebers The worst are the ones that start with “ Someone just open sourced…”
Then proceeds to self advertise.
English

blocking 10 accounts like this every single day

English


The main issue I have is that Fable was included in my $200/month subscription and this one requires more tokens spending. Inspired by this I built my own Fusion at home using the subscriptions I'm already paying.
OpenRouter@OpenRouter
Introducing the Fusion API, the smartest compound model in the market. Fusion achieves Fable-level intelligence at half the price. How it works 👇
English
@cobi_bean AI is still advancing and rn I see people with 50+ lines in their agents Soul.md
That’s a lot of context bloat. Let your skills do the talking. This way only relevant context is loaded if the skill is needed.
And that’s how you gain efficiency
English

@giannoklein i mean maybe?
it’s a file that gets read at runtime every new session.
i don’t think you can put too much emphasis.
the tools that you put around the Agent are just as important, but it starts at the runtime
English
@benln Openrouter’s Fusion API. But you choose the models and control the costs.
x.com/giannoklein/st…
G🐙@giannoklein
Just shipped HermesFusion🚀 A bring-your-own-model fusion runner for local, cloud, or hybrid backends. Lite: 2-model panel Heavy: 3-model panel No hosted middleware. No forced provider. No per-call markup. First repo is live: github.com/GiannoKlein9/H…
English

@boringmarketer Or you can test out this — based on Openrouter’s Fusion AI:
x.com/giannoklein/st…
G🐙@giannoklein
Just shipped HermesFusion🚀 A bring-your-own-model fusion runner for local, cloud, or hybrid backends. Lite: 2-model panel Heavy: 3-model panel No hosted middleware. No forced provider. No per-call markup. First repo is live: github.com/GiannoKlein9/H…
English

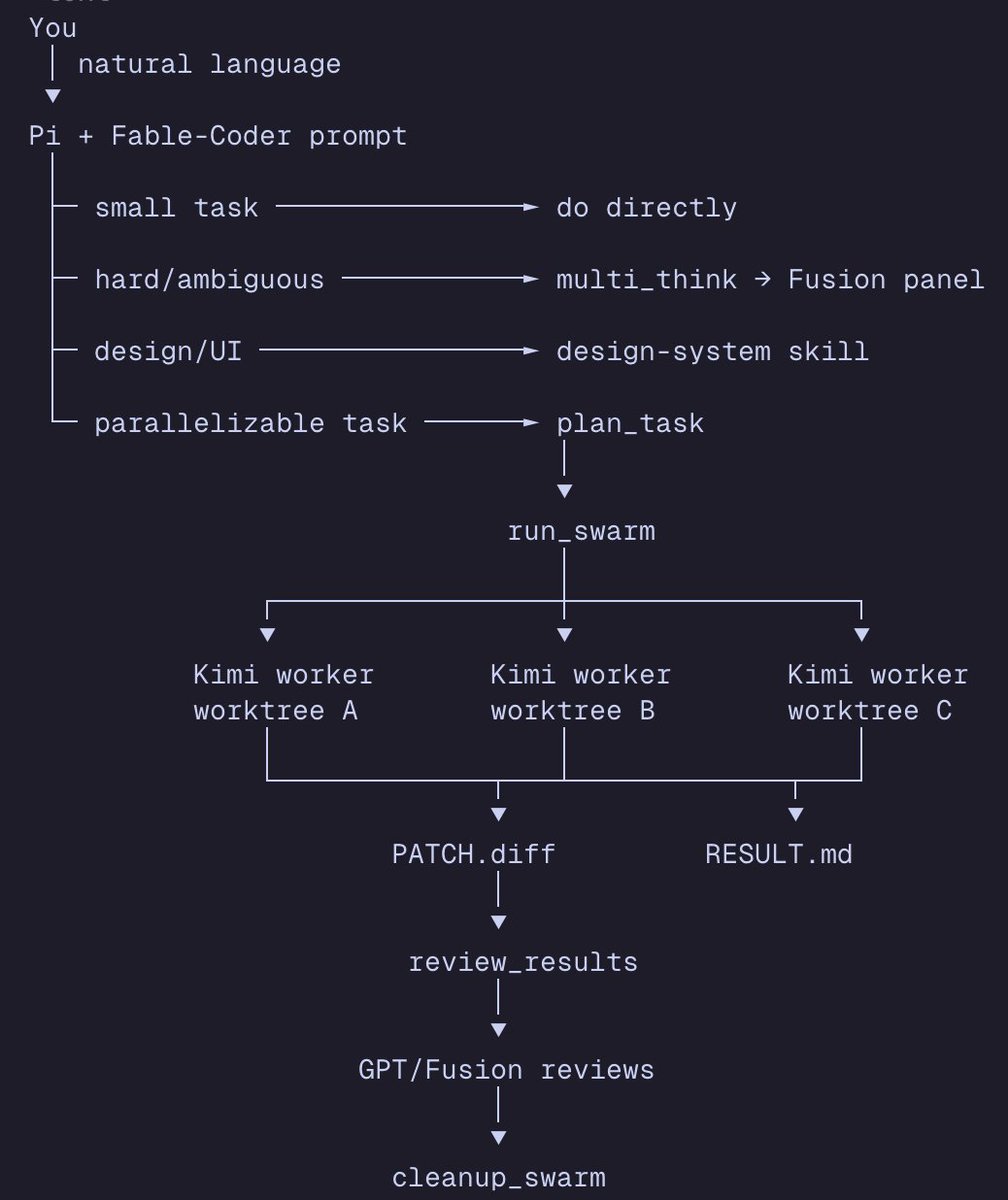
if you want Fable level performance NOW, the answer is to build your own coding harness
here's how I'm doing it
(in a lightweight Pi-native way rather than a heavy Superpowers/Compound clone)
first, I think we're going to see PERSONAL HARNESSES that derisk single model reliance, help users save money, and squeeze top frontier performance out of homegrown systems
The best engineers I know already do this...
1) Use Pi, the open source coding harness that you can make your own and access any model from
2) Set 5.5 codex as your default model
3) Deeply analyze publicly available system prompts (guess which model I looked at?)
4) Feed Codex context on Loop Engineering and other engineering skill repos
5) As it to improve efficiency as a lot of engineering repos are super heavy and bloated/slow
6) Ask it to use FUSION via Openrouter for planning, logic, and review tasks
7) Ask it to use Kimi k2.7 code for subagents/execution
8) Have it dog food the harness until it's dialed in then unleash it on a repo for a deep analysis
English
Just shipped HermesFusion🚀
A bring-your-own-model fusion runner for local, cloud, or hybrid backends.
Lite: 2-model panel
Heavy: 3-model panel
No hosted middleware.
No forced provider.
No per-call markup.
First repo is live:
github.com/GiannoKlein9/H…

