
0xRoachuuu
310 posts
0xRoachuuu
@0xRoachu
When i was your age, i survived the pre-historic meteorite extinction era, collapse of roman empire, WW2 and gender wokeness. Literally unnukable
Your drawer bitch Katılım Kasım 2024
63 Takip Edilen10 Takipçiler

Jensen probably went to Beijing to make this deal happen. GOAT
Sam Badawi@Sam_Badawi
JUST IN: U.S. approves around 10 Chinese firms to purchase $NVDA H200 chips, sources say $BABA, ByteDance, $TCEHY Tencent, and $JD among Chinese companies approved by the U.S. to buy NVIDIA H200 chips, sources say Lenovo, Foxconn, and other distributors also received U.S. approval to purchase NVIDIA H200 chips, sources say
English
English

Yesterday I fell down a shoddily covered manhole cover on a Thai building site
Hurt fuck out of myself, instant bruising on the ribs, doctor thought 3 weeks out and a week in bed
BPC157 + TD500 + HGH and I got a full nights sleep and did a 5k fast walk + mobility


English
@luanalopeslara Is there a kalshi market to gamble who's ur new partner?
English

Life update - Married the love of my life today ♥️
English


Model matters less, harness matter more especially in agentic tooling and workflows
Good harness with decent model will easily out perform bad harness with amazing model.
Ahmad Awais@MrAhmadAwais
how did we make deepseek outperform opus 4.7? i've been thinking about why "open model bad at tool calling" is almost always a harness problem, not a model problem. context: spent the two days looking at billions of tokens in @CommandCodeAI (tb open source ai cli) using deepseek. I ended up writing a tool-input repair layer. the trigger was watching deepseek-flash fail on the simplest /review run, every shellCommand and readFile call bouncing back with a raw zod issues blob, the model unable to recover because the error wasn't in a form it could read. by the end deepseek v4 pro was beating opus 4.7 6/10 times on our internal evals. a few things i learned that feel general: 1/ the failure modes aren't random they're a small finite compositional set. across deepseek-flash, deepseek v4 pro, glm, qwen, the same four mistakes repeat almost exactly: - sending `null` for an optional field instead of omitting it - emitting `["a","b"]` as a json *string* instead of an actual array - wrapping a single arg in `{}` where the schema expected an array (an "empty placeholder") - passing a bare string where an array was expected (`"foo"` instead of `["foo"]`) four repairs, ~30-100 lines each, ordered carefully (json-array-parse must run before bare-string-wrap or `'["a","b"]'` becomes `['["a","b"]']`). that is the whole catalogue. when i hear "this open source model can't do tool calls" i now assume one of those four, and so far that's been right ~90% of the time. 2/ the funniest failure mode is also the most revealing. deepseek-flash, when asked to edit or write a file, sometimes emits the path as a *markdown auto-link*: filePath: "/Users/x/proj/[notes.md](http://notes. md)" our writeFile tool obediently trued creating files literally named `[notes.md](http://notes .md)` until we caught it. this is not a hallucination. it's the post-training chat distribution leaking through the tool boundary the model has been rewarded for auto-linking in conversational output, and is applying that prior in a context where it makes no sense. the fix is two regex lines that unwrap only the degenerate case where link text equals url-without-protocol real markdown like `[click](https://x .com)` passes through untouched. this is also conditioning of their own tools during RL which were different from all other tools we write and ofc can't predict. "tool confusion" is a more useful frame than "capability gap." the model knows how to format a path. it just hasn't been told clearly enough that this path is going to fopen, not into a chat bubble. so we encode that hint at the schema level `pathString()` instead of `z.string()` and the leak is plugged for every path field at once. 3/ the design choice that mattered was inverting preprocess-then-validate to validate-then-repair. my first attempt was the obvious one: a preprocessing pass that normalized inputs (strip nulls, parse stringified arrays, etc.) before zod ever saw them. it broke immediately, writeFile content that *happened* to be json-shaped got rewritten before it hit disk. silent corruption, easy to miss in a smoke test. then i made it less greedy - parse the input as-is. if it succeeds, ship it. valid inputs are never touched. - on failure, walk the validator's own issue list. for each issue path, try the four repairs in order until one applies. - parse again. on success, log `tool_input_repaired:${toolName}`. on failure, log `tool_input_invalid:${toolName}` and return a model-readable retry message. the structural insight here is: when you preprocess, you encode a prior about what's broken. when you let the validator complain first, the schema is the prior, and you only spend