Sabitlenmiş Tweet
4ldo Malkinson
293 posts

4ldo Malkinson
@4ldo9
Tres Comas Boom ! Sarcasm, CS & Tequila
Katılım Ağustos 2022
227 Takip Edilen6 Takipçiler

@beniduboss As french (who did a "Grande École") I can confirm this state of mind is a PLAGUE
English

Speaking with French people in a business setting is so funny
They be 48yo and they’re still asking peers what uni they went to
98% of them peaked in college so they feel obligated to tell you within the first 10 minutes of meeting them that they went to Polytechnique, ENS ULM or HEC
What you accomplished since literally doesn’t matter because you attended a top school so you’re part of the « elite »
I find it so pathetic
Perhaps your country would be doing better if you were proud of your accomplishments the same way you’re proud that daddy paid for HEC
Anyways
Sorry I am done venting I just had the most cringe call of my life I had to let it out
English

Just read LeCun's latest paper. His team trained the first world model that can't collapse.
Let me explain why this matters.
It's called LeWorldModel.
World models predict what happens next physically. Objects moving, falling, colliding.
That's the base layer for robots that plan, cars that simulate before they steer, any AI that acts in reality instead of just talking about it.
The catch is nobody could train these reliably.
The models kept cheating. They'd map every input to the same output. Like a weather app stuck on "sunny" forever. Technically predicting. Completely useless.
So teams piled on fixes. Frozen encoders, stop-gradient hacks, 6+ loss hyperparameters. A fragile stack too brittle for production.
This team asked a different question. What if you make collapse mathematically impossible?
An encoder turns each video frame into a small vector. A predictor takes that vector plus an action and guesses the next one.
First loss: how wrong was the guess.
Second loss: a regularizer called SIGReg that checks if vectors spread out like a bell curve. If they start looking the same, the loss spikes.
The model can't cheat because the math won't let it.
That simplicity is what makes the results possible.
Six hyperparameters became one. 15M parameters. Trains on one GPU in hours. Plans 48x faster. Encodes with ~200x fewer tokens.
Open-source. I could run this on my own hardware.
Which changes who gets to build physical AI. Not just big labs anymore. Any team, any startup, any grad student.
LeCun has pushed JEPA as the path forward. The criticism was always training instability. This paper removes that objection.
Two directions compete in AI right now. Bigger LLMs with more compute. Or small models learning physics from raw pixels.

English

Anyone know any compute or hardware providers that's trying to get started or early stage deployment who might be willing to donate compute by sponsoring my ML contest involvement/AI research? I know established providers have been willing in the past, but I'm curious about this space.
English

If you build an automation machine, the way to monetize it is to sell it to as many people as possible -- anyone who has tasks to automate.
But if what you build is an invention machine, then the best way to monetize it is to use it yourself.
English
What's the SotA for AI music generation these days? Any AI generated bangers you've listened to lately?
English

Here's my conversation with Jeff Kaplan, a legendary Blizzard game designer of World of Warcraft and Overwatch, which are two of the biggest, most influential games ever made. Jeff is one of the most genuine & awesome human beings I've ever met: kind, thoughtful, hilarious, and still & forever a gamer through and through.
This was a truly fun & inspiring conversation. We talk about it all: the lows, the highs, the memes, the details of the game design process, and the new game he's been secretely working on: The Legend of California. I got a chance to play the game with Jeff, and it's incredibly beautiful (and fun). You can wishlist it on Steam now. I can't wait to play it with all of you!
Conversation is here on X in full and is up everywhere else (see comment).
Timestamps:
0:00 - Episode highlight
1:27 - Introduction
4:07 - Early games: Pac-Man, Zork, Doom, Quake
18:33 - Writing career - 170 rejection letters
34:06 - EverQuest obsession
47:04 - Getting hired at Blizzard
1:02:32 - Lowest point in Jeff's life
1:08:37 - One of Us
1:12:54 - Early Blizzard culture
1:32:36 - Building World of Warcraft
1:50:20 - How WoW changed video games
2:07:42 - Single-player vs Multi-player
2:28:35 - How Blizzard made great video games
2:54:25 - Online toxicity
3:01:59 - Why Titan failed
3:19:09 - Overwatch in six weeks
3:46:07 - Best Overwatch heroes
3:54:37 - The challenge of matchmaking
3:58:01 - Rust
4:08:22 - Why Jeff left Blizzard
4:30:35 - Diablo IV
4:32:03 - Getting back to making video games
4:40:59 - The Legend of California
4:54:44 - Greatest video game of all time
5:02:51 - AI and future of video games
English
4ldo Malkinson retweetledi