English
@hqmank Built my own version for Hermes Agents.
You can use your own models instead of being locked by OpenRouter. Check it out:
github.com/GiannoKlein9/H…
English
OpenRouter just introduced Fusion API, a compound model that claims Fable 5-level intelligence at half the price.
Sounds impressive, but I’d like to see how it holds up in real-world use.
Has anyone tried it yet?
OpenRouter@OpenRouter
Introducing the Fusion API, the smartest compound model in the market. Fusion achieves Fable-level intelligence at half the price. How it works 👇
English
Read the Agent-Reach code so you don't have to learn the hard way.
The README is doing PR work on "free." Exa and Jina are freemium with cliffs the README doesn't version. Groq Whisper is the transcribe default and needs your own key. Reddit has no zero-config
headless path — the docstring is right, ignore it and you'll spend a Saturday debugging throttled public JSON.
Security is actually honest. Argv-list subprocess everywhere, no shell=True, no pickle, no eval, yaml.load is safe_load, MCP server is clean, SECURITY.md with private disclosure, install is home-scoped. The one real attack surface is the cookie extraction TOCTOU window — briefly readable by any same-UID process between tempfile creation and deletion. Real, but narrow.
The structural risk nobody talks about: one maintainer, 32 of 34 commits, no CODEOWNERS. The Playwright browser binary download is
the real surprise even if you never use OpenCLI. Pin to a commit SHA, not the moving main zip. Sandbox-test in a throwaway container.
Promising. Sandbox-test, then watch.
English
your agent can search Twitter, Reddit, and GitHub for free - zero API keys, zero billing 😳
agent-reach is trending on github with 23K stars. it lets your AI agent read Twitter posts, browse Reddit threads, search GitHub repos, watch YouTube videos - all without paying for a single API subscription
what your agent accesses for $0:
- Twitter/X posts, profiles, and search
- Reddit threads and comments
- YouTube videos, metadata, and search
- GitHub repos, issues, and profiles
- 10+ more platforms - all in one pip install
what this replaces:
- Twitter API: $100/mo for basic access
- Reddit API: rate-limited free tier, expensive at scale
- YouTube API: quota limits, pay for more
- GitHub API: generous but still rate-limited
why this matters:
- most AI agents are blind to the internet because APIs cost money
- this gives any agent real-time web access at zero marginal cost
- perfect for research agents, content radar, competitive intel, market analysis
how to set up (2 min):
> pip install agent-reach
> run: agent-reach doctor
> connect it to your agent as a tool
> done - your agent can now search the internet for free
important:
- uses direct parsing, not official APIs - no keys needed
- works with claude code, cursor, aider, langchain, any agent framework
- MIT licensed, fully open source
- not for production web scraping at scale - use for agentic research and prototyping
- 23K stars and trending - community vetted
let your agent browse Twitter, Reddit, and GitHub for $0
while everyone else is paying $100+/mo for API access
bookmark this before payying for extra api
↓ repo in comment