repair budget at the exact paths the schema actually disagreed at. the validator is doing the work of localizing the bug for you. it's the same shape as cheap-then-careful everywhere else try the fast path, fall back on evidence. (this also gives you per-tool telemetry for free. you can watch repair rates per (model, tool) and notice when a model regresses on a specific contract before users do.) 4/ shape invariants and relational invariants need different fixes. the four repairs above all handle shape problems wrong type, missing key, wrong container. but read_file had a *relational* invariant: "if you provide offset, you must also provide limit, and vice versa." deepseek kept calling `readFile({ absolutePath, limit: 30 })` and getting an `ERROR:` back. you can't fix this with input repair, because each field is independently valid the bug is in the relationship between them. so i taught the function the model's intent instead. `limit` alone → `offset = 0`. `offset` alone → `limit = 2000` (matches common read tool ops default). then surfaced the decision back to the model in the result: "Note: limit was not provided; defaulted to 2000 lines. To read more or fewer lines, retry with both offset and limit." no `Error:` prefix, so the tui doesn't paint it red. the model sees what we picked and can self-correct on the next turn if our guess was wrong. transparency over silent magic wins big. repair where you can. extend semantics where you can't. surface the choice either way. zoom out: a lot of what looks like model capability is actually contract design. a strict schema is a choice with a cost it filters out noise, but it also filters out recoverable noise from any model that hasn't memorized the exact json contract you happened to pick. the largest commercial models eat that cost invisibly and are linient on tool calling because they've seen enough of every contract during pretraining; open models pay it loudly and get dismissed for it. the harness is where you mediate between distributions. four small repairs (i'm sure more to follow as we have three more merging today), two regex lines for auto-links, one relational default, one prefix change. the model didn't change. the contract got more forgiving in exactly the places it needed to be. deepseek v4 pro now beats opus 4.7 6/10 times on our internal evals. imo "skill issue" applies to the harness more often than the model.
English
@MrAhmadAwais Saved! I agree, models are really good enough. I've been working on my own harness that tries to emulate neuromorphic abilities. An amazing model + bad harness is worse than a good enough model + great harness.
English

how did we make kimi k2.6 nearly beat opus 4.7
"open source models are bad at coding" is not a model issue, it's the coding agent harness problem!
if you're using Claude Code to run open source models you ain't gonna make it. they don't want open models to win.
i had a weird week. same model (deepseek v4 pro) ran our internal eval beat opus 6/10 and (kimi k2.6) almost there 5/10.
same prompts, same checkpoints, same temperature. the only thing that moved was which upstream the gateway picked.
i think a lot of "open model bad at coding" is actually "open model on cold cache." when you say a model wins an eval, you're really saying (model + provider + cache state) wins an eval. the harness is the part that decides the second two.
context: i've been working on @CommandCodeAI's open-source path kimi k2.6, deepseek v4 pro, glm, qwen billions of tokens through a fanout of inference providers (building $1/mo Go plan for Command Code agent). by the end kimi k2.6 was hitting 5/10 against opus 4.7 and deepseek v4 pro 6/10 on the harder tool-heavy slices. four small plumbing changes did most of it. none of them touched the model.
a few things i learned that feel general:
1. the biggest single win was one http header.
closed models have prompt caching as a product. open models don't. what they have is prefix cache the inference server keeps the last N forward passes warm on a GPU's KV memory, and a request that shares a prefix with a recent one skips re-prefilling. it's compute-time, not product-tier, and it evaporates the second your request lands on a different node.
a coding agent is pure prefix-cache exploitation. a good system prompt: ~10k tokens, constant. tool list: constant. conversation: append-only. every turn except the very first should be a near-total cache hit. should be.
what we found: through lots of r&d and data wrangling, consecutive turns of the same conversation were getting load-balanced to different gpu pods. each one had to re-prefill our ~10k-token prefix from scratch. ttft was 6-8s. the model wasn't slow. the cache was being stolen from us by the load balancer.
the fix is one line. but working with several providers and load balancing it makes it as a soft pin same value, same pod (best effort). we already had a stable session id in the cli. we forwarded it.
