고정된 트윗

🚨Model alert!🚨
We're very proud to release the biggest decoder-only auto-regressive GPT model for Spanish ✍️
🧠 Model: huggingface.co/bertin-project…
💾 Dataset: huggingface.co/datasets/berti…
💻 Demo: huggingface.co/spaces/bertin-…
English
Javier de la Rosa @[email protected]
16.4K posts

@versae
Research Scientist (NLP) at @Nasjonalbibl AI-Lab. Formerly, @UNED, @stanfordCIDR, @CulturePlex. «sin peripecias de relieve»


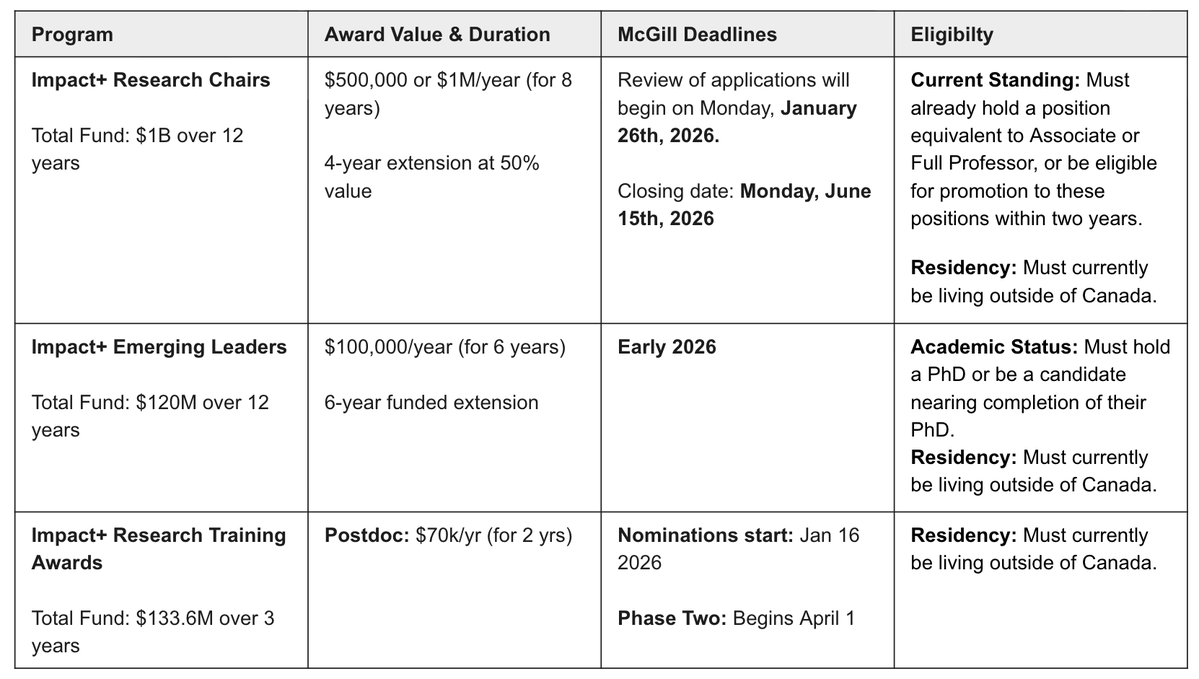
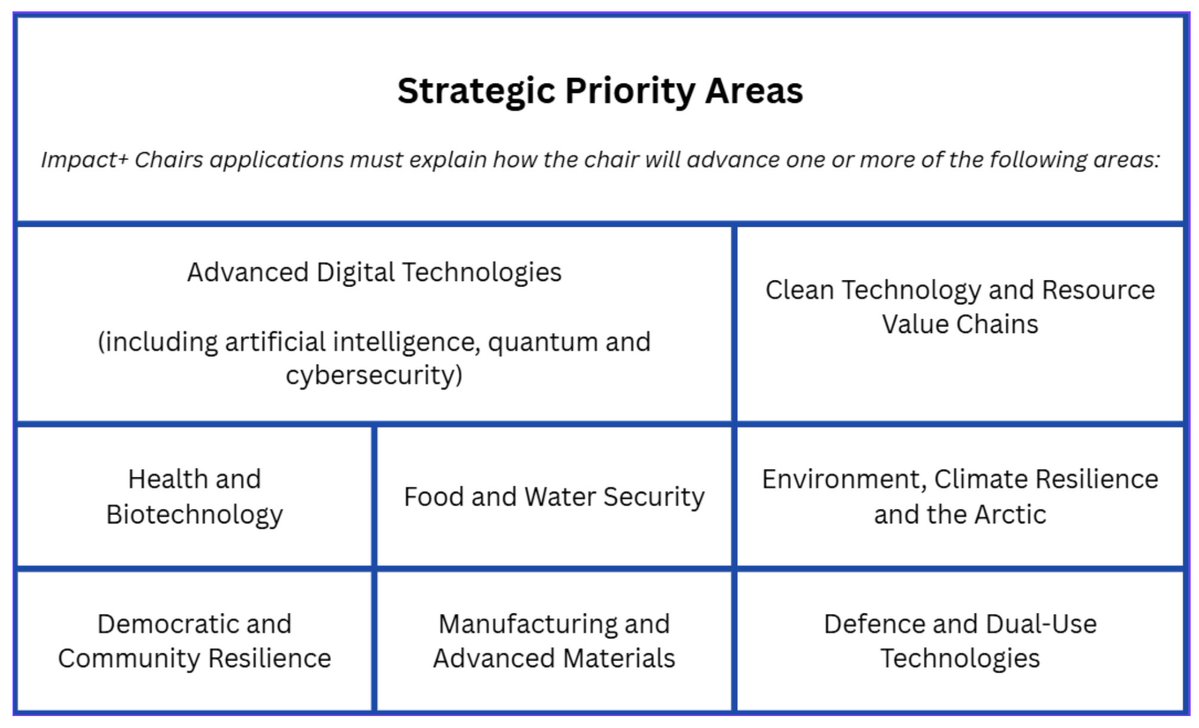