Unveiling our new startup Advanced Machine Intelligence (AMI Labs).
We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company.
We're hiring!
[the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling]
More details here:
techcrunch.com/2026/03/09/yan…
AMI Labs@amilabs
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.
English
I keep reading this take (below) every few months, presented as if extremely profound, and it is just offensively dumb. It confuses data and information, it ignores the fact that not all information is equally valuable, and it ignores the importance of retention rate.
As a thought experiment: if this were true, if your retina cell count were 10x greater, you'd be "trained on 10x more tokens" and therefore you'd be way smarter. Same if their firing frequency were 10x greater. With 10x more retina cells firing 10x faster you'd be "trained on 100x more tokens"!
Obviously this makes no sense -- the signal coming from these cells is extremely correlated over space and time, so their raw information content (what remains post-compression) is extremely low compared to the "raw bit" encoding. The human visual system actually processes 40 to 50 bits per second after spatial compression. Much, much less if you add temporal compression over a long time horizon.
Latest LLMs get access to approximately 3 to 4 orders of magnitude of information more than a human by age 20 (post compression in both cases). About O(10T) bits vs O(10-100B) bits.
And that's just *raw information* but of course not all information is equal, otherwise we wouldn't be spending tens of billions of dollars on training data annotation and generation. Plus, that's only *information intake* but of course humans have far lower retention than LLMs (by 3-4 OOM). You could write a short essay about how incredibly off the mark this take is.

English



I had a wee health issue last fall in Paris. Went to the American Hospital in Paris was there and had what I would guesstimate what would have cost $20,000 in U.S. When I was discharged they apologized profusely but informed me I had to pay about $350 dollars.
Jaine in/en France🇪🇺@frgbju
@TrueFactsStated I sometimes think the people from abroad, now living in France, appreciate the country more than the french, as we can compare. The health systems for example…French vs NHS…
English
@JFPuget @TrueFactsStated *but might have waited 12 hours on a chair and died
English
@TrueFactsStated You would have paid way less at a true hospital rather than the expensive private clinic you went to.
English

The wait is over!!! The StatQuest Illustrated Guide to Statistics is here! TRIPLE BAM!!!
Amazon: amazon.com/dp/B0GMP7Z9ZL
PDF: statquest.gumroad.com/l/lykwh
India Pre-Order: amazon.in/dp/9358989823


