Mike Ballesteros retweetledi
Mike Ballesteros
450 posts

Mike Ballesteros
@maballesterosv
CTO y co-founder de @GoKoan y @gokoan_ai. Imaginando cómo hacer que la tecnología ayude a la gente a aprender más en menos tiempo 📚 #edtech #ai #nlp
Katılım Mart 2012
235 Takip Edilen97 Takipçiler

Mike Ballesteros retweetledi

Mike Ballesteros retweetledi

Mi hot take sobre el futuro de la industria del software
Todo lo que diga aquí es mera interpretación desde mi punto de vista. No pretendo hacer futurología ni sentar cátedra, pero sí mojarme.
Creo que es indudable que la llegada de la Inteligencia Artificial a la programación la ha cambiado por completo. Quizás todavía no de la forma radical que algunos promulgan, pero sí la ha cambiado. Eso ya es una realidad.
Ahora bien, los cambios estructurales no se producen de la noche a la mañana. No nos vamos a levantar un día con la mitad de los puestos de trabajo desaparecidos. Pero ese día llegará. Las cosas pasan de forma gradual, a lo largo de meses o unos pocos años, como la inflación. No notas nada hasta que, de repente, te das cuenta de que los huevos cuestan el doble que hace un par de años.
Creo que algo muy parecido va a pasar con la programación.
La primera fase: el silencio
En una primera fase empezarán a moverse las grandes estructuras.
Lo primero no serán despidos masivos, sino **congelaciones de contratación**. Las empresas intentarán absorber las nuevas demandas de crecimiento con el mismo personal. Será una especie de layoffs silenciosos.
Y lo interesante es que nadie se dará cuenta. Nadie dirá que perdió su trabajo. La industria seguirá creciendo, pero sin aumentar proporcionalmente el número de personas. El output crecerá, el headcount no.
Cuando este modelo esté más controlado y, sobre todo, cuando empiecen a sentirse presionados por la aparición de equipos muy pequeños capaces de generar una competencia brutal contra los grandes actores establecidos, empezarán los layoffs progresivos.
No de golpe. Poco a poco.
Qué perfiles "sobreviven"
Desde mi punto de vista, quedarán básicamente dos tipos de perfiles.
Por un lado, los ultraespecializados. Gente muy senior, con muchísima experiencia, absolutamente fuera de serie en un área concreta. Ese nivel de expertise todavía va a tardar en ser sustituido, si es que llega a serlo del todo.
Y por otro lado, los orquestadores. Personas multidisciplinares de altísimo nivel. Y aquí hago énfasis en lo de alto nivel: no vale ser “un poco de todo” con poca profundidad. Hablo de gente que entiende producto, tecnología, infraestructura, negocio y trade-offs reales. Roles que hoy ocupan muchos CEOs o CTOs fuertes.
La gente de producto seguirá existiendo, pero cada vez más cercana a la tecnología real. Menos PowerPoint y más comprensión profunda de lo que se construye.
Los grandes perdedores: el middle management
Creo que los perfiles más afectados serán los middle managers.
Su trabajo se basa en ser piezas dentro de estructuras de procesos jerárquicas. Aportan valor principalmente desde la gestión, no tanto desde la construcción directa del producto.
No encajan en la ultraespecialización, pero tampoco en el perfil transversal fuerte.
Quedan en tierra de nadie.
¿Aplica la paradoja de Jevons a la programación?
Aquí es donde siempre tengo la duda.
Podría plantearse un escenario optimista: si baja el coste de crear software, si hacer una aplicación pasa de costar 100.000 dólares a costar 3.000, la demanda podría dispararse. Muchísima más gente podría permitirse crear software. La industria, en lugar de contraerse, crecería.
Este razonamiento encaja muy bien con la paradoja de Jevons: cuando un recurso se abarata, su consumo total aumenta.
El problema es que, objetivamente, tengo la sensación de que en software no aplica del todo.
Y no porque el software vaya a desaparecer. Todo lo contrario: el software va a estar más presente que nunca en todos los aspectos de nuestra vida. Todo será software. Y la otra mitad hardware. Y la otra mitad experiencias físicas.
La pregunta no es si habrá software, sino si necesitamos tanto software nuevo.
El elefante en la habitación: ¿queda innovación real?
Esto es algo que ya venía de antes de la IA.
Llevamos un par de décadas creando grandes categorías digitales:
- Comunicación y redes sociales
- Movilidad, logística y servicios bajo demanda
- Economía digital personal
- Productividad, trabajo y software utilitario
- Salud, fitness y bienestar
- ...
La pregunta es: ¿independientemente de la IA, dónde acaba esto?
¿Por qué necesitamos otra app de notas más? ¿Cuándo necesitamos una nueva red social?
¿Necesitamos el nuevo Facebook? ¿El siguiente Notion?