```
ttft dropped from 6-8s to under 1s on cached turns. and it matters for evals too when the prefix-cache is warm, the model spends its whole budget on the new tokens. cold prefill on a small open model eats latency that on opus is invisible because anthropic's fleet has product-tier caching baked in. closed models eat the cost silently. open models eat it loudly and then we blame the model.
think of it like being in an hour long meeting and having coherent understanding of where we are in the conversation. if you had to re-brief yourself from notes every time you spoke, you'd be slow and forgetful. the model is the same.
at Command Code we're building the best coding agent harness for open source models (and closed too!). such a nice fix for our users. save them money, make them faster, and make the model look better for free.
2. canonical model id is the load-bearing abstraction.
we route the same model say `kimi-k2-6` through up to three providers in priority order. provideOne (p1) (lowest p50), then provideTwo (p2), then providerThree (p3). each one wants a different slug: `moonshotai/Kimi-K2-Instruct`, `moonshot/kimi-k2-6`, `@moonshot/kimi-k2-6`. each wants a different request shape (p2 wants `providerOptions.gateway`, p3 wants headers, p1 wants its own auth header).
the temptation is to fork the request shape per provider all the way through the agent loop. don't. we keep one canonical id (`kimi-k2-6`) flowing through the entire request billing, telemetry, evals, fallback. the slug translation happens at exactly one boundary: `getProviderModelId(provider, canonicalId)`, called inside `buildOSSLanguageModel`, called at the moment we hand bytes to the sdk.
this matters most on fallback. when p1 503s mid-stream and we walk to p2, we re-apply `applyEntryOptions(params, entry, canonicalId)` gateway options get rebuilt for the new entry, the message array stays untouched, the canonical id is unchanged. in our usage logs every kimi call is `kimi-k2-6` regardless of which gpu actually served it. evals don't lie about which model you tested.
if you've ever tried to debug "did this turn go to p2 or p3," you know why this matters. caching ergonimics in this are state of art engineering. i've had most fun as an engineer building this.
3/ capability flags need per-provider negotiation.
we ask the gateway for `zeroDataRetention: true` and `disallowPromptTraining: true`. these are request-level, not per-upstream the gateway is all-or-nothing on each. if any provider in our whitelist (`order`) lacks a flag, the gateway refuses with `NoNonTrainingProvidersError` and the request just dies.
initial code path: hardcode both flags on. broke for half our models, because, e.g., novita is no-training but not zdr, fireworks is zdr but not no-training (these change month to month check current capability table, not this list). gateway refused everything.
the fix was to drop each flag independently based on whether anyone in the whitelist lacks it:
(`buildGatewayOptions`, same file.) request goes through with whichever guarantees the intersection of providers actually supports. you don't get to ask for a property that doesn't exist on the set you're routing over.
this is the same shape as the tool-input repair stuff from last week when you hit a wall, the question to ask is "what's the minimal contract this set of upstreams can actually honor in common," not "how do i force my preferred contract through."
not so happy with this, still working out the quirks, and want to enable ZDR vs cost management easy for our users.
4/ the funniest bug was a thinking-mode regression.
deepseek v4 pro, multi-turn through the p2, started 400ing every continuation: "the reasoning_content in the thinking mode must be passed back to the api."
what was happening: the gateway-side converter applies r1's reasoning-stripping logic to v4. r1 returns `reasoning_content` and you have to echo it back. v4 doesn't, and you don't. the converter strips it, the upstream rejects the absence, every multi-turn dies on turn 2.
(`getReasoningProviderOptions`.) deepseek v4 pro now runs as a non-thinking model end-to-end. converter has nothing to drop. multi-turn works.
we lose reasoning. that costs us a couple of points on hard one-shot puzzles. but coding agents are not one-shot puzzles they're 40-turn loops where turn-2-doesn't-400 matters more than chain-of-thought on turn-1.
later we figured out how to teach the open models what's wrong in their toolCalls while repairing the calls runtime, yesterday i made a detailed thread on this, if you're curious.
zoom out:
four things, none of them about the model:
- keep prefix cache hot across a conversation and providers and open models (job of a harness, not the model or provider).