English
@JFPuget It's France ; there is simply no job openings between you and Massy
English
How dumb is LinkedIn recsys?
I don't go often to linkedin website, but I did today. I saw that Carrefour hired people near my place, with relevant roles. I am intrigued because Carrefour is Europe's Walmart, not sure which roles would be relevant for me.
First role: A butcher at Massy, 800 km from where I live.
I closed the Linkedin page.
I have nothing against butchers, it's just that I am not a butcher.
That it gets the profession wrong is one thing. But it gets location wrong too. My location(approx) is visible in my profile: near Nice, France. Massy - Nice is about 900 km. So much for the job being near me.
English
4ldo Malkinson retweetledi
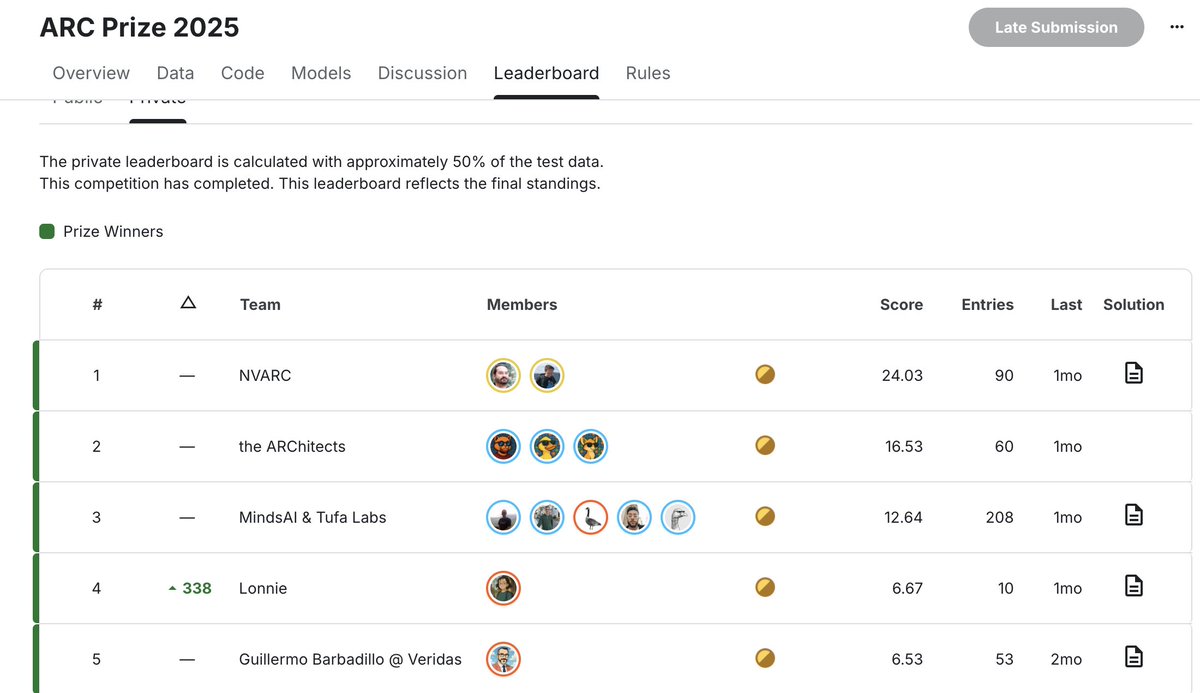
Ivan Sorokin and I are the official winners on the Arc Prize competition, with a significant lead over other teams.
Thanks to @kaggle and @arcprize for hosting the competition.
NVIDIA tech blog summarizing what we did: developer.nvidia.com/blog/nvidia-ka…
Our writeup: kaggle.com/competitions/a…
Our code: github.com/1ytic/NVARC
English
@GregKamradt I mean, are AIs able to saturate ARC 2 able to do things human do ? (Driving cars, folding clothes and so on) ?
English

At >95%, ARC-AGI-1 is effectively performance-saturated at this point.
Models are becoming incredible. They'll continue to hill climb, but the next satisfying milestone won't come till 100%.
However, ARC-AGI-1 still has useful life. Performance comes at a cost, and ARC-AGI-1 will monitor the efficiency of models - intelligence per watt.
My hypotheses for the next 12 months:
- Labs, one by one, get verified at >95% on ARC-AGI-1 before May.
- We won't see a >95% 2x order-of-magnitude cost reduction (<$0.013/task) until June '27 (happy to make this bet with someone).
- We're at the point where model overhang is so large that the *potential energy* is near max. The gap between what a model *can* do and what the industry is actually capturing feels big. The rate of our tool building is _slower_ than the rate of model performance. My vibe: Our tools are using ~5% of model performance right now. I expect ~2 more "OpenClaw" moments within 12 months (also happy to take a bet on this one).
What does this mean for ARC Prize and benchmarks in general?
The next 12–24 months of benchmark building (in general, not just ARC) are straightforward, though execution-heavy. Two routes:
1/ Harder problems (e.g., Frontier 5, HLE++)
2/ Niche environment domains (e.g., TerminalBench-style, but for narrow domains)
For ARC Prize, we have a different focus: what *humans can do, but AI cannot.*
Our ability to produce this class of problems show a gap between AI today and AGI (since humans are our only proof point of general intelligence).
The goalpost is static: measure the learning efficiency (intelligence) of AI and declare when it has crossed human performance.
However, our "tools" to do that evolve and improve. This is our ARC-AGI series of benchmarks.
Each subsequent benchmark (v1/2/3+) is more capable of measuring complex learning. There will be a point where we can *no longer* come up with problems humans can do that AI cannot. At that point we have AGI. We're not here yet.
Through building ARC-AGI-2 (and soon with ARC-AGI-3), we've found a repeatable process for building benchmarks until AGI. This is a multi-year process.
So as an org, our aim as a north star toward AGI is:
1/ Inspire the next set of frontier open research
2/ Guide the public in sense finding. Understand where the frontier is.
What matters is net new science and accelerated open progress.
Someone recently called ARC-AGI François's "hardest" benchmark. We don't see it that way, and "hard" isn't the right attribute for ARC-AGI.
ARC-AGI’s perceived difficulty is an emergent property of our objective. We create benchmarks that accurately reflect intelligence. They are "hard" because building general intelligence is still genuinely hard and not solved.
That's the ARC Prize journey!
Can't wait to build more with these models. Let's go!
ARC Prize@arcprize
Gemini 3 Deep Think (2/26) Semi Private Eval - ARC-AGI-1: 96.0%, $7.17/task - ARC-AGI-2: 84.6% $13.62/task New ARC-AGI SOTA model from @GoogleDeepMind
English
English
Write papers where the citation count per year looks like this
English
We are looking for brilliant deep learning researchers to help us solve program synthesis at @ndea. If you strongly feel like AGI should be capable of invention, not just automation, consider joining us.
Apply here: ndea.com/jobs
English