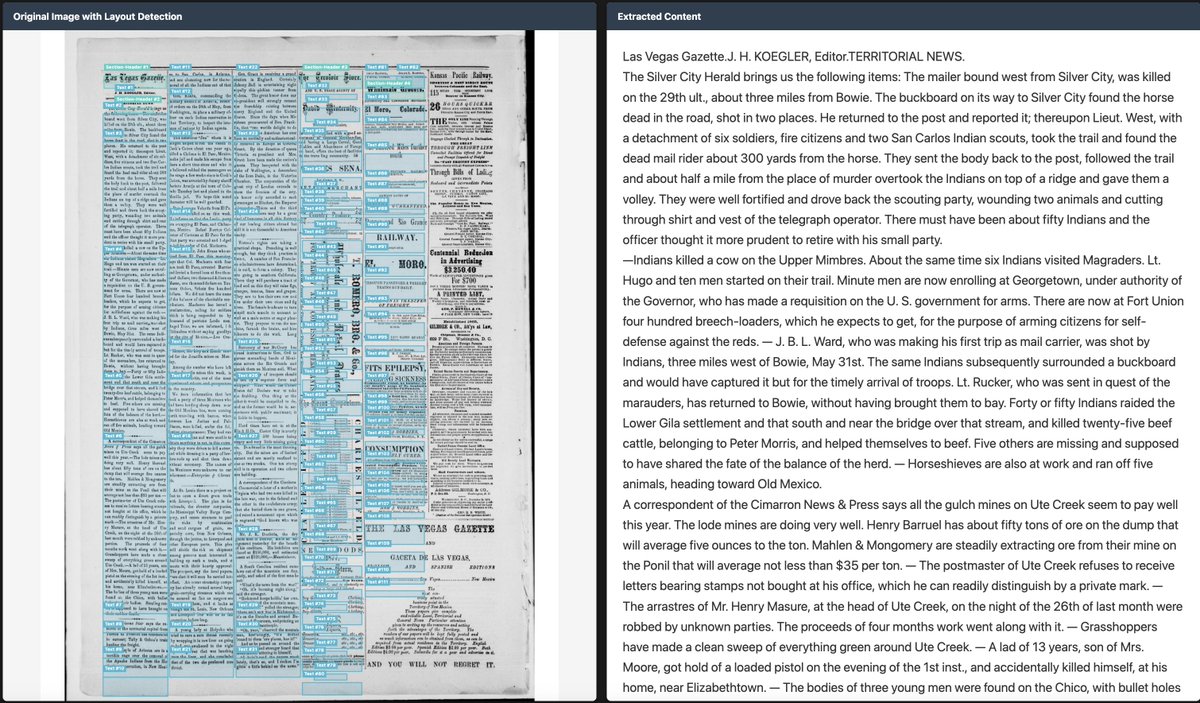









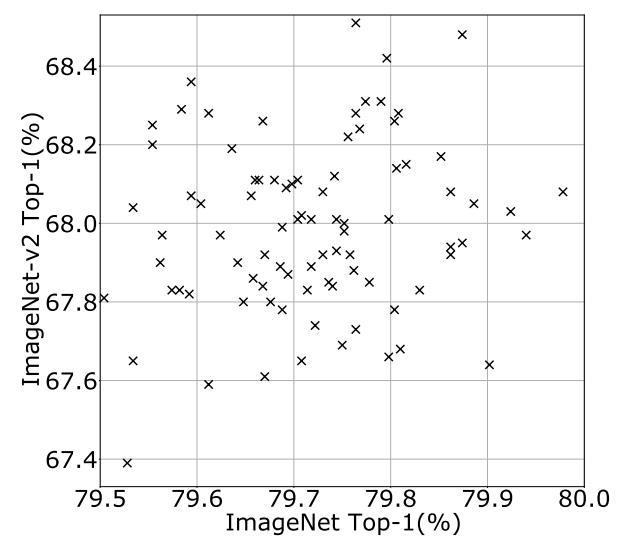
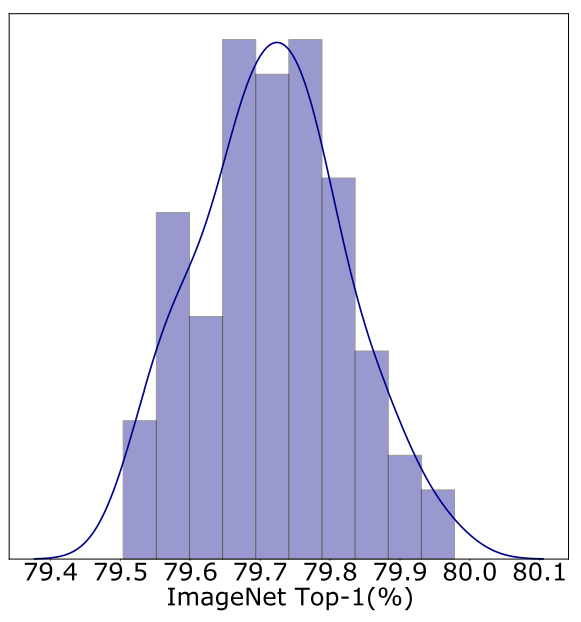
Interesting legal argument from META; the use of a single book for pretraining boosts model performance by 'less than 0.06%.' Therefore, taken individually, a work has no economic value as training data.







📢✨ PAPER ALERT ✨📢 Ever wondered whether copyrighted material **actually** makes for better LLMs? 🤔 We asked the same question—and the results are in! Our paper is accepted at NoDaLiDa/Baltic-HLT 2025, and the pre-print is live: 🔗 arxiv.org/abs/2412.09460 🧵👇