
Chief Yeti
1.1K posts

Chief Yeti
@0xchiefyeti
Chief Yeti @knightwavegg | Blockchain Gaming Innovatooor | Bringing the action onchain
blockchain Katılım Mart 2021
2.1K Takip Edilen999 Takipçiler

Codex sometimes forgets established processes or patterns in a repo and does the thing I asked for entirely wrong.
Claude sometimes nukes deployed infrastructure then fires off a PR for my mgr to review when we're halfway done with a task
English
@0xSero Yeah I saw the other comment about 35B-3A, I didn't realize cpu offload was so effective w/ MoE. Will report back!
English

Best models to run on your hardware level
I'll be doing this every week, I hope you guys enjoy.
---- 8 GB ----
Autocomplete for coding (like Cursor Tab)
- huggingface.co/NexVeridian/ze…
- huggingface.co/bartowski/zed-…
Tool calling, assistant style
- huggingface.co/nvidia/NVIDIA-…
---- 16 Gb ----
Here things get better:
Multimodal
- huggingface.co/Qwen/Qwen3.5-9B
- huggingface.co/Tesslate/OmniC…
- huggingface.co/unsloth/Qwen3.…
---- 24 GB ----
- The best model you can get (thanks Qwen) huggingface.co/Qwen/Qwen3.5-2…
- Great model (strong agents) huggingface.co/nvidia/Nemotro…
- Mine hehe huggingface.co/0xSero/Qwen-3.…
I'm doing a weekly series
English
@SvenMeyer @0xSero What type of work is handling overnight? I'm running a 3070 8GB, will have to test this out
English

@0xSero Why not qwen3.5-35B-A3B , I have it as q4_K_XL on a mobile , power limited to 45W RTX4070 8GB , offloaded all MoE to CPU RAM and get ~22 tokens/s - quite ok especially for an agent working (over night) in the background.
English
Having the same feelings about Hermes agent that I have with most other coding agents.
It's nice. I'm sure it works great, if I took the time to learn and configure it. It sure is shiny. Tons of features.
But I'm back to pi. pi is simple. pi does what i need and then gets out of the way. I like pi.
English
Local LLM day 5:
autoresearch harness pulling papers & running experiments to get more intelligence out of my compute
but it turns out I need disk space too
English
Chief Yeti retweetledi

I'm usually not one to write thought pieces without much technical depth. But here we go.
Slow the fuck down.
mariozechner.at/posts/2026-03-…
English
Chief Yeti retweetledi

LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
Look at these and read them carefully, this will give you an idea of what you can expect from different Open Weight models.
Qwen3.5-27B is the smartest
Qwen3.5-35B-3A is the fastest
huggingface.co/Qwen/Qwen3.5-2…
huggingface.co/Qwen/Qwen3.5-3…
Any Laptop, Macbook, or GPU should handle em


0xSero@0xSero
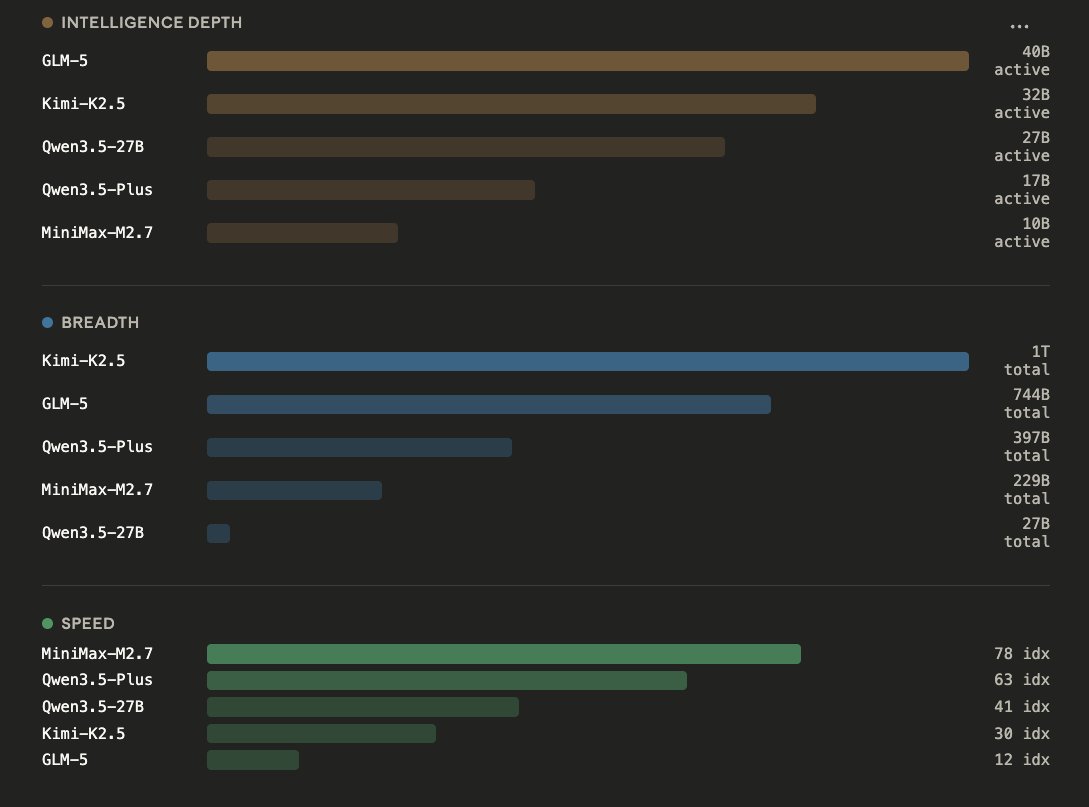
People are not lying when they say Qwen3.5-27B is incredibly capable. 1. Bubble size = total params - World Knowledge, Languages, Skills 2. X axis = active params - Raw Intelligence per token 3. Y axis = tokens/s - Speed of prefill and generation (decode) GLM-5 | 744B params | 40B active Kimi-K2.5 | 1T params | 32B active Qwen3.5-27B | 27B active params Qwen3.5-Plus | 397B params | 17B active MiniMax-M2.7 | 229B params | 10B active MoEs can store much more world knowledge, and breadth of information. For a Mixture-of-Expert, you can stack it up to 1T params, so you can give it 20 Trillion tokens or more of training data, it learns more. But during runtime, only a small portion of that gets activated. Taking MiniMax-M2.5 as an example: Only 10B are active at a time, so while you use it you get the speed and closer intelligence to nemotron-8B it's just MiniMax-M2.5 can know much more, and thus perform better.
English
Sick with the flu all week
Monday is leg day
Wasn't feeling it
Joints ache
Warmups sucked
Adapted. No PR, the whole workout sucked, but got the reps in.
Still sick. Feel good now though. Proud. Satisfied.
Put in the reps.
Have a good day brohs
English
Actually, I think the models need to be smaller.
Let me check if there's a way to squeeze more intelligence out of 8GB VRAM.
English
Local LLM Day 2
Qwen3.5-9B-Q4_K_M.gguf @ 65k context w/ llama.cpp on a 3070 is up to 60 tok/sec after cache quantization
struggling with hiccups in longer runs, seems related to response formatting.
English