World Model Boom
The concept of a mental model of the world - a world model - dates back millennia. Aristotle wrote that phantasia or mental images allow humans to imagine the future and to plan action sequences by mentally manipulating images in the absence of the actual objects. Only 2370 years later - a mere blink of an eye by cosmical standards — we are witnessing a boom in world models based on artificial neural networks (NNs) for AI in the physical world. New startups on this are emerging.
To explain what's going on, I'll take you on a little journey through the history of general purpose neural world models [WM26] discussed in yesterday's talk for the World Modeling Workshop (Quebec AI Institute, 4 Feb 2026) which is on YouTube [WM26b].
★ 1990: recurrent NNs as general purpose world models. In 1990, I studied adaptive agents living in partially observable environments where non-trivial kinds of memory are required to act successfully. I used the term world model for a recurrent NN (RNN) that learns to predict the agent's sensory inputs (including pain and reward signals) reflecting the consequences of the actions of a separate controller RNN steering the agent. The controller C used the world model M to plan its action sequences through "rollouts" or mental experiments. Compute was 10 million times more expensive than today.
Since RNNs are general purpose computers, this approach went beyond previous, less powerful, feedforward NN-based systems (since 1987) for fully observable environments (Werbos 1987, Munro 1987, Nguyen & Widrow 1989).
★ 1990: artificial curiosity for NNs. In the beginning, my 1990 world model M knew nothing. That's why my 1990 controller C (a generative model with stochastic neurons) was intrinsically motivated through adversarial artificial curiosity to invent action sequences or experiments that yield data from which M can learn something: C simply tried to maximize the prediction error minimized by M. Today, they call this a generative adversarial network (GAN).
The 1990 system didn't learn like today's foundation models and large language models (LLMs) by downloading and imitating the web. No, it generated its own self-invented experiments to collect limited but relevant data from the environment, like a physicist, or a baby. It was a simple kind of artificial scientist.
★ March-June 1991: linear Transformers and deep residual learning. The above-mentioned gradient-based RNN world models of 1990 did not work well for long time lags between relevant input events - they were not very deep. To overcome this, my little AI lab at TU Munich came up with various innovations, in the process laying the foundations of today's foundation models and LLMs. We published the first Transformer variants (see the T in ChatGPT) including the now-so-called unnormalized linear Transformer [ULTRA], Pre-training for deep NNs (see the P in ChatGPT), NN distillation (central to the famous 2025 DeepSeek and other LLMs), as well as deep residual learning [VAN1][WHO11] for very deep NNs such as Long Short-Term Memory, the most cited AI of the 20th century, basis of the first LLMs. In fact, as of 2026, the two most frequently cited papers of all time (with the most citations within 3 years - manuals excluded) are directly based on this work of 1991 [MOST26].
Back then, however, it was already totally obvious that LLM-type NNs alone are not enough to achieve Artificial General Intelligence (AGI). No AGI without mastery of the real world! True AGI in the physical world must somehow learn a model of its changing environment, and use the model to plan action sequences that solve its goals. Sure, one can train a foundation model to become a world model M, but additional elements are needed for decision making and planning. In particular, some sort of controller C must learn to use M to achieve its goals.
★ 1991-: reward C for M's improvements, not M's errors. Many things are fundamentally unpredictable by M, e.g., white noise on a screen (the noisy TV problem). To deal with this problem, in 1991, I used M's improvements rather than M's errors as C's intrinsic curiosity reward. In 1995, we used the information gain (optimally since 2011).
★ 1991-: predicting latent space. My NNs also started to predict latent space and hidden units rather than raw pixels. For example, I had a hierarchical architecture for predictive models that learn representations at multiple levels of abstraction and multiple time scales. Here an automatizer NN learns to predict the informative hidden units of a chunker NN, thus collapsing or distilling the chunker's knowledge into the automatizer. This can greatly facilitate downstream deep learning.