¿Hay hueco para más innovación a esta velocidad?
Tengo la sensación de que los grandes conceptos ya se han creado. Hay players muy fuertes en cada categoría y no veo un futuro de hiperfragmentación infinita en miles de nichos absurdamente específicos.
No veo el escenario de "una app de notas para creadores", "una app de notas para futbolistas", ...
Y aunque la IA abarate el coste y haga viable cualquier micro-nicho desde el punto de vista económico, aparece otro problema enorme: la distribución.
El problema de la distribución no es nuevo. Lo único que hace la IA es agravarlo.
Aquí entra de lleno la attention economy: el recurso escaso ya no es el código, ni el talento técnico, ni siquiera el capital. Es la atención humana.
Si existen 10 millones de aplicaciones de notas, da igual lo buena que sea la tuya: competir por atención se vuelve casi imposible. La abundancia extrema no libera, satura.
Por eso tiendo a pensar que la IA no va a generar una explosión de nuevos productos exitosos, sino acelerar la comoditización de la tecnología que ya estaba en marcha.
Quedarán dos mundos: gigantes y artesanos
Aquí encaja muy bien el marco clásico de Porter: comoditización vs diferenciación.
Cuando el coste de producción se desploma, solo sobreviven dos extremos:
1. Los grandes: Grandes empresas tecnológicas con músculo, capacidad de amortiguación y, sobre todo, distribución. Plataformas que te dan correo, notas, pagos, almacenamiento, lo que sea. Aquí aplica claramente un modelo winner takes most: pocos ganan mucho, muchos compiten por migajas.
2. Los artesanos: Pocos, selectos, casi artesanos del software. Productos muy curados, muy especializados, o con una ventaja clara de autoridad, marca o distribución propia.
El término medio, el grueso de productos y empresas "correctas pero no extraordinarias", desde mi punto de vista, desaparece.
Esto nos lleva a pensar en que existe un cambio estructural de fondo
Hasta ahora, el crecimiento de la industria tecnológica se basaba en una limitación clara: no había suficientes ingenieros.
Muchísima demanda para muy poca oferta. Eso elevaba salarios, atraía inversión y generaba ese clima de abundancia, de "dinero fácil", de crecimiento casi automático.
Con el abaratamiento masivo del trabajo intelectual técnico, la pregunta clave es:
Si reducimos el coste de creación por diez, ¿se multiplica la demanda por diez?
Y la verdad es que tengo mis dudas.
Esto no va a pasar de golpe. Será lento, silencioso. Un día te despertarás y te darás cuenta de que todo ha cambiado. Siempre pasa así.
Si seguimos tirando del hilo, esto nos lleva más allá del software: la comoditización del trabajo intelectual
Y aquí ya no hablamos solo de programadores.
Mi apuesta es que esto forma parte de algo mucho más grande: la comoditización del trabajo intelectual.
Nos tranquiliza pensar que la IA "no es realmente inteligente", pero la mayoría de trabajos del planeta no requieren inteligencia en el sentido humano. Requieren conocer un conjunto de datos, saber consultarlos y devolver respuestas coherentes.
La auténtica revolución es poder consultar bases de datos semánticamente y poder obtener respuestas ad-hoc y de forma instantánea.
Ese es el gran avance. No la inteligencia, sino la búsqueda semántica real.
Antes necesitábamos un experto intermedio que tradujera una pregunta humana a un lenguaje técnico, consultara la base de conocimiento y devolviera una respuesta. Ese intermediario ya no es imprescindible.
Esto no es algo que vaya a pasar. Esto ya ha pasado.
¿Y ahora qué?
No voy a aventurarme a predecir qué ocurrirá en 10, 15 o 20 años. No tengo ni idea.
Pero ya que me estoy enfangando, hagámoslo hasta el fondo.
Hay algo que sí tengo claro: esta conversación no va solo de software, ni de ingenieros, ni siquiera de tecnología. Va de qué hacemos cuando el trabajo deja de ser el eje central de la vida.
Vamos a vivir, queramos o no, debates profundos sobre rentas básicas universales, sobre el valor social del trabajo, sobre el propósito, sobre identidad.
Para mí, la pregunta no es si ocurrirá. La pregunta es: ¿en qué momento vamos a empezar a hablar de esto en serio?
Si has llegado hasta aquí, me encantaría conocer tu opinión.
Todo lo que he expuesto, no es más que un divague manifestado en voz alta de algo a lo que llevo dando la vuelta hace meses, y para lo que todavía no tengo respuesta con certeza.
Español
@antor ¿Podrías ampliar para los que no tenemos ni idea -pero nos interesa-, cómo/dónde conseguir tu secuencia? La respuesta que le darías a un familiar, que a ChatGPT ya sé que puedo preguntarle. Tx de antemano.
Español

