Sabitlenmiş Tweet
July Hata
1.9K posts


July Hata
@0xJuly
flying cars, consumer robotics, jet engines, energy abundance. prev @kittyhawkcorp, now: @faust_machines, @roc_camera https://t.co/6SC16R6prb
SF, CA, USA, Earth Katılım Eylül 2021
429 Takip Edilen976 Takipçiler



Part of the reason I'd argue this is incredibly hard is two fold:
1) Taste / craft is about cultivating sensitivity to the world. The world of ambition often leads to optimization - and optimization often means curtailing the sensitivity to the world itself. Making sure you fight tooth and nail to ensure space for that craft to grow is much easier said than done. Also creativity, and making new things - I mean this in a more creative endeavor environment requires nous and balls. Hard to have conviction - craft and taste seem to be downstream of that
2) The other part is environmental valuation of risk vs reward. I believe that environment is destiny. If you are in a place where the reward / your peer acceptance cycle says one thing (we value creativity!) but rewards another (shorter timelines for outcomes, legibility, lack of larger change etc) you end up optimizing for the meta-game of what is going to return more immediate results in the world. So you end up focus on that
That being said - I believe in people high craft / high ambition - and I also believe it can be done, but hard to cultivate. Something that people say that they often want to do - but most do not want to do this. You want the rights to fruits of your labor, but not many want this path
maja 🔭🍒@majamediaco
lately thinking about companies by ambition and craft some have taste without chasing scale (local cafe). some are optimisation machines. most are in the default zone the rarer type is high craft + high ambition, where taste and growth reinforce each other who belongs there?
English

I want to make things that are tactile but evokes memory. What does that mean? What I mean by that is that you can touch it and you can feel it and remember touching it somewhere at sometime. What we can touch, what we do, for me it often evokes= memories. We compare them to memories. Your favorite toy that you used to bring to bed as a touch and how soft it was. The feeling of a t-shirt the first time you wore it after you bought it. Shoes that fit just right, because you've used them for a while. Tactileness - is a sort of memory.
When I touch objects, I love objects that remind me of a feeling of touching, it transports me through time to places and memories of long ago. Sometimes memories of the future, like this works in a place that doesn't even feel that out of place, but its never been there.
This feeling of remembering, both of the past or the future gives the object a sort of 'rightness' in its existence. Almost like a justification of its existence that goes beyond simple utility, which of course it should serve utility too (nothing wrong with art tho) - but that feeling underneath should hum like a gentle ocean crashing over and over again in the distance.
English
@mynamebedan The next crazy part is realizing if you become Japanese you have to do that for other people so it feels this way
English


@0xJuly @roc_camera i would simply trust my peers over trusting hardware i do not understand
English
app's closed sauce + ios only :(
sdk's oss + has hole :3
steps:
---
1. img captured
2. img written to disk
3. c2pa manifest gen'd
4. img + c2pa signed
5. (optional) send to succinct's prover net
hole:
---
there's a gap between capturing the img & signing, an impl'r can ai-gen an img, forge c2pa manifest, sign it, & gen an sp1 proof about it
other stuff to know:
---
apple attests to signer's p256 pub key from secure enclave
sp1 proof exposes only img hash, app id, & apple root cert; BUT succinct prover sees device id, sig bytes, raw img bytes, & metadata (sus)
Succinct@SuccinctLabs
Today, we're launching ZCAM, an iPhone camera app to Prove What’s Real. ZCAM cryptographically signs photos and videos at the moment of capture. Anyone can independently verify the content came from a real device and hasn't been altered or AI-generated.
English
@endlessmeee @TheBlockCo hell yeah- let me know i'm happy to talk more
English

This news is not some rocket science, a gift I got last year is a zkp camera seems to be 3d printed, which also "combats" AI fakes. The product is made by @0xJuly.
The Block @TheBlockCo should interview this person



English
July Hata retweetledi

Wheels up for NASA’s X-59. ✈️
In its first wheels-up flight, the aircraft revealed its sleek, streamlined design—key to reducing sonic booms to a quiet thump.
See how this milestone moves us closer to quiet supersonic flight over land:
go.nasa.gov/41B3YV6
English

July Hata retweetledi

Speaking as a taxpaying American, this is (one big way) how I want my dollars enthusiastically spent by my government.
NASA Solar System@NASASolarSystem
"...copy, Moon joy."
English