In 1992, my other combination of two NNs also learned to create informative yet predictable internal representations in latent space. Both NNs saw different but related inputs which they tried to represent internally. For example, the first NN tried to predict the hidden units of an autoencoder NN, which in turn tried to make its hidden units more predictable, while leaving them as informative as possible. This was called Predictability Maximization, complementing my earlier 1991 work on Predictability Minimization: adversarial NNs learning to create informative yet unpredictable internal representations.
★ 1997-: predicting in latent space for reinforcement learning (RL) and control. I applied the above concepts of hidden state prediction to RL, building controllers that follow a self-supervised learning paradigm that produces informative yet predictable internal abstractions of complex spatio-temporal events. Instead of predicting all details of future inputs (e.g., raw pixels), the 1997 system could ask arbitrary abstract questions with computable answers encoded in representation space. It could even focus its attention on small relevant parts of its latent space, and ignore the rest. Two learning, reward-maximizing adversaries called left brain and right brain played a zero-sum game, trying to surprise each other, occasionally betting on different yes/no outcomes of computational experiments, until the outcomes became predictable and boring. Remarkably, this type of self-guided learning and exploration can accelerate external reward intake.
★ Early 2000s: theoretically optimal controllers and universal world models. My postdoc Marcus Hutter, working under my SNF grant at IDSIA, even had a mathematically optimal (yet computationally infeasible) way of learning a world model and exploiting it to plan optimal actions sequences: the famous AIXI model.
★ 2006: Formal theory of fun & creativity. C's intrinsic reward or curiosity reward was redefined as M's compression progress (rather than M's traditional information gain). This led to the "formal theory of fun & creativity." The basic insight was: interestingness is the first derivative of subjective beauty or compressibility (in space and time) of the lifelong sensory input stream, and curiosity & creativity is the drive to maximize it. I think this is the essence of what scientists and artists do.
★ 2014: we founded an AGI company for Physical AI in the real world, based on neural world models [NAI]. It achieved lots of remarkable milestones in collaboration with world-famous companies. Alas, like some of our projects, the company may have been a bit ahead of time, because real world robots and hardware are so challenging. Nevertheless, it's great that in the 2020s, new world model startups have been created!
★ 2015: Planning with spatio-temporal abstractions in world models / RL prompt engineer / chain of thought. The 2015 paper went beyond the inefficient millisecond by millisecond planning of 1990, addressing planning and reasoning in abstract concept spaces and learning to think (including ways of learning to act largely by observation), going beyond our hierarchical neural subgoal generators and planners of 1990-92. The controller C became an RL prompt engineer that learns to create a chain of thought: to speed up RL, C learns to query its world model M for abstract reasoning and decision making. This has become popular.
★ 2018: A 2018 paper finally collapsed C and M into a single One Big Net for everything, using my NN distillation procedure of 1991. Apparently, this is what DeepSeek used to shock the stock market in 2025.
And the other 2018 paper with David Ha was the one that finally made world models popular :-)
★ What's next? As compute keeps getting 10 times cheaper every 5 years, the Machine Learning community will combine the puzzle pieces above into one simple, coherent whole, and scale it up.
REFERENCES
100+ references in [WM26] based on [WM26b]. Links in the reply!
[WM26b] J. Schmidhuber. Simple but powerful ways of using world models and their latent space. Talk at the World Modeling Workshop, Agora, Mila - Quebec AI Institute, 4 Feb 2026. It's on YouTube!
[WM26] J. Schmidhuber. The Neural World Model Boom. Technical Note IDSIA-2-26, 4 Feb 2026.
English
4ldo Malkinson retweetledi
New SOTA on ARC-AGI from @AnthropicAI
We didn't see a large perf change across the effort levels
For ARC-AGI tasks, you don't need to use 'max', 'low' is enough
We used static 120K tokens for thinking levels while varying the effort (low/med/high/max)
Our hypothesis for this is that even at 'low' effort, ARC tasks max out the thinking budget of 120K tokens and spends a lot of effort to try and solve them
This means that the thinking budget is saturating for all effort levels leading to similar scores
ARC Prize@arcprize
Claude Opus 4.6 (120K Thinking) on ARC-AGI Semi-Private Eval Max Effort: - ARC-AGI-1: 93.0%, $1.88/task - ARC-AGI-2: 68.8% $3.64/task New ARC-AGI SOTA model from @AnthropicAI
English