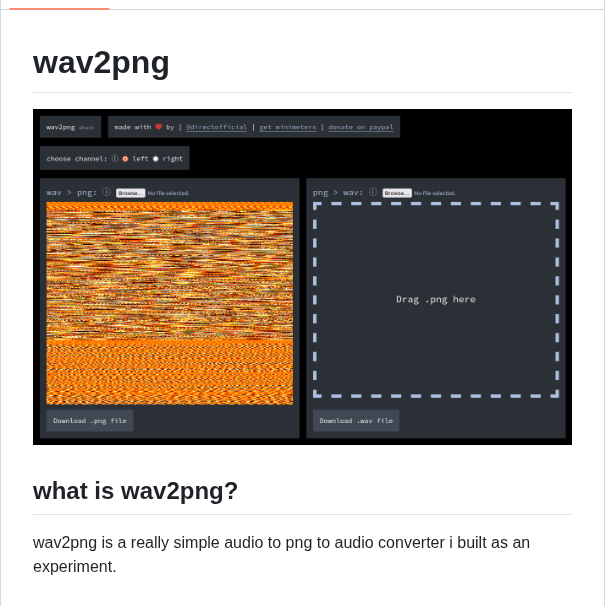
Someone just dropped a markerless motion capture system that works with any camera.. in real time
It uses a 1-billion-parameter AI model to track fingers, face, and body with sub-100ms latency.
100% free to try.
ComfyUI-SegviGen for precise 3D part segmentation.
Auto model downloading (Trellis, SegviGen, BiRefNet, DinoV3). Post-processing (VXZ, Latent Slats, Voxel, GLB).
github.com/Aero-Ex/ComfyU…
Video diffusion models are just overqualified depth estimators!
Deterministic single-pass depth estimation based on WanV2.1.
- SOTA 5.5 AbsRel on ScanNet
- data-efficient than baselines;
- no temporal flicker + infinite-length estimation w/ zero scale drift.
dvd-project.github.io
Alibaba has released an open source framework that's like a mix of OpenClaw + Claude Cowork 🤯
• Long-term memory
• Runs locally with Ollama
• Works with free models like Qwen 3.5
• Self-hosting, skills, and more
Link: github.com/agentscope-ai/…
Do we need to build a Photoshop-like image rotation feature in ComfyUI?
Tried to recreate PS’s image rotation feature inside ComfyUI. The tech itself isn’t anything special — it uses Qwen multi-angle, runs 32 angle variations of the image, then throws them onto a simple Canvas.
The result obviously can’t compete with PS. Theirs clearly uses some kind of 3D technique under the hood.
On top of that, a single run on my local 5090 takes 320 seconds — which is nowhere near an acceptable turnaround time.
Just playing around with it for now. We’ll see if we can improve it later by switching to a 3D-based approach.
Open-sourcing VibeComfy - tools for agents to understand, build, & run ComfyUI workflows.
All the goodness of Comfy through your favourite agent!
Contributions & testers welcome, thanks to @koshimazak for the help so far.
We start 2026 with a bang!
Sparc3D v2.0 is now live on @Scenario_gg
🚨 Geometry-aware PBR texturing, shadow-free albedo, and sharper mesh reconstruction than v1.5...
It's the kind of leap we love seeing, 2026 is going to be a big year for AI 3D.
👉 app.scenario.com/models/model_h…
In fact, when I implemented the ComfyUI native 3D node a year ago, I had already implemented FBX animation loading — that was one of the core features from the very beginning.
At that time, my expectation was that people would download FBX files from Adobe Mixamo and use them in ComfyUI, but it seems people didn’t really use this feature much.
It wasn’t until yesterday when I implemented HY-Motion that everyone started asking me questions about FBX. Fortunately, I had already prepared for this a year ago.
Tencent just released HY-Motion 1.0 on Hugging Face
First billion-parameter DiT for text-to-3D human motion.
Trained on 3,000+ hours with three-stage pipeline.
Covers 200+ motion categories.
Just something for Christmas fun! Convert ComfyUI into 3D space!
It might not have any practical purpose — I know there are plenty of cool commercial products out there. But isn’t this exactly what makes ComfyUI, as an open-source project, so fun?
As long as it’s enjoyable, isn’t that enough? Long live fun, and open source will win!
"Generative Refocusing: Flexible Defocus Control from a Single Image"
TL;DR: two-step process; DeblurNet to recover all-in-focus images from various inputs+BokehNet for controllable bokeh;semi-supervised training.
ComfyUI supports Qwen Image layered on day0, it is cool, then…we need some real layers management to control them, try my previous custom plugin ComfyUI-PolotnoCanvasEditor
#ComfyUI