Meet GATTACA: DIY 23andMe-style reports from your own sequencing data.
You sequence once (WGS is now <$400), then run:
gattaca report --vcf your_dna.vcf.gz --type phenotype
50+ traits.
No subscription.
No company storing your DNA.
Your data stays yours.
English
I am open sourcing a tool that told me I may be partially resistant to HIV.
I carry CCR5-delta32 , the same mutation that led to the first person ever cured of HIV: ~10% of Europeans have this. Most will never know.
OWN your DNA sequence.
Use GATTACA to analyze it.

English
Mike Ballesteros retweetledi

Introducing Among AIs, a social reasoning benchmark where embodied models play Among Us to test social intelligence: deception, persuasion, and coordination.
We put 6 SOTA models in a live arena and GPT-5 came out on top by leading in Impostor & Crewmate wins. Why did GPT-5 get the highest scores? Why Among AIs?
Let’s break it down 👇

English

Mike Ballesteros retweetledi

What if you could not only watch a generated video, but explore it too? 🌐
Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt.
From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
English
@darkdreammer @360_Hardware Ahora el reto es saber paralelizar las tareas que le pides. Combinar desarrollo de features con limpieza de deuda técnica me está funcionando bien para que no interfieran entre sí. ¿Cómo lo abordas tú? Ah, y un buen AGENTS.md, claro.
Español


Cada vez que sale un nuevo LLM que es mejor escribiendo código que el anterior:
- Semana 1: Wow, este nuevo LLM es un salto enorme, puede hacer cosas que los anteriores no podían!
- Semana 2: Casi todo mi código lo escribe el nuevo LLM! Esto es una pasada, casi no tengo que programar.
- Semana 3: La verdad es que ahora que lo he probado bastante, encuentro que falla en muchas cosas y en realidad no es capaz de resolver problemas complejos.
- Semana 4: Esto es basura, es incapaz de escribir una función que funcione. No sirve para nada, solo me hace perder el tiempo.
- Semana 5: Wow, este nuevo LLM es un salto enorme, puede hacer cosas que los anteriores no podían!
Estoy en la semana 4 con Claude Sonnet ahora mismo 😂
Español
Ya no se "programa" como antes. En mis inicios con Java recuerdo tener memorizado **todas** las funciones de los paquetes principales, porque no había autocompletado. El autocompletado paso a autocompletado inteligente de la IA. Y ahora el cambio es aún mayor.