we need an efficient system for crowdfunding things like this
kaios@kaiostephens
I’m interested in redo’ing the post training for Qwen3.5:27b/9b specifically for the hermes-agent harness by @NousResearch If anyone is willing to let me use a RTX PRO 6000 or something with >VRAM (even AMD), I would be happy to set this up for the community and share my results on huggingface We need improved agentic intelligence on 16 gb and 24 gb systems.
English
Chief Yeti retweetledi

If you have activity bias, ADHD or anything resembling OCD, OpenClaw is a terrible drug and productivity poison.
After 40 days in the trenches with this thing, my life is measurably worse.
OpenClaw is a lot like crypto trading, gambling or playing video games.
Most ppl are going to lose, and you’re going to feel like shit when you’re done - likely only 1% of ppl will find it additive to their lives.
I am in a constant state of stress. I’m skipping workouts, my vision is fucked from 12-15 hrs a day on screens, my forearms are fucked from too much typing.
There’s a never-ending maze of rabbit holes to fall down, footguns to step on and moles to whack.
Plus when you finally do get it going, you start projects and don’t finish them because half way through something breaks.
I’m not hitting the gym as often as I should, not eating right and I’ve completely lost sight of my goals and why I started in the first place.
The idea of OpenClaw is so compelling and it’s very exciting when I get glimpses of what the future is going to be like when this is not a patchwork of chaos.
This tech is dangerous.
I know I said this last week but I need to take a break … I’m burnt out from all the constant debugging and errors across every fucking surface of this thing.
It’s like trying to fly a plane without a license … oh and it’s on fire…and you’re on crack.
English
Laptop is fine everyone, I'm a dunce and assumed the worst after my nas died a few weeks ago
Still might get that 2nd mortgage
Chief Yeti@0xchiefyeti
Local LLM Day 1 Pointed karpathy's autoresearch framework at optimizing tok/sec Experiment 1: 14->58 Experiment 2: Laptop dies. If I'm lucky it just overheated, but we weren't that hot yet...and I'm not lucky. Getting a second mortgage so I can afford some RAM, I guess...
English
Local LLM Day 1
Pointed karpathy's autoresearch framework at optimizing tok/sec
Experiment 1: 14->58
Experiment 2: Laptop dies.
If I'm lucky it just overheated, but we weren't that hot yet...and I'm not lucky.
Getting a second mortgage so I can afford some RAM, I guess...
Chief Yeti@0xchiefyeti
Local LLM day 1 ~14 tok/sec Qwen3.5-9B-Q4_K_M.gguf @ 32k context w/ llama.cpp on a 3070. great for async/overnight tasks, not ready for primetime
English
Local LLM day 1
~14 tok/sec Qwen3.5-9B-Q4_K_M.gguf @ 32k context w/ llama.cpp on a 3070.
great for async/overnight tasks, not ready for primetime
English