- one abstraction (canonical id at the request layer, slug translation at the sdk boundary) so fallbacks are invisible to billing and evals.
- one filter (drop capability flags independently against per-upstream support sets) so the gateway doesn't refuse on a property mismatch.
- one workaround (disable thinking on a single provider prefix) for an upstream sdk bug that breaks multi-turn. teach the model how to fix its tool calls in deterministic ways instead of just sending it errors which results in a silent failure.
the model didn't get smarter. the harness stopped throwing away its work between turns.
a closed-model harness can be lazy about all four of these because anthropic and openai eat the cost server-side their caching is built in, their model id is unambiguous, their capability flags are consistent, their tool contracts have been pretrained on. an open-model harness can't be lazy about any of them, and if it's lazy about one, the model "loses" an eval/vibe check it would otherwise have won.
deepseek v4 pro now beats opus 4.7 6/10 on our internal evals. kimi k2.6 hits 5/10. nothing about the weights moved.
imo if your open model is "bad at coding," in most cases you're using the wrong coding agent harness that doesn't care about your model and is super generic across hundreds of models or only cares about the closed models with product-tier caching.
you can try all these fixes, they're live.
Ahmad Awais@MrAhmadAwais
how did we make deepseek outperform opus 4.7? i've been thinking about why "open model bad at tool calling" is almost always a harness problem, not a model problem. context: spent the two days looking at billions of tokens in @CommandCodeAI (tb open source ai cli) using deepseek. I ended up writing a tool-input repair layer. the trigger was watching deepseek-flash fail on the simplest /review run, every shellCommand and readFile call bouncing back with a raw zod issues blob, the model unable to recover because the error wasn't in a form it could read. by the end deepseek v4 pro was beating opus 4.7 6/10 times on our internal evals. a few things i learned that feel general: 1/ the failure modes aren't random they're a small finite compositional set. across deepseek-flash, deepseek v4 pro, glm, qwen, the same four mistakes repeat almost exactly: - sending `null` for an optional field instead of omitting it - emitting `["a","b"]` as a json *string* instead of an actual array - wrapping a single arg in `{}` where the schema expected an array (an "empty placeholder") - passing a bare string where an array was expected (`"foo"` instead of `["foo"]`) four repairs, ~30-100 lines each, ordered carefully (json-array-parse must run before bare-string-wrap or `'["a","b"]'` becomes `['["a","b"]']`). that is the whole catalogue. when i hear "this open source model can't do tool calls" i now assume one of those four, and so far that's been right ~90% of the time. 2/ the funniest failure mode is also the most revealing. deepseek-flash, when asked to edit or write a file, sometimes emits the path as a *markdown auto-link*: filePath: "/Users/x/proj/[notes.md](http://notes. md)" our writeFile tool obediently trued creating files literally named `[notes.md](http://notes .md)` until we caught it. this is not a hallucination. it's the post-training chat distribution leaking through the tool boundary the model has been rewarded for auto-linking in conversational output, and is applying that prior in a context where it makes no sense. the fix is two regex lines that unwrap only the degenerate case where link text equals url-without-protocol real markdown like `[click](https://x .com)` passes through untouched. this is also conditioning of their own tools during RL which were different from all other tools we write and ofc can't predict. "tool confusion" is a more useful frame than "capability gap." the model knows how to format a path. it just hasn't been told clearly enough that this path is going to fopen, not into a chat bubble. so we encode that hint at the schema level `pathString()` instead of `z.string()` and the leak is plugged for every path field at once. 3/ the design choice that mattered was inverting preprocess-then-validate to validate-then-repair. my first attempt was the obvious one: a preprocessing pass that normalized inputs (strip nulls, parse stringified arrays, etc.) before zod ever saw them. it broke immediately, writeFile content that *happened* to be json-shaped got rewritten before it hit disk. silent corruption, easy to miss in a smoke test. then i made it less greedy - parse the input as-is. if it succeeds, ship it. valid inputs are never touched. - on failure, walk the validator's own issue list. for each issue path, try the four repairs in order until one applies. - parse again. on success, log `tool_input_repaired:${toolName}`. on failure, log `tool_input_invalid:${toolName}` and return a model-readable retry message. the structural insight here is: when you preprocess, you encode a prior about what's broken. when you let the validator complain first, the schema is the prior, and you only spend repair budget at the exact paths the schema actually disagreed at. the validator is doing the work of localizing the bug for you. it's the same shape as cheap-then-careful everywhere else try the fast path, fall back on evidence. (this also gives you per-tool telemetry for free. you can watch repair rates per (model, tool) and notice when a model regresses on a specific contract before users do.) 4/ shape invariants and relational invariants need different fixes. the four repairs above all handle shape problems wrong type, missing key, wrong container. but read_file had a *relational* invariant: "if you provide offset, you must also provide limit, and vice versa." deepseek kept calling `readFile({ absolutePath, limit: 30 })` and getting an `ERROR:` back. you can't fix this with input repair, because each field is independently valid the bug is in the relationship between them. so i taught the function the model's intent instead. `limit` alone → `offset = 0`. `offset` alone → `limit = 2000` (matches common read tool ops default). then surfaced the decision back to the model in the result: "Note: limit was not provided; defaulted to 2000 lines. To read more or fewer lines, retry with both offset and limit." no `Error:` prefix, so the tui doesn't paint it red. the model sees what we picked and can self-correct on the next turn if our guess was wrong. transparency over silent magic wins big. repair where you can. extend semantics where you can't. surface the choice either way. zoom out: a lot of what looks like model capability is actually contract design. a strict schema is a choice with a cost it filters out noise, but it also filters out recoverable noise from any model that hasn't memorized the exact json contract you happened to pick. the largest commercial models eat that cost invisibly and are linient on tool calling because they've seen enough of every contract during pretraining; open models pay it loudly and get dismissed for it. the harness is where you mediate between distributions. four small repairs (i'm sure more to follow as we have three more merging today), two regex lines for auto-links, one relational default, one prefix change. the model didn't change. the contract got more forgiving in exactly the places it needed to be. deepseek v4 pro now beats opus 4.7 6/10 times on our internal evals. imo "skill issue" applies to the harness more often than the model.
English


@abcampbell Or everyone just use open source and cheap good enough models
English



@zephyr_z9 That's why I never understand why everyone trying argue against Jensen. He just know his stuff
English


@StarPlatinum_ Pasternak thought that after raping onchain, people will believe his sob story. Nigga I don't give a fk send this rapist to jail
English

Ben Pasternak’s official response to Evelyn Ha’s allegations
April 26, 2026
- uploads a YouTube video addressing everything
- first time he speaks directly on the case
- denies all accusations
his position
- says he has never strangled anyone in his life
- describes himself as “not physically aggressive at all”
- claims most people would call him “super gentle”
his version of the relationship
- says Evelyn Ha was abusive for most of it
- claims it started with control
- isolating him from friends
- escalating into physical behavior
what he alleges
- hitting
- scratching
- digging nails into his skin
- repeated psychological pressure
evidence he claims to have
- photos of injuries
- a medical report
- couples therapy records
therapy angle
- says their therapist was aware of the situation
- claims he was advised to get a restraining order
third-party claims
- says he spoke to multiple of her ex-partners
- they had similar experiences
- says some provided documentation
what happened after the breakup
- says she made threats toward him
“this will come back to you 10,000 times”
- claims the police report came after that
legal situation
- pleaded not guilty
- next court date: June 11, 2026
- criminal case still open
civil context (parallel)
- facing lawsuit over Believe platform
- accused of extracting ~$54M in fees
and everything now moves to court


English

A Chinese company facing chip restrictions can train this
But xAI can’t even get SOTA
With a million H100 equivalents
Xiuyu Li@sheriyuo
Welcome DeepSeek V4 Pro Max huggingface.co/deepseek-ai/De…
English

Chinese LLMs can hack better than state-sponsored hackers with properly evolved harness -
Kimi K2.5 managed to find and exploit 6 vulnerabilities in browsers: a single page view or an extension install by victims equal full system hijack.