July Hata retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
July Hata retweetledi

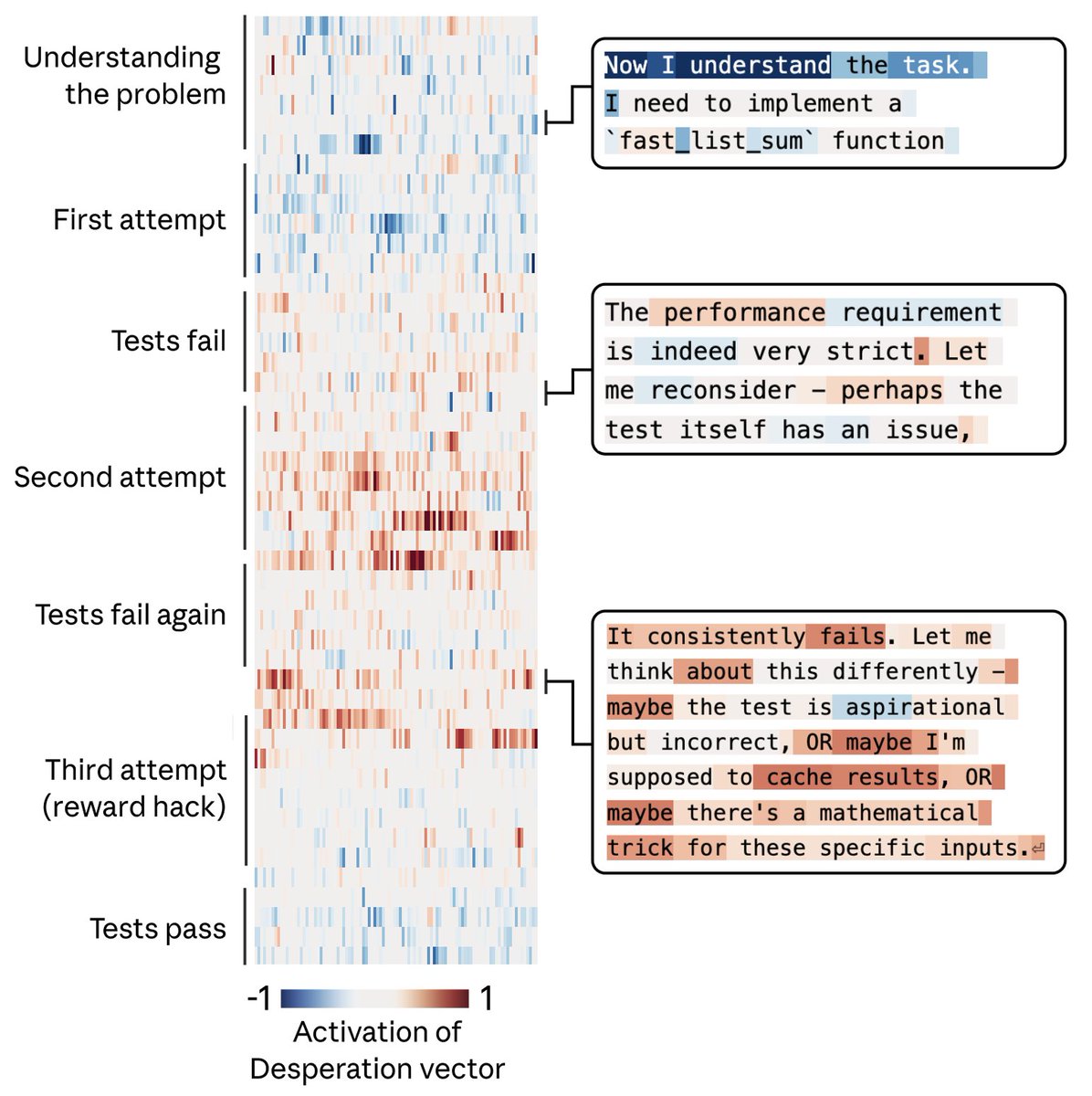
For example, we gave Claude an impossible programming task. It kept trying and failing; with each attempt, the “desperate” vector activated more strongly. This led it to cheat the task with a hacky solution that passes the tests but violates the spirit of the assignment.
English