Isra@israfill
you can build production AI agents with GPT-5.5, grok 4.20, AND kimi k2.6 - 500 runs/month for FREE 😳 no credit card, google login works. stackai were acquired by asana last year and just opened up their free tier what you get for $0: - 500 agent runs per month (resets monthly) - GPT-5.5, grok 4.20, kimi k2.6, claude, gemini, 30+ model providers - visual drag-and-drop workflow builder (no code needed) - RAG from documents, web, google drive, notion - multi-modal: vision, text-to-speech, speech-to-text - logic nodes: python, javascript, code execution - browser extension, slack bot, REST API access - 2 projects, 1 seat what sets it apart from other free agent builders: - founded by MIT PhDs, backed by $16M series A - acquired by asana - not a random startup - 100+ enterprise integrations (salesforce, sharepoint, snowflake) - human-in-the-loop oversight - SOC 2 / HIPAA / GDPR compliance even on free tier - switch models per step in your workflow how to get started (3 min): > go to stackai.com > sign up with google - no credit card > create a new project > pick your model (GPT-5.5, grok, kimi, claude, whichever) > build your agent with the drag-and-drop editor > publish and use the chat UI or API endpoint important: - 500 runs/month limit - fine for testing and prototyping - 2 projects cap - enough to experiment - you can use temporary emails for multiple accounts to extend runs - no production SLA, this is for building and learning - runs reset monthly, not daily visual agent builder + 5 frontier models + enterprise integrations = $0 while everyone else pays $20/mo for each model subscription bookmark this before the free tier changes
English
G🐙 리트윗함

Vector databases are no longer a cloud product. They're becoming a pip install.
A new open-source project called turbovec just crossed 10K stars on GitHub. And once you understand what it does, you understand why.
It's a Rust vector index with Python bindings, built on Google Research's TurboQuant algorithm, a quantizer accepted at ICLR 2026 that compresses embeddings to within a hair of the theoretical Shannon limit.
No codebook training. No train phase. No rebuilds as your corpus grows. You add vectors, they're indexed. Done.
The headline number: A 10 million document corpus takes 31 GB of RAM as float32. turbovec fits it in 4 GB and searches it faster than FAISS.
Read that again. Faster than FAISS. The library Meta has tuned for a decade. Hand-written NEON and AVX-512 kernels beat FAISS FastScan by 12–20% on ARM and match-or-beat it on x86.
(And the recall benchmarks are published openly against FAISS as the baseline including the configs where it loses. That honesty alone is rare in this space.)
But the speed isn't even the strategic part. The strategic part is what this enables:
Fully local, air-gapped RAG.
10M documents in 4 GB means your entire company knowledge base fits in the RAM of a MacBook. Pair it with an open-source embedding model and nothing not a query, not a vector, not a document ever leaves your machine.
It also ships drop-in replacements for the vector stores inside LangChain, LlamaIndex, and Haystack. Swap one import, keep your pipeline. The switching cost is approximately zero.
The obvious comparison is SQLite.
Databases used to be servers you provisioned and paid for. Then SQLite made the database a file inside your app, and an entire category of managed infrastructure became optional for most use cases. The same compression-driven collapse is now coming for vector search.
Every startup selling "managed vector search" as a line item should be paying attention. When the index fits in laptop RAM, runs faster than the industry standard, and installs in one line the moat was never the database.
The vector database is becoming an embedded library, not a cloud service. And the frontier of RAG just moved on-device.
Really cool to see.

English


‘The Elder Scrolls VI’ was announced 8 years ago today

English
G🐙 리트윗함

➡️ Easier way, no need to disable SIP:
sudo defaults write "/Library/Preferences/FeatureFlags/Domain/GenerativeModels.plist" "EnhancedSiriWaitlist" -dict-add Enabled -bool NO
ldt@madeby_ldt
How to bypass the new Siri waitlist (Mac only): 🧵 #WWDC26
English


Now, you can invite a friend to join Codex, and you get a rate limit reset. That's actually really cool!

English
G🐙 리트윗함





G🐙 리트윗함

THE NEW WORLD ORDER
Meta
Anthropic
Nvidia
Google
OpenAI
SpaceX

Chris@ChrissGPT
the new world order
English