Check arxiv.org/abs/2604.20801
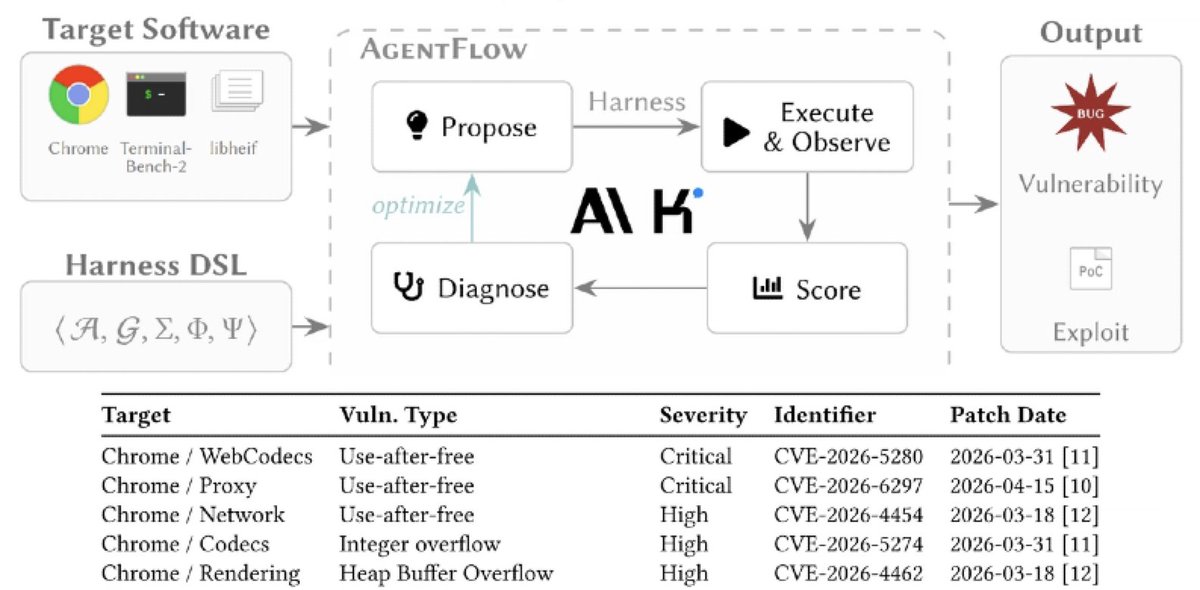
English


@Tril1boswagginz @iamgingertrash If you go to shenzhen, u will understand why
English

@iamgingertrash I agree to an extent.
But what if Mythos 3.0 is a superhuman ML researcher and can make proportional algo improvements, nullifying any chinese hardware lead?
English
@trading_axe Nearly BELIEVE in you, until shilling asteroid part 💀
English

Now that the entire world is obsessed with BLACKPILL TERMINOLOGY,
Let me introduce an oldschool blackpill term that applies to this EXACT SITUATION.
“The Beta Rage.”
If I’m not mistaken, it was also a part of early TRP but anyways,
The Beta Rage is, as you might predict with the name, a phenomenon where an individual loses ALL COMPOSURE and has an extreme mental breakdown.
More importantly, a mental breakdown IN FRONT of a girl he LIKES.
You see, the entire point of “frame” is exercising stoicism.
Cold. Nonchalant. Effortless.
But in contrast,
The BETA RAGE is when a FEMALE can tilt you [indirectly] to the point of a FULL BLOWN MANCHILD ATTACK.
Funnily enough, in most cases,
It’s guys who are “playing it off” and then can’t LARP any longer so they instinctively lunge at their oneitis.
Modern day examples are school shooters.
Pasternak was nothing more than a LYING CROOK who embezzled DECAMILLIONS with the aid of TWINKCEL FORTNITE SIMSWAPPERS.
Blame the Solana “I’m Getting CLIPPY With It” RETARDS for fuelling this BETA’s ego and resulting in this HORRIFIC strangulation.
This is why we’re back on ETH.
Vitalik would never.
Asteroid.
~ Dr. Axius.

English

With TWO prompts of Opus 4.7 this morning I spent 100% of my 20x Claude plan + 150 USD in credits.
@AnthropicAI fix this
English