Español
Mike Ballesteros retweetledi

The race for LLM "cognitive core" - a few billion param model that maximally sacrifices encyclopedic knowledge for capability. It lives always-on and by default on every computer as the kernel of LLM personal computing.
Its features are slowly crystalizing:
- Natively multimodal text/vision/audio at both input and output.
- Matryoshka-style architecture allowing a dial of capability up and down at test time.
- Reasoning, also with a dial. (system 2)
- Aggressively tool-using.
- On-device finetuning LoRA slots for test-time training, personalization and customization.
- Delegates and double checks just the right parts with the oracles in the cloud if internet is available.
It doesn't know that William the Conqueror's reign ended in September 9 1087, but it vaguely recognizes the name and can look up the date. It can't recite the SHA-256 of empty string as e3b0c442..., but it can calculate it quickly should you really want it.
What LLM personal computing lacks in broad world knowledge and top tier problem-solving capability it will make up in super low interaction latency (especially as multimodal matures), direct / private access to data and state, offline continuity, sovereignty ("not your weights not your brain"). i.e. many of the same reasons we like, use and buy personal computers instead of having thin clients access a cloud via remote desktop or so.
Omar Sanseviero@osanseviero
I’m so excited to announce Gemma 3n is here! 🎉 🔊Multimodal (text/audio/image/video) understanding 🤯Runs with as little as 2GB of RAM 🏆First model under 10B with @lmarena_ai score of 1300+ Available now on @huggingface, @kaggle, llama.cpp, ai.dev, and more
English
@mrm8488 A menudo es más eficaz introducir un estado dinámico en el system prompt que delegar este estado a tools en las que el agente debe decidir si llamar o no (ampliar su contexto). En ocasiones las llamadas a tools no se hacen justo porque no tiene el contexto adecuado.
Español

I call it LLM context ops: the art of keeping in the context window only the info needed at each step to keep iterating.
The parallel with computer RAM helps: RAM is limited, yet your machine runs massive programs. How?
Paging—swapping data between disk (RAG?) and RAM (LLM context) as needed at each step.
English
My passion for how Operating Systems work helped me realize that a limited context window isn't a problem—as long as you keep the necessary information in context at each step.
This insight was also key in developing @maisaAI_’s KPU
Andrej Karpathy@karpathy
+1 for "context engineering" over "prompt engineering". People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits. On top of context engineering itself, an LLM app has to: - break up problems just right into control flows - pack the context windows just right - dispatch calls to LLMs of the right kind and capability - handle generation-verification UIUX flows - a lot more - guardrails, security, evals, parallelism, prefetching, ... So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.
English
Mike Ballesteros retweetledi

Now that o3 can so thoroughly answer any question I might have, I feel like the limiting factor is my ability to think of a question to ask.
English
Mike Ballesteros retweetledi

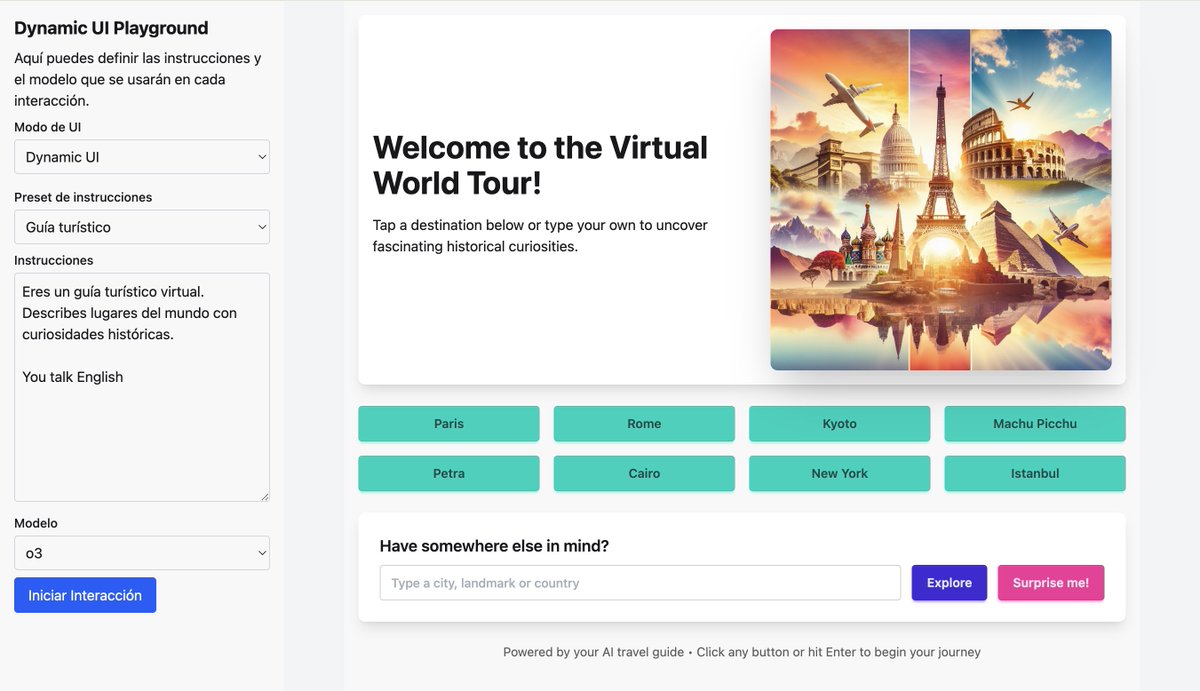
And they can pretty much 'talk' UI about anything... it's just a power no one's really explored yet.
English
Most LLMs can already interact like this, @karpathy. We've seen it in our experiments.

Andrej Karpathy@karpathy
"Chatting" with LLM feels like using an 80s computer terminal. The GUI hasn't been invented, yet but imo some properties of it can start to be predicted. 1 it will be visual (like GUIs of the past) because vision (pictures, charts, animations, not so much reading) is the 10-lane highway into brain. It's the highest input information bandwidth and ~1/3 of brain compute is dedicated to it. 2 it will be generative an input-conditional, i.e. the GUI is generated on-demand, specifically for your prompt, and everything is present and reconfigured with the immediate purpose in mind. 3 a little bit more of an open question - the degree of procedural. On one end of the axis you can imagine one big diffusion model dreaming up the entire output canvas. On the other, a page filled with (procedural) React components or so (think: images, charts, animations, diagrams, ...). I'd guess a mix, with the latter as the primary skeleton. But I'm placing my bets now that some fluid, magical, ephemeral, interactive 2D canvas (GUI) written from scratch and just for you is the limit as capability goes to \infty. And I think it has already slowly started (e.g. think: code blocks / highlighting, latex blocks, markdown e.g. bold, italic, lists, tables, even emoji, and maybe more ambitiously the Artifacts tab, with Mermaid charts or fuller apps), though it's all kind of very early and primitive. Shoutout to Iron Man in particular (and to some extent Start Trek / Minority Report) as popular science AI/UI portrayals barking up this tree.
English
Con esto se empieza a desbloquear la magia... ✨🧙🏼♀️ La consistencia visual entre escenas es fabulosa. ¡Enhorabuena @OriolVinyalsML y equipo!



Oriol Vinyals@OriolVinyalsML
Gemini 2.0 Flash debuts native image gen! Create contextually relevant images, edit conversationally, and generate long text in images. All totally optimized for chat iteration. Try it in AI Studio or Gemini API. Blog: developers.googleblog.com/en/experiment-…
Español
Mike Ballesteros retweetledi

Mike Ballesteros retweetledi
