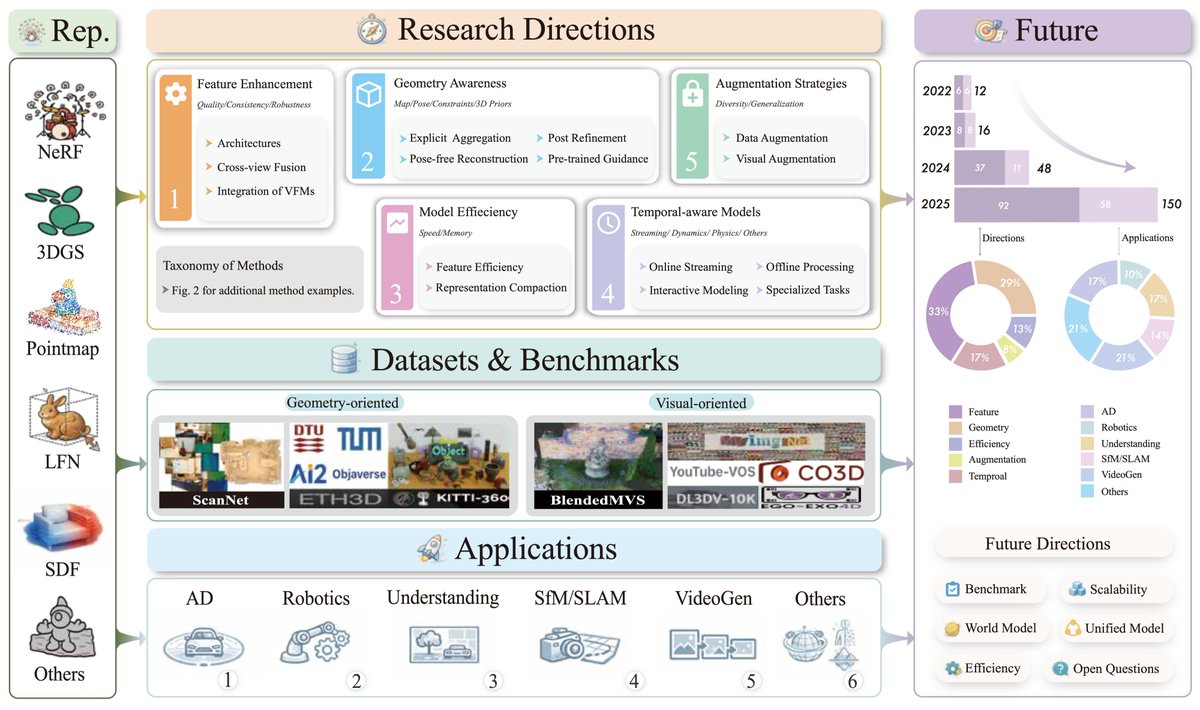
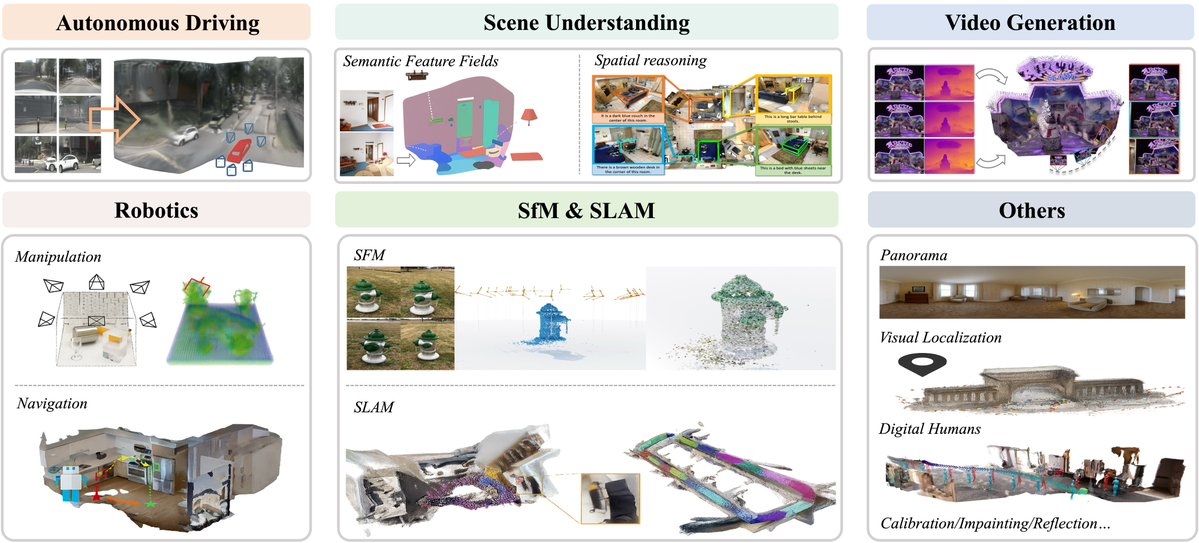
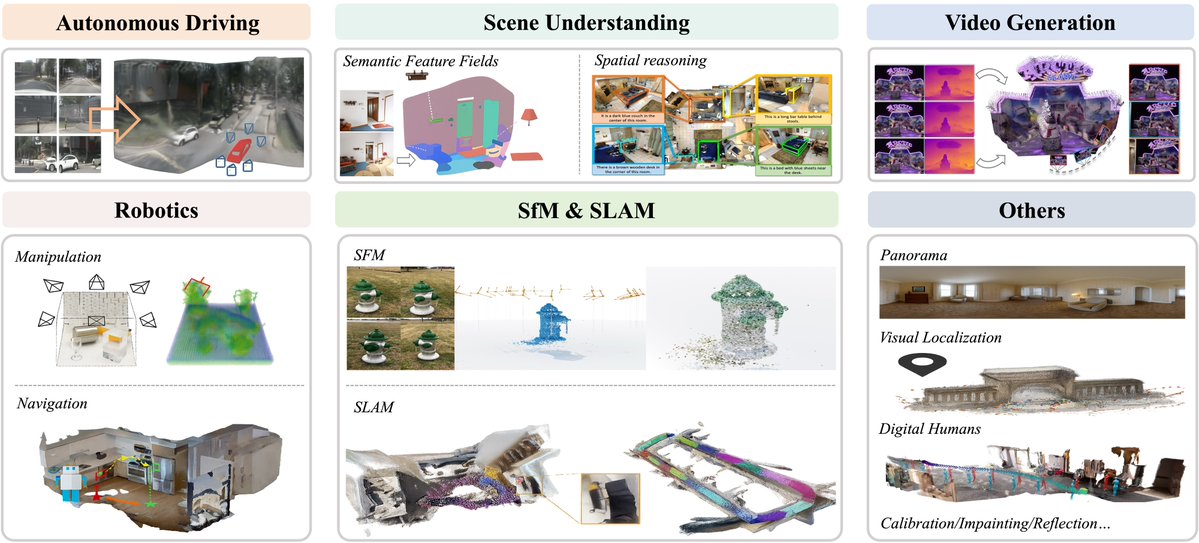
고정된 트윗

🚀 Introducing World-R1: Video models already know 3D — they just need RL to wake it up!
No arch changes. No video training data. No extra inference cost.⬇️
🌐Website: aka.ms/world-r1
English
Weijie Wang
61 posts

@wjwang2003
PhD student at ZIP Lab, Zhejiang University Research Intern @ ByteDance Seed | Microsoft Research


🚀 Introducing World-R1: Video models already know 3D — they just need RL to wake it up! No arch changes. No video training data. No extra inference cost.⬇️ 🌐Website: aka.ms/